
Nemotron 3 Superの使い方|ローカル構築とコスト最適化術
 AIエージェントナビ編集部
AIエージェントナビ編集部
社内でAIエージェントを構築したいと考えていても、クラウドのAPI料金が膨らむことや、社外へデータを送信するセキュリティ上の懸念が障壁となっていないでしょうか。Nemotron 3 Superを活用すれば、プライベート環境で高度な推論を実行しつつ、運用コストを大幅に抑制することが可能です。
本記事では、ローカル環境での構築手順から、推論モードの細かな制御、そしてClaudeとの役割分担による実戦的なエージェント構築までを網羅的に解説します。
この記事に対する編集部の見解
- ローカルモデルはAPIコストが消えるが、更新・保守・GPU運用の人件費が別途発生する
- 「APIコストがゼロ」は正確だが「全体コストが下がる」かどうかはケースバイケース
- モデルの進化が速い今、半年後のバージョンに追従できるかも導入判断の重要な軸になる
目次
Nemotron 3 Superを選ぶべき理由
AIエージェントの構築において、モデルの選択は「コスト」と「精度」のトレードオフを決定づけます。Nemotron 3 Superは、ローカルでの実行可能性と、複雑な推論能力を両立している点が最大の特徴です。
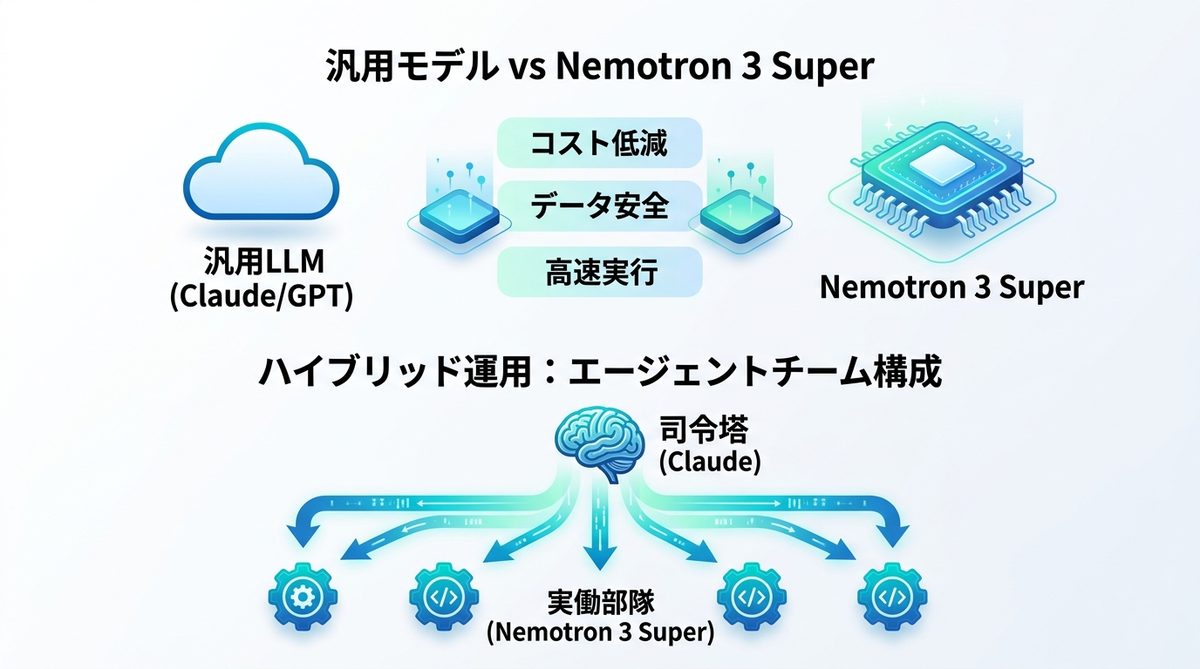
汎用モデルとの違い
クラウド型の汎用モデルは非常に強力ですが、全てのタスクで最高スペックのモデルを使うとAPIコストが増大します。Nemotron 3 Superは以下の観点で優れています。
| 比較軸 | 汎用LLM(Claude/GPT) | Nemotron 3 Super |
|---|---|---|
| 推論コスト | 従量課金制(高) | インフラ固定費(低) |
| データ管理 | 外部サーバー経由 | ローカル/オンプレミス完結 |
| 思考の深さ | 非常に深い | 調整可能 |
| 実行速度 | ネットワーク依存 | ハードウェア性能依存 |
Claudeとの役割分担
すべてを1つのモデルでこなそうとせず、得意分野に集中させる「エージェントチーム構成」が内製化の成功法則です。
- 司令塔(Claude): 全体設計、複雑なアーキテクチャの意思決定、ユーザー対応。
- 実働部隊(Nemotron 3 Super): 定型的なコード生成、大量のログ解析、エラーの修正、データ整形。
Claudeで設計図を描き、その実行指示をローカルのNemotronに投げることで、APIコストを抑えつつ高速な開発フローが実現できます。
関連記事:【エンジニア必見】Claude Code local llm活用のリスクと成功法則|APIを補完する「適材適所」な開発ワークフローとは
Ollamaによる環境構築と最適化
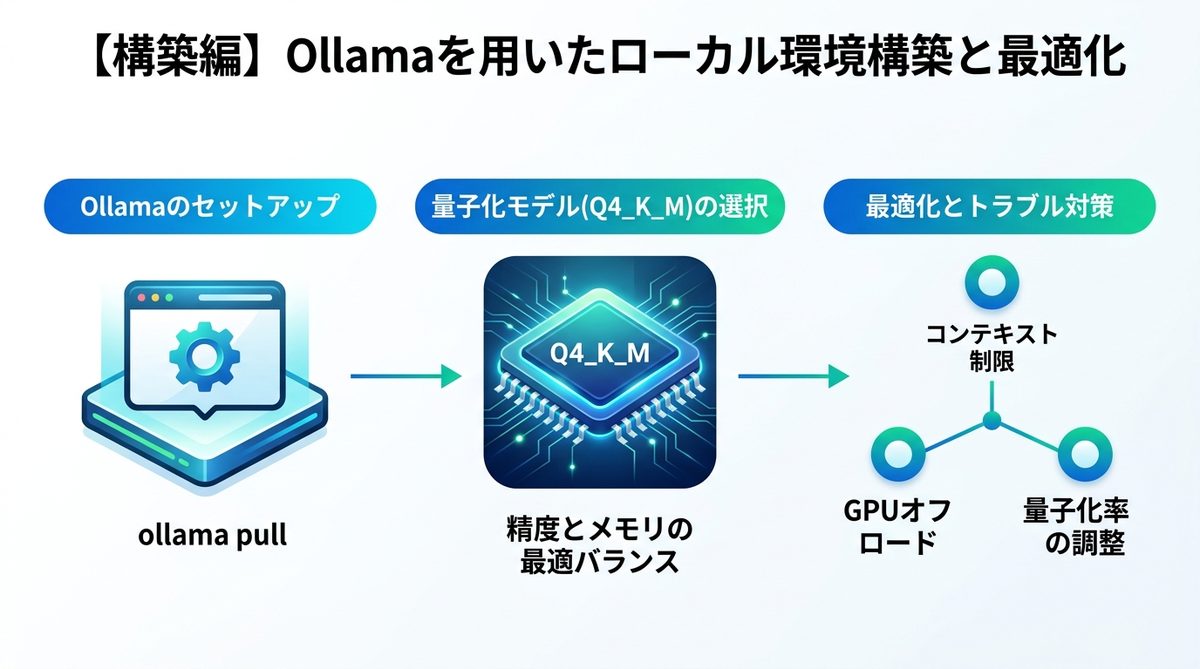
専門的な知識がなくても、Ollama(AIモデル実行ツール)を使えば短時間でローカル環境を構築できます。
セットアップとQ4_K_Mの選び方
まずは公式サイトからOllamaをインストールし、以下のコマンドを実行するだけでNemotron 3 Superが準備できます。
# モデルのプル(ダウンロード) ollama pull nemotron-3-super:q4_k_m
量子化モデル「Q4_K_M」を推奨する理由は、精度とメモリ消費のバランスが最適だからです。フルスペックのモデルと比較して推論精度を大きく損なわずに、VRAM使用量を約60%削減可能です。
ハードウェア要件と対策
ローカル実行における最大の障壁はGPUメモリ(VRAM)の不足です。以下の対策を講じてください。
- コンテキスト(記憶容量)の制限: 入力トークンが長すぎるとメモリを圧迫します。
--num-ctxオプションで数値を控えめに設定してください。 - オフロード設定: GPUの容量が足りない場合、システム設定で「GPUオフロード」のレイヤー数を調整し、CPUと併用することでクラッシュを防げます。
- 量子化率の引き下げ: もしQ4でもメモリが不足する場合は、Q3_K_Mなどのさらに軽量なモデルを試してください。
関連記事:【2026年最新】ローカルAIエージェントの作り方|Ollama×Open WebUIで完全オフライン構築
enable_thinkingによる推論制御
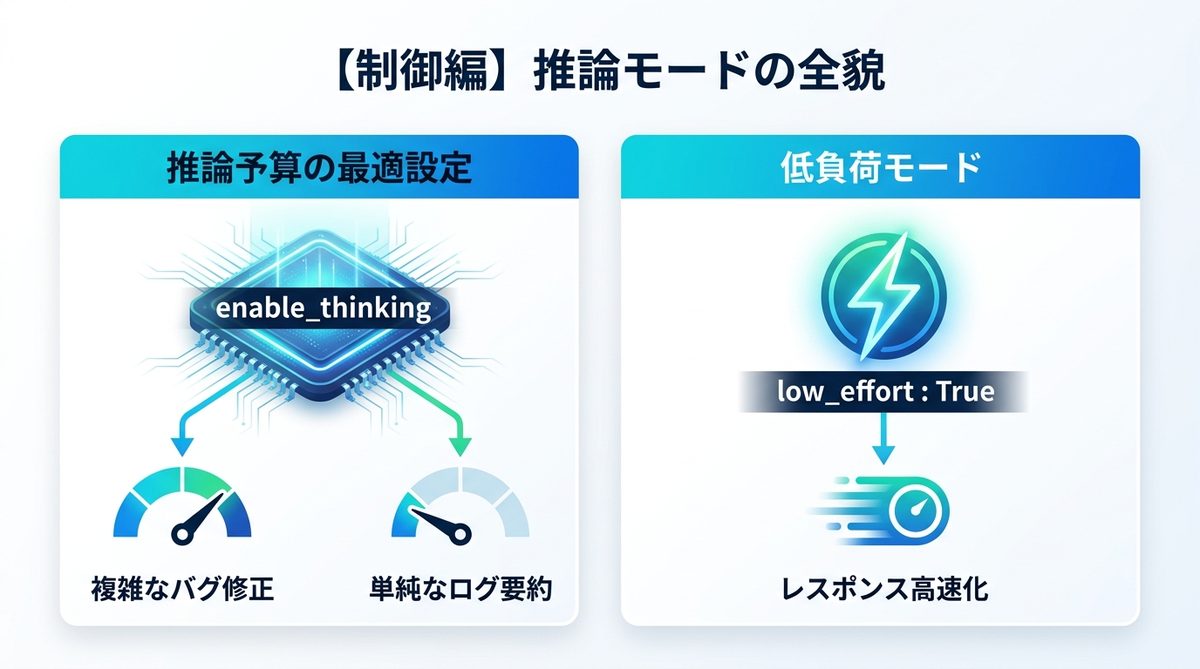
Nemotron 3 Superは「思考プロセス」を明示的に制御することで、タスクの難易度に応じたコスト・速度調整が可能です。
推論予算の最適設定
enable_thinking パラメータを有効にすると、モデルは回答の前に思考を行います。この思考の深さを reasoning_budget で指定します。
# API経由での推論制御例 response = client.chat.completions.create( model="nemotron-3-super", messages=[...], enable_thinking=True, reasoning_budget=1024 # 思考の深さを制限 )
- 複雑なバグ修正:
reasoning_budgetを高めに設定し、論理の飛躍を防ぎます。 - 単純なログ要約: 数値を下げ、応答時間を優先させます。
低負荷モードによる高速化
特定のタスクには low_effort: True モードを使用します。これにより、モデルは冗長な思考をスキップし、最小限の計算リソースで回答を生成します。コーディングの補助など、ある程度の正当性が担保された作業に最適です。
関連記事:Claude Codeのモデルと思考深度の設定術|開発スピードとAPIコストを最適化する実践手法
主要フレームワークへの組み込み
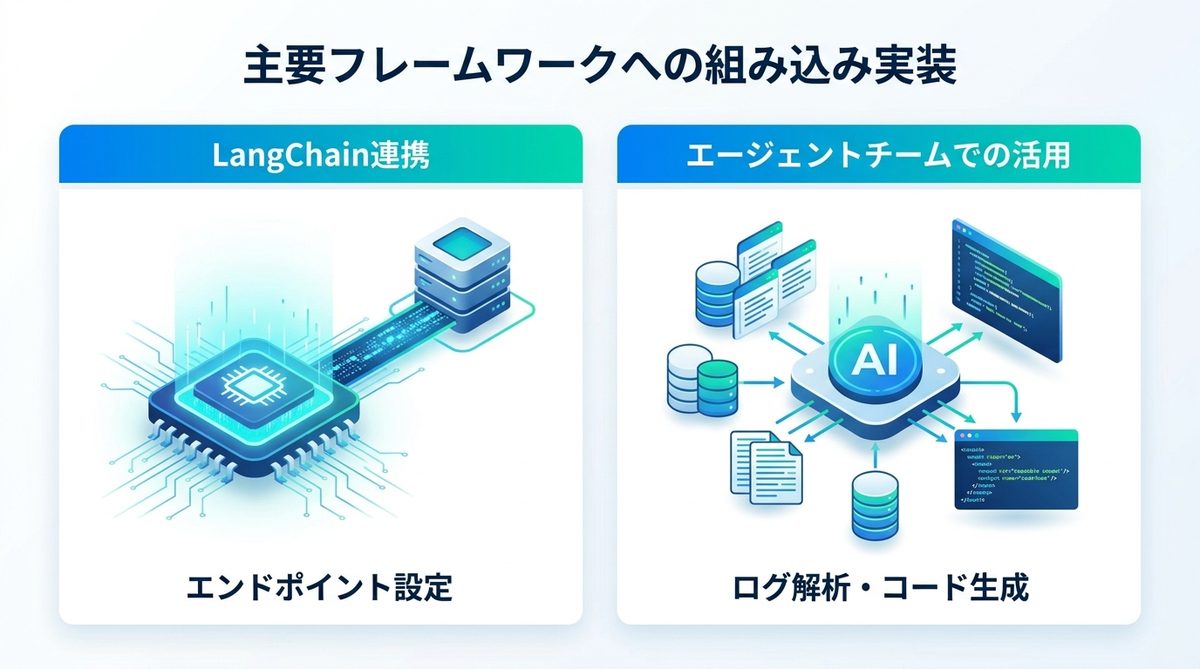
既存のAIエージェント開発環境にNemotronを統合するのは非常に簡単です。
バックエンドと設定方法
LangChainを利用している場合、ベースURLをOllamaのローカルエンドポイントに向けるだけです。
from langchain_openai import ChatOpenAI llm = ChatOpenAI( model="nemotron-3-super", openai_api_base="http://localhost:11434/v1", openai_api_key="none" )
ログ解析・ツール利用例
実戦では、以下のようなプロンプトテンプレートを用意しておくと効率的です。
「あなたはエージェントチームの解析担当です。以下のログファイルの内容を精査し、例外エラーの原因を特定してください。その後、修正のためのコード案を提示してください。」
このように役割を明確化し、Nemotronにタスクを振ることで、エンジニアは設計に集中できるようになります。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
AIエージェントの未来
組織の内製化と費用対効果
クラウドAPIを利用し続けた場合と比較して、OSSモデルを活用した内製化は、運用期間が長くなるほどコスト回収率が高まります。特に24時間稼働させる監視エージェントや、大量の非公開ドキュメントを読み込ませるエージェントにおいて、その経済的優位性は顕著です。
最新動向と今後の展望
2026年5月現在、OSSコミュニティでは推論精度を保ったまま実行時間をさらに短縮する「蒸留技術」が進化しています。今後、Nemotron 3 Superはさらにエッジデバイスに近い環境でも動作するようになり、PCの中に「常駐する優秀な副操縦士」が住み着いた状態が当たり前になるでしょう。
関連記事:【2026年最新】Mamba-3とは?Transformerを超える「推論効率」の仕組みを解説
まとめ
Nemotron 3 Superを活用したAIエージェント内製化の要点は以下の通りです。
- 役割分担が鍵: Claudeを「司令塔」、Nemotronを「実働部隊」として組み合わせるのが最強の構成です。
- 環境構築: Ollamaを活用し、量子化モデル(Q4_K_M)でVRAM使用量を抑えるのが初心者にとっての最短ルートです。
- 推論制御:
enable_thinkingとreasoning_budgetを調整し、タスクの難易度に応じて回答精度と実行速度を最適化しましょう。 - コストメリット: ローカルでの実行により、クラウドAPI利用料を抑えた永続的なエージェント運用が可能になります。
まずは手元のPCでOllamaを起動し、簡単なログ解析タスクからNemotronを動かしてみてください。内製化への第一歩を今すぐ踏み出しましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- ローカルモデルはAPIコストが消えるが、更新・保守・GPU運用の人件費が別途発生する
- 「APIコストがゼロ」は正確だが「全体コストが下がる」かどうかはケースバイケース
- モデルの進化が速い今、半年後のバージョンに追従できるかも導入判断の重要な軸になる
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


