
【DX担当者必見】そのPDF、AIは読めていますか?MinerUで実現する高精度ナレッジベース構築術
 AIエージェントナビ編集部
AIエージェントナビ編集部
「社内の膨大なPDF資料をAIに読み込ませたのに、肝心な表や数式を読み飛ばされて的外れな回答しか返ってこない」。そんな悩みを抱えていませんか?実は、その原因の多くはAIの頭の良さではなく、入力データの「品質」にあります。
本記事では、AIの読み取り精度を劇的に改善するOSS(オープンソースソフトウェア)「MinerU(マイナーユー)」の活用法と、ビジネス現場での導入戦略を解説します。
目次
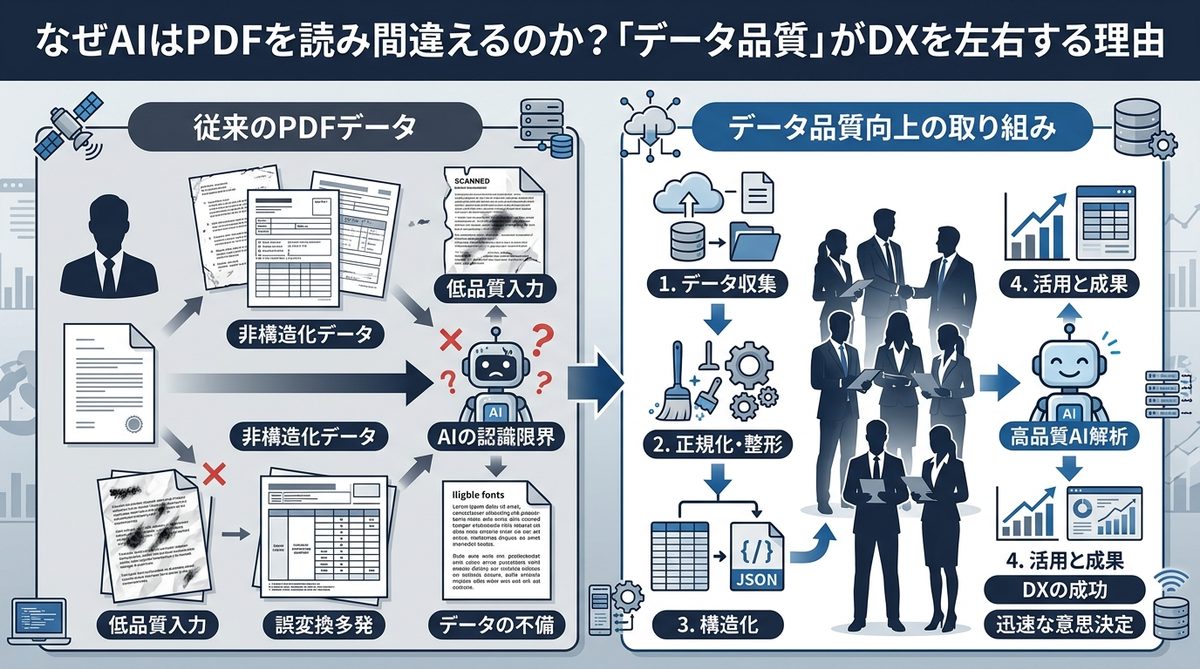
なぜAIはPDFを読み間違えるのか?「データ品質」がDXを左右する理由
AI活用の現場でよく見られる「回答の精度不足」は、データの前処理不足によって引き起こされる典型的な課題です。
LLM(大規模言語モデル)が理解できない「見た目だけのデータ」の罠
PDFは人間が目で見るために最適化されたファイル形式であり、実は「構造」が隠蔽されています。例えば、PDF内の表はAIにとってただの「スペースで区切られた文字の羅列」に見えることが多く、セル同士の関係性が正しく認識されません。数式や複雑なレイアウトに至っては、文字化けや順序の入れ替わりが頻発し、AIは文脈を理解する以前に、誤った情報を読み込んでしまうのです。
RAG(検索拡張生成)の回答精度を決定づける「前処理」の重要性
AIの世界には「Garbage In, Garbage Out(ゴミを入れたらゴミが出てくる)」という言葉があります。社内文書をAIに検索させるRAGの仕組みにおいて、元のPDFが汚いデータであれば、いくら高性能なモデルを使っても精度の高い回答は期待できません。AIが正しく判断を下すためには、PDFを「AIが理解しやすい形式(Markdown形式やJSON形式)」に変換するという、丁寧な前処理が不可欠なのです。
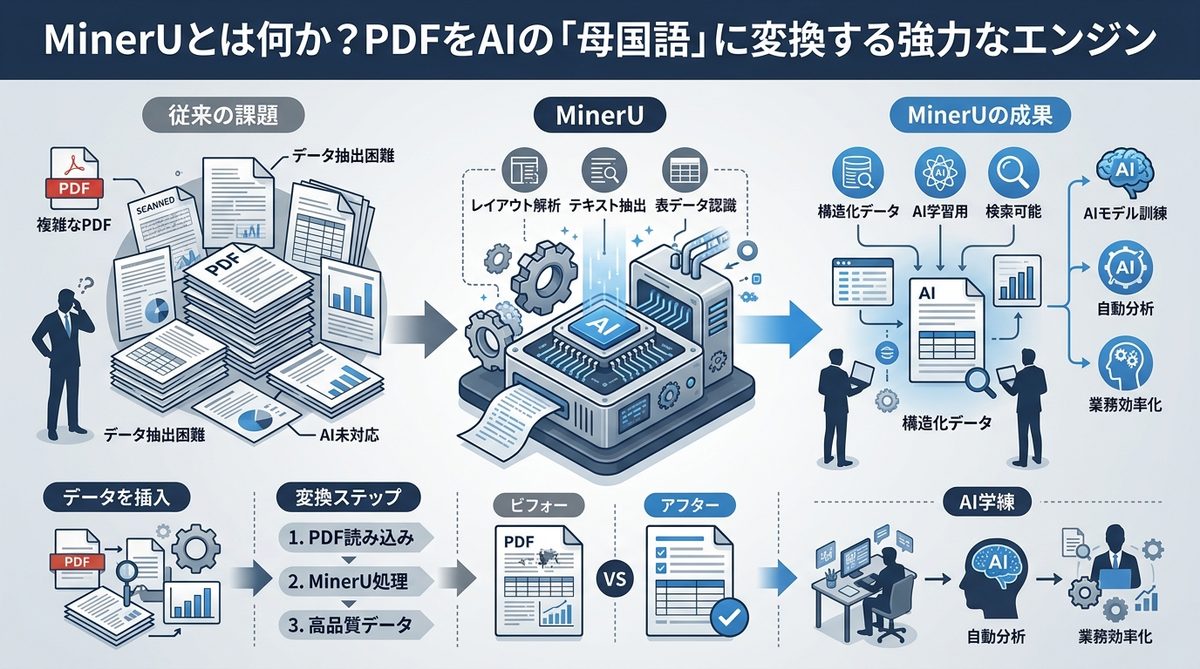
MinerUとは何か?PDFをAIの「母国語」に変換する強力なエンジン
MinerUは、上海AIラボが開発した「Magic-PDF」というエンジンを核とする、ドキュメント解析の救世主です。
OCR(光学文字認識)の限界を突破する「構造理解」というアプローチ
従来のOCRは「画像から文字を抜き出す」ことに特化していましたが、MinerUは一歩進んで「ドキュメントの構造を理解」します。見出し、段落、リスト、表、さらには数式といった要素を論理的な階層として捉え、AIにとって最も扱いやすいMarkdown(マークダウン)という形式に変換します。これにより、AIは「表のどの値がどの項目に対応しているか」を正確に把握できるようになります。
Magic-PDFが支える高精度解析の技術的背景
MinerUの心臓部であるMagic-PDFは、複雑なレイアウト構造の保持能力に非常に優れています。具体的には以下の情報を維持したまま変換が可能です。
- 表形式の維持:セルの結合や複雑な階層構造を正確に抽出
- 数式の認識:LaTeX(ラテックス)形式等への変換による論理的構造の保持
- 読み取り順序の最適化:複数段組みの文章でも、人間が読む自然な順序でテキストを抽出
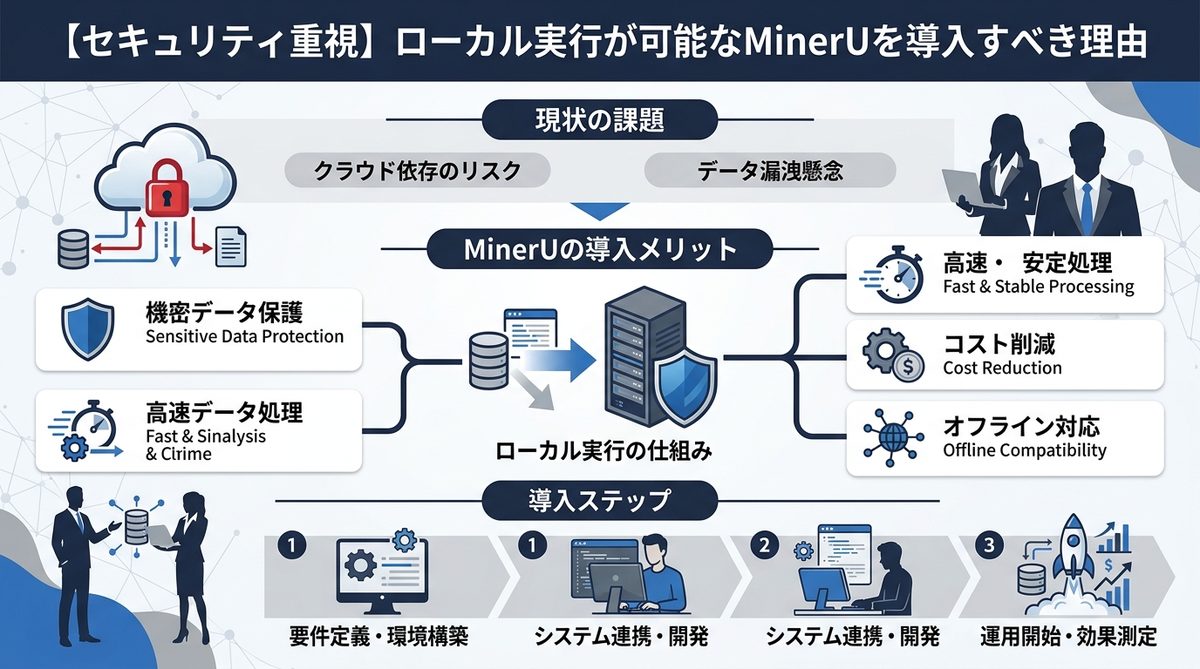
【セキュリティ重視】ローカル実行が可能なMinerUを導入すべき理由
企業がAI活用を躊躇する最大の懸念は「機密情報の漏洩」ですが、MinerUはその課題を根本から解消します。
機密データを外部に漏らさない「ローカル実行」の優位性
多くのAI変換サービスはクラウド上で処理を行いますが、MinerUは社内のローカル環境(Docker環境など)にインストールして動かすことが可能です。つまり、外部のサーバーに社外秘の契約書や未公開の技術報告書を送信する必要が一切ありません。情報セキュリティ基準が厳しい大企業でも、安心して導入できる仕組みとなっています。
既存ツールとの比較:MinerUが選ばれる理由
| 比較項目 | 従来のOCRツール | 一般的なAI変換API | MinerU (Magic-PDF) |
|---|---|---|---|
| 構造認識 | 弱い(文字のみ) | 中程度 | 非常に高い |
| セキュリティ | 安全 | 注意が必要(外部送信) | 非常に安全(ローカル実行) |
| 運用コスト | 低 | 高(API課金) | 低(OSS・自社ホスティング) |
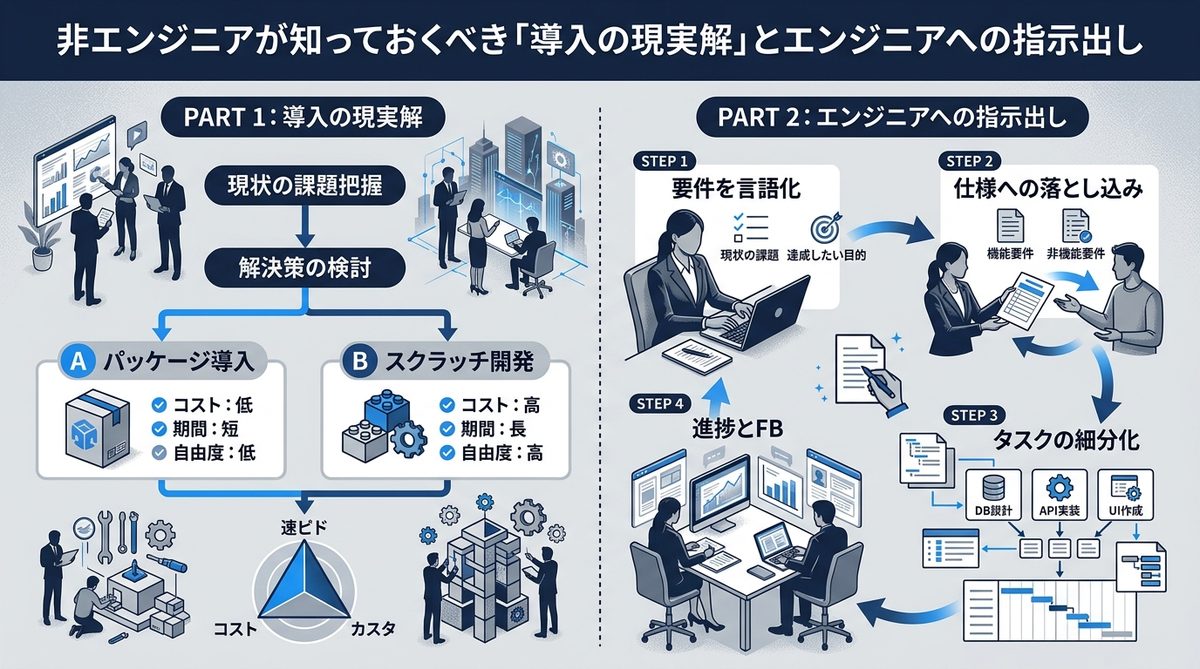
非エンジニアが知っておくべき「導入の現実解」とエンジニアへの指示出し
技術者でなくても、MinerUを業務プロセスに組み込むための「司令塔」になることは十分に可能です。
エンジニアに依頼すべき構築作業と、現場ができるデータ運用
非エンジニアのDX担当者が行うべきは、環境構築のディレクションです。社内のエンジニアや外部ベンダーに対し、「PDFをローカル環境でMarkdown化し、構造を維持したままRAGへ渡したい」と指示を出しましょう。具体的にはDocker環境の構築を依頼すれば、あとは変換されたMarkdownファイルをDify(AIアプリ開発ツール)等にアップロードするだけで、AIの回答精度が劇的に向上します。
Difyを活用したナレッジベース構築へのステップ
- 準備:社内のPDFをMinerUでMarkdown変換する
- 連携:Difyの「ナレッジ」機能へMarkdownファイルをインポートする
- 調整:AIが読み込んだ構造情報を元に、プロンプト(AIへの指示)を最適化する
- 運用:構造化されたデータで、より精度の高い回答を得る
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
AIエージェント時代に必要な「データマネジメント」の意識改革
AIを使いこなす組織とは、AIが学習しやすいデータを整備する文化を持つ組織のことです。
AIにゴミを入れないために組織ができること
これからのビジネスパーソンには、書類作成の段階から「AIが読み取りやすいレイアウト」を意識することが求められます。過度に装飾されたPDFよりも、MinerUのようなツールで解析しやすい、構造が明確な資料を蓄積することが、結果として社内の知見をAIに「深く理解させる」最短ルートになります。
MinerUを皮切りに、AI活用チームを加速させよう
MinerUは単なるツールではなく、AI活用のための「インフラ」です。現場の課題感(精度の限界)を技術的な解決策へ繋げ、エンジニアと協力してセキュアで高精度なRAG環境を構築しましょう。この小さな一歩が、貴社のDXの成否を分けることになります。
まとめ
MinerUの活用における要点は以下の通りです。
- データ品質の改善:AIの回答精度は前処理(PDFの構造化)で決まる。
- MinerUの優位性:複雑なレイアウト・数式・表をMarkdownとして正確に抽出し、AIが理解可能な形式へ変換する。
- 高いセキュリティ:ローカル環境で動作するため、機密情報も安心して処理可能。
- 役割分担:環境構築はエンジニアに依頼し、現場担当者は「構造化されたナレッジ」をどう活用するかという戦略に集中する。
まずは、現在AIがうまく回答できていない社内PDFを1つ用意し、エンジニアと共に検証プロジェクトを立ち上げてみてください。その精度の違いを実感すれば、全社展開への道筋が明確に見えてくるはずです。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


