
【2026年最新】Mamba-3とは?Transformerを超える「推論効率」の仕組みを解説
 AIエージェントナビ編集部
AIエージェントナビ編集部
AI活用の現場では、精度の高さだけでなく「いかに速く、安く動かすか」という推論効率が経営上の最重要課題となっています。本記事では、次世代のAIアーキテクチャとして注目される「Mamba-3」の革新性と、従来のTransformer(トランスフォーマー)との戦略的な使い分けについて解説します。
目次
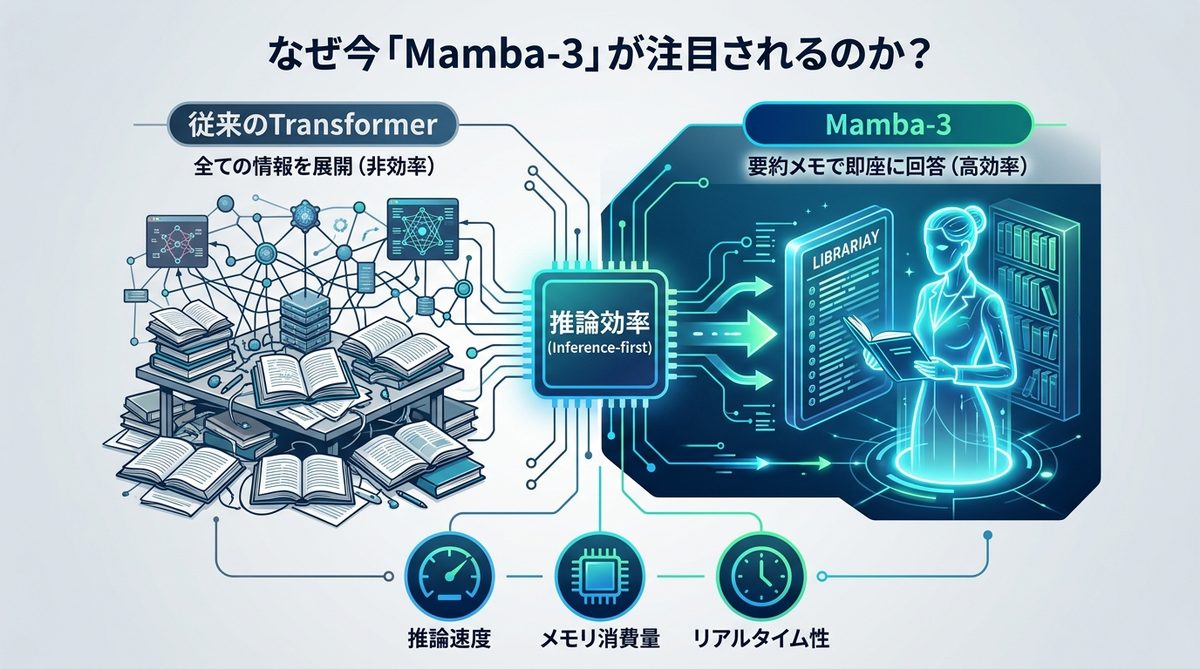
なぜ今「Mamba-3」が注目されるのか?AI運用の新たな選択肢
AIをビジネスに本格導入する際、無視できないのが「モデルの重さ」と「推論コスト」です。Mamba-3は、その限界を突破する可能性を秘めた技術として、エンジニアのみならずマネジメント層からも熱い視線を浴びています。
推論効率(Inference-first)が変えるAI開発の常識
これまでのAI開発は、とにかくモデルのサイズを大きくし、精度を追い求める「学習効率(Learning-first)」が主流でした。しかし、実務でAIを運用する場合、重要なのは「推論速度」と「メモリ消費量」です。Mamba-3は、推論コストを最小化しながら長文を処理する「推論効率(Inference-first)」をコンセプトに設計されており、リアルタイム性が求められるエージェント業務において圧倒的な優位性を誇ります。
図書館員に例えるMamba-3の革新性
Mamba-3の仕組みを分かりやすく説明するために、「図書館員」を例に挙げます。
- 従来のTransformer: 質問を受けるたびに、図書館内のすべての本を一度机の上に広げ、内容を確認してから回答する方式です。資料が増えるほど机の上が乱雑になり、時間がかかります。
- Mamba-3: 必要な情報を整理されたインデックス(要約メモ)から即座に引き出す、熟練の司書です。膨大な資料があっても、常に一定の速度で必要な情報を抽出できます。
関連記事:【DX担当者必見】そのPDF、AIは読めていますか?MinerUで実現する高精度ナレッジベース構築術
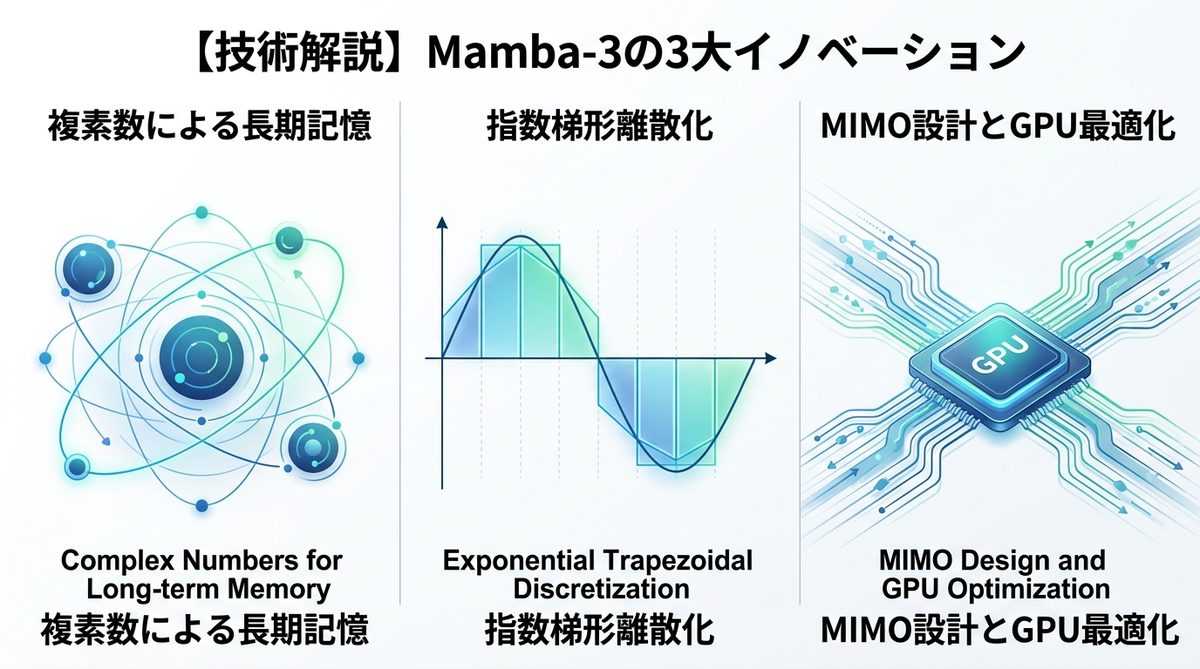
【技術解説】Mamba-3の3大イノベーション
Mamba-3(arXiv:2408.00714)がなぜこれほどまでに高速で効率的なのか。その核心となる3つの技術的ブレイクスルーを解説します。
1. なぜ「複素数」が長期記憶の劣化を防ぐのか
AIが長い文章を記憶し続けるためには、「情報の減衰」を防ぐ必要があります。Mamba-3では「複素数(実数と虚数の組み合わせ)」を状態表現に用いることで、情報の回転動態(情報を円運動のように保持する動き)を実現しました。これにより、遠い過去の文脈を失わずに維持できるため、長文処理における記憶効率が飛躍的に向上しています。
2. 精緻な状態更新を支える「指数梯形離散化」
AIが連続的なデータを計算する際、計算を区切る「離散化」という作業が発生します。Mamba-3は「指数梯形離散化(Exponential Trapezoidal Discretization)」という手法を採用し、時間的な連続性を維持しながら効率的な計算を可能にしました。これにより、推論の精度を落とすことなく、計算処理の最適化を実現しています。
3. MIMO設計でGPU性能を極限まで引き出す
Mamba-3は、複数の入力と出力を同時に処理する「MIMO(Multi-Input Multi-Output:多入力多出力)」構造を最適化しています。これは、GPU(画像処理装置)が持つ並列演算能力を極限まで使い切る設計です。単一の入出力を行うモデルと比べ、推論の応答速度が大幅に加速し、サーバー負荷を劇的に抑えることが可能になりました。
関連記事:【図解】Claude Codeの並列実行で「一人10人分」の生産性を出す:/batchとworktreeの実践ガイド
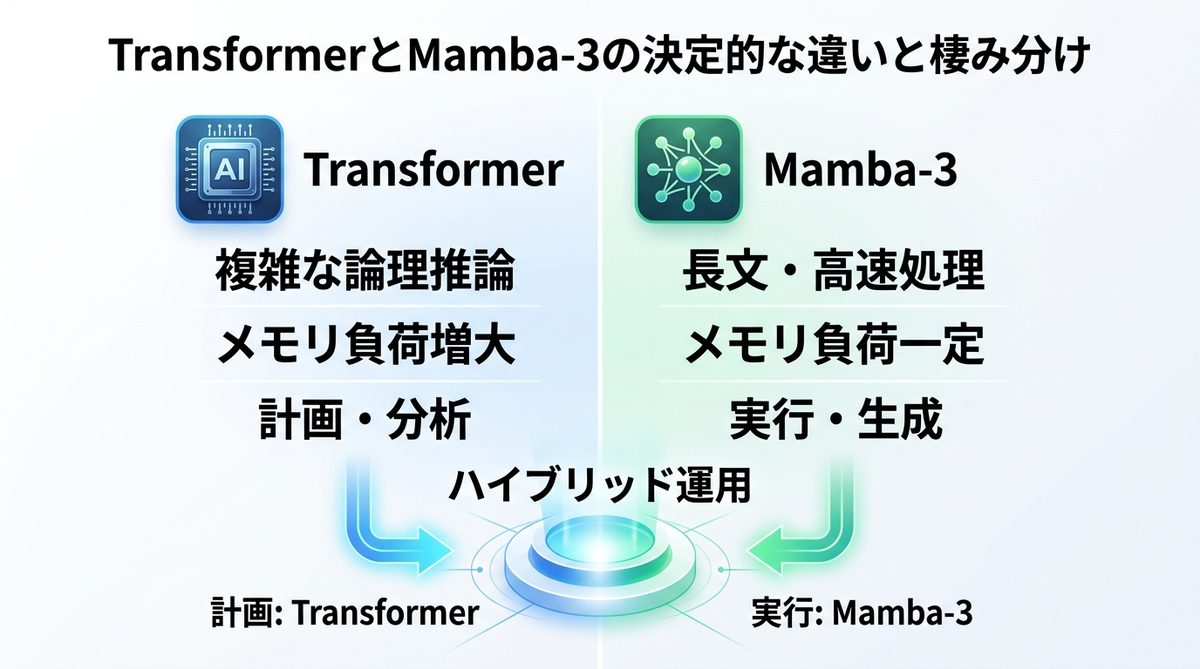
TransformerとMamba-3の決定的な違いと棲み分け
Mamba-3が登場したからといって、すべてがTransformerから置き換わるわけではありません。重要なのは、適材適所の「ハイブリッド運用」です。
得意領域の比較表:長文処理 vs 複雑な推論
| 特徴 | Transformer | Mamba-3 |
|---|---|---|
| 得意領域 | 複雑な論理推論・要約 | 長文生成・リアルタイム処理 |
| メモリ負荷 | 文章量に比例して増大 | 一定で安定 |
| 応答速度 | 低速(文脈が長い場合) | 高速(一定) |
| 主な用途 | 検索・計画策定・分析 | 会話・翻訳・長文データ生成 |
最新トレンド「ハイブリッド運用」の具体例
現在、最も進んでいるAI構築手法は、両者を組み合わせる「ハイブリッド運用」です。
- 計画(Planning): Transformerを使用して、複雑な手順やロジックを設計。
- 実行(Execution): Mamba-3を使用して、膨大なログデータや長文ドキュメントを高速に生成・抽出。
このように構成することで、コストと速度、そして精度のすべてを高いレベルで両立できます。
関連記事:【完全ガイド】Claude CodeのPlan Modeとは?AI開発の品質を劇的に高める「設計→実行」ワークフロー
AIエージェント運用の未来:Mamba-3がもたらすビジネス成果
Mamba-3の導入は、コスト削減だけでなく、エンドユーザーの体験(UX)向上に直結します。
推論コストを大幅削減し、UXを向上させる方法
GPUの演算強度が最大化されるため、クラウドのAPI利用料やオンプレミスサーバーの電気代を削減可能です。また、応答速度が向上することで、「AIの回答を待つ」というストレスが排除され、業務効率が劇的に向上します。
Mamba-3の実装における留意点と導入ハードル
導入の際は、既存のTransformer向けエコシステムとの互換性に注意が必要です。現状では、学習ライブラリの多くがTransformerに最適化されているため、モデル開発には専門的な調整が求められます。まずは、非同期処理が必要なタスクや、ログ解析などの特定領域からスモールスタートすることをお勧めします。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
【経営層向け】AI導入時、ベンダーに聞くべき基盤モデルの評価軸
AIベンダーとの対話において、「精度」だけを指標にするのは危険です。
精度だけでなく「推論効率」を重視すべき理由
どれほど精度の高いモデルでも、推論に1分かかるAIは現場では使われません。ベンダーに対し、「このモデルは推論効率が最適化されているか?」「Mamba系モデルの検討余地はあるか?」と問いかけることで、長期的な運用を見据えたモデル選定が可能になります。
ハイブリッドなAI構成をベンダーと合意する重要性
「すべてのタスクを単一の高性能モデルで解決しようとしない」というアーキテクチャ設計の視点を持たせてください。タスクの性質に合わせてモデルを選択するベンダーこそ、貴社のDXを正しく推進できるパートナーといえます。
関連記事:【コスト最適化】Claude CodeのAPI代を抑える「モデルルーター」活用戦略と注意点
まとめ
Mamba-3は、AI運用の効率を根本から変える次世代技術です。今回の要点は以下の通りです。
- 推論効率の追求: モデルのサイズ競争から、推論スピードとコスト最適化の時代へシフトしています。
- 技術的核心: 「複素数」「指数梯形離散化」「MIMO」の3技術が、高速かつ精緻な処理を実現しています。
- ハイブリッド運用: Transformerの思考力とMamba-3の処理速度を掛け合わせるのが最適解です。
- 経営判断: 導入時は精度だけでなく、運用コストを含めた推論効率を重視すべきです。
まずは自社のAI活用状況を棚卸しし、推論コストが肥大化しているタスクを特定しましょう。ぜひ、Mamba-3を用いた次世代アーキテクチャの導入を検討してみてください。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


