
【徹底比較】Qwen3.6 vs Qwen3.5の違いを徹底分析|長期自律エージェントに求められる性能向上とは
 AIエージェントナビ編集部
AIエージェントナビ編集部
現在のAIエージェント開発において、Claude Opus 4.7 等の高コストなモデルに依存し、予算と安定性の間で頭を抱えるPM(プロジェクトマネージャー)やエンジニアが増えています。本記事では、Qwen3.6とQwen3.5の決定的な違いを技術・コスト・運用効率の観点から解説します。
目次
Qwen3.6 vs Qwen3.5:エージェント運用の「安定性」を左右する技術的進化
AIエージェントのパフォーマンスは、モデルの賢さだけでなく「どれだけ環境の指示を正確に理解し、崩さず実行できるか」という安定性が鍵を握ります。
なぜ3.6への移行でエラー率が下がるのか?XML最適化の重要性
Qwen3.6では、構造化データであるXMLタグの解釈精度が大幅に向上しました。これは、AIエージェントが複雑なタスクを実行する際に、ツール利用やファイル操作の命令を誤解なく処理できることを意味します。特に長文のリポジトリ構造を読み込む際、XMLタグの階層を正確に維持できるため、予期せぬ構文エラー(シンタックスエラー)が劇的に減少します。
推論速度を劇的に高める「DeltaNet(デルタネット)」と「Thinking Preservation(思考の保存)」の仕組み
Qwen3.6には、以下の革新的な技術が投入されています。
- Gated DeltaNet(ゲート付きデルタネット): KVキャッシュ(生成された回答のキーと値を保持するメモリ)を最適化し、長文生成時のメモリ消費を抑えつつ推論速度を向上させる技術です。
- Thinking Preservation(思考の保存): AIが回答を導き出すまでの「思考プロセス」をキャッシュします。これにより、マルチステップ・タスクにおいて、一度考えた論理構造を再利用できるため、同じ質問や関連作業におけるレスポンスが高速化します。
コンテキスト1M(記憶容量100万トークン)が実現する大規模リポジトリの全容把握
Qwen3.6は100万トークンという巨大なコンテキスト(記憶容量)に対応しました。これにより、数万行規模のコードベースを一度に読み込み、全体を俯瞰したリファクタリング(プログラムの内部構造を整理すること)やデバッグを、外部記憶に頼ることなくモデル単体で完結させることが可能になりました。
関連記事:【徹底比較】Qwen3.6はClaudeを超えるか?ビジネス導入の判断基準と適材適所の活用戦略
実務で差が出る!AIエージェントの業務活用におけるQwen3.6の強み
実務環境でエージェントを回す際、Qwen3.6は「作業の断絶」を防ぐ強力な武器になります。
マルチステップ・タスクのオーバーヘッドを削減する「思考の保存」の効果
従来のモデルでは、複雑なタスクを分断して依頼するたびにAIはゼロから推論を行う必要がありました。Qwen3.6の「思考の保存」機能により、AIは直前の推論状況を維持したまま次の工程へ移行できます。これにより、タスク完了までのステップ数が長い業務においても、一貫性が損なわれず、計算リソースの無駄を省くことが可能です。
Claude Codeユーザー必見!外部ツール連携時の整合性とVQA(視覚質問応答)の精度向上
Qwen3.6は視覚情報の処理能力が強化されており、エージェントが実行結果のスクリーンショットやUIデザインを解析する際の精度が向上しました。特にフロントエンド開発においては、視覚的な崩れを指摘するVQA機能が、Claude Codeなどのエージェント環境と非常に相性が良く、自動テストの成功率を高めます。
プロトタイプ開発(3.5)と長期自律運用(3.6)の賢い使い分け方
運用フェーズに応じた使い分けを推奨します。
- Qwen3.5: 新機能の素早い検証や、コードの断片的な作成を行うプロトタイプ(試作)環境に最適です。
- Qwen3.6: 24時間稼働させる監視エージェントや、数日間にわたる長期プロジェクトの自律実行に適しています。
関連記事:AIエージェントおすすめ10選|無料で試せる順に個人・法人別で比較
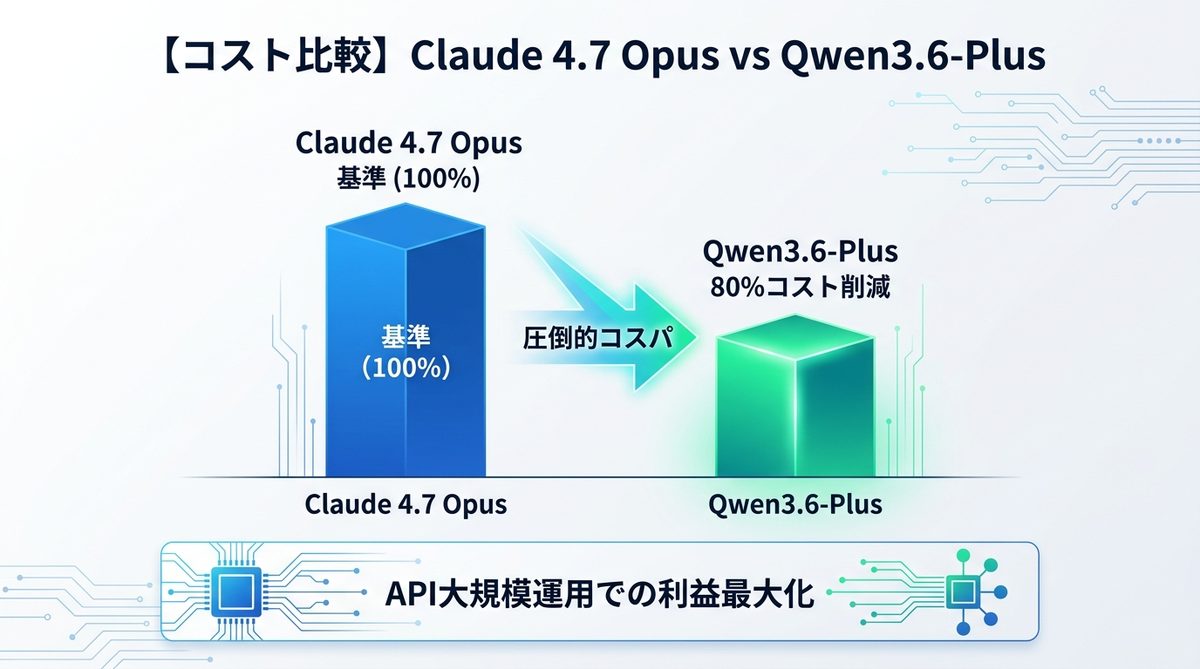
【コスト比較】Claude Opus 4.7と比較してどれほど安くなるのか?
経営視点で最も重要なのは、AIの運用コストと成果のバランスです。
100万トークンあたりの単価シミュレーション:最大80%のコスト削減を算出
Qwen3.6(Plusモデル)は、Claude Opus 4.7と比較してトークン単価が大幅に抑えられています。以下は推計コストの比較表です。
| モデル名 | 100万トークン単価(推計) | 運用上のメリット |
|---|---|---|
| Claude Opus 4.7 | 基準(100%) | 最高精度だが高コスト |
| Qwen3.6-Plus | 約20% | 80%のコストカットを実現 |
API利用時の「コスパの最適化」を経営視点で考える
APIを介したエージェント運用を大規模化するほど、単価の差は利益に直結します。月間で数億トークンを消費するような業務において、Qwen3.6への移行は単純計算で数万ドル規模のコスト削減が見込めます。
小規模開発や実験段階における3.5の変わらぬ価値と限界点
3.5は依然としてバランスに優れたモデルですが、非常に複雑な論理推論が必要な局面では、3.6の圧倒的な思考キャパシティがボトルネックを解消する唯一の解となります。
関連記事:【徹底比較】Qwen3.6 vs Claude 4.6|APIコストを激減させる業務活用ポートフォリオの作り方
ローカルAI環境の革命|Qwen3.6-35B-A3Bの性能と実運用ガイド
クラウドだけでなく、手元のPCでもQwen3.6の性能を活かすことができます。
M4/M5 Macでリアルタイム推論は可能か?MoE(専門家混合)モデルの凄み
「35B-A3B」モデルは、MoE(専門家混合:特定のタスクごとに専門の回路を呼び出す技術)を採用しています。これにより、モデル全体としては35B相当の能力を持ちながら、アクティブ(実際に動く)なパラメータを3Bに絞ることで、Apple Silicon(M4/M5 Mac)環境でも非常に高速な推論が可能です。
ローカル環境へ導入すべきエンジニアの条件とセットアップのポイント
ローカル運用が推奨される条件は以下の3点です。
- 機密データを含むコードを扱うため、外部へ情報を出せない。
- クラウドのネットワーク遅延を避け、ミリ秒単位のレスポンスを求める。
- 独自の微調整(ファインチューニング)を頻繁に行いたい。
オープンウェイト版とAPI版の選び方:プロジェクトの規模とセキュリティ要件
セキュリティやレイテンシ(通信遅延)が厳しい要件がある場合は「35B-A3B」のローカル運用を、機能の網羅性と最大性能が必要な場合は「Max-Preview」をAPIで利用するのが鉄則です。
関連記事:【2026年版】ローカル生成AIの始め方|PCスペック判定表とおすすめソフト徹底解説
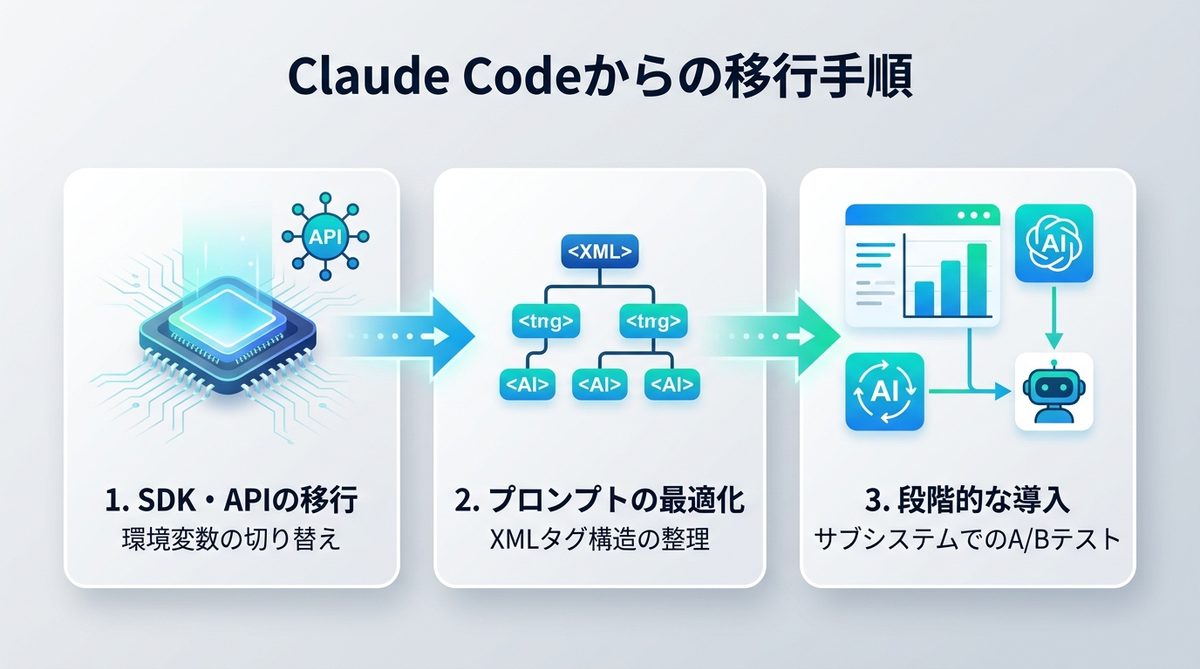
Claude Code環境からの乗り換え手順と注意点
移行をスムーズに進めるための3つのステップを紹介します。
1. SDKの互換性とAPI移行時に必要なコードの微調整
QwenはOpenAI互換のAPIを提供しているため、既存のClaude SDKから環境変数の切り替えだけで接続可能です。ただし、ストリーミング処理の微細な調整が必要な場合があります。
2. 既存のプロンプト資産を3.6で最大限活かすためのXML構成のコツ
3.6はXMLタグを深く理解するため、既存のプロンプト内のタグ構造を整理してください。タグの入れ子(ネスト)が複雑すぎる場合は、整理するだけで回答の安定性が向上します。
3. AIエージェントチームのパフォーマンスを最大化する導入ステップ
まずは特定のサブシステム(例えばテスト自動化エージェント)のみをQwen3.6へ入れ替え、他のエージェントと性能を比較する「A/Bテスト」から始めてください。
関連記事:【性能比較】AIエージェントの力を測る「ベンチマーク」とは?種類と活用法
まとめ
Qwen3.6は単なるスペック向上ではなく、自律エージェントの運用を「実験」から「実務」へ変えるための基盤です。今回のポイントは以下の通りです。
- 安定性の向上: XMLタグ最適化と巨大コンテキスト(1M)により、長時間のタスクでも破綻しない。
- 高いコスト効率: Claude Opusと比較して最大80%のコスト削減を実現可能。
- ローカルとクラウドの融合: 35B-A3Bモデルで、セキュアかつ高速なオフライン推論ができる。
まずはAlibaba Cloud Model Studioでテストを行い、その精度の高さを実感してください。今すぐ自社のエージェント開発環境を次世代モデルへアップグレードしましょう。


