
OpenClawとOllamaの統合ガイド|安全なローカルAI環境構築手順
 AIエージェントナビ編集部
AIエージェントナビ編集部
社内の機密データや顧客情報を扱う際、クラウド型のAIサービス利用には常に情報漏洩のリスクが伴います。自社専用の閉域環境で、高度な自律型AIエージェントを動かしたいと考えるIT担当者は増えています。
本記事では、ローカルLLM運用プラットフォーム「OpenClaw」と、推論エンジン「Ollama」を統合し、実務で安全に稼働させるための具体的な構築ステップを解説します。
この記事に対する編集部の見解
- クラウドAIへの機密データ入力はオプトアウトしていても外部送信が発生しコンプライアンスリスクになる
- OpenClaw+Ollamaは完全ローカル動作でデータが外に出ないためシャドーAI対策にも有効
- 企業版NemoClawに移行すればAD認証・ログ監視でAI利用のガバナンスを一元管理できる
目次
【基礎知識】ローカルAIエージェントの必要性
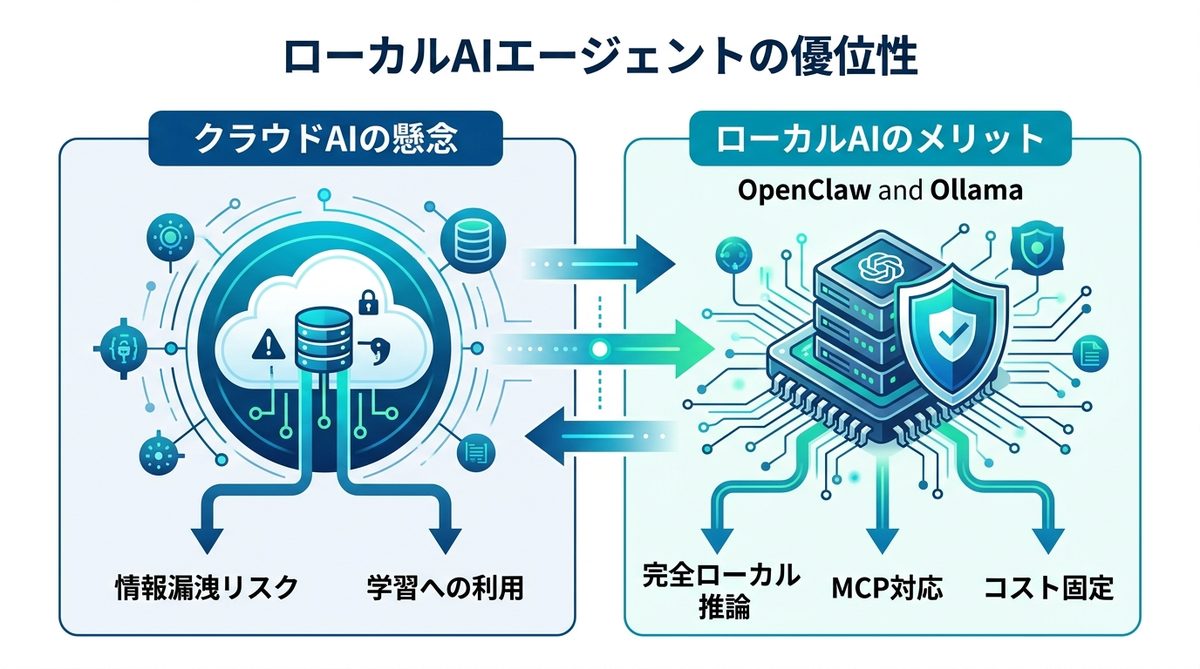
クラウドAIは強力ですが、企業が保有する未公開データやソースコードを外部サーバーに送信することには、依然として高いハードルがあります。
クラウドAIと機密漏洩のジレンマ
多くの生成AIサービスは、プロンプトの内容がAIの学習に再利用される可能性があります。たとえオプトアウト設定をしていても、ネットワーク越しにデータを送る時点で、コンプライアンス上の懸念は拭えません。
完全閉域運用のメリット
OpenClawは、ローカル環境で自律型エージェントを実行するプラットフォームです。これにOllamaを組み合わせることで、以下のメリットが生まれます。
* 完全ローカル推論: 外部ネットワークへの通信が不要。
* MCP(Model Context Protocol)対応: ローカルリソースへの安全なアクセスが可能。
* コストの固定化: API料金を気にせず、社内サーバーのリソース内で運用可能。
関連記事:【2026年最新】OpenClawとは?AIエージェントの仕組みと、安全に業務導入する「NemoClaw」活用ガイド
【要件確認】OpenClaw×Ollamaの構築準備
構築を成功させるためには、まずはハードウェアとソフトウェアのスペックを正確に把握することが重要です。
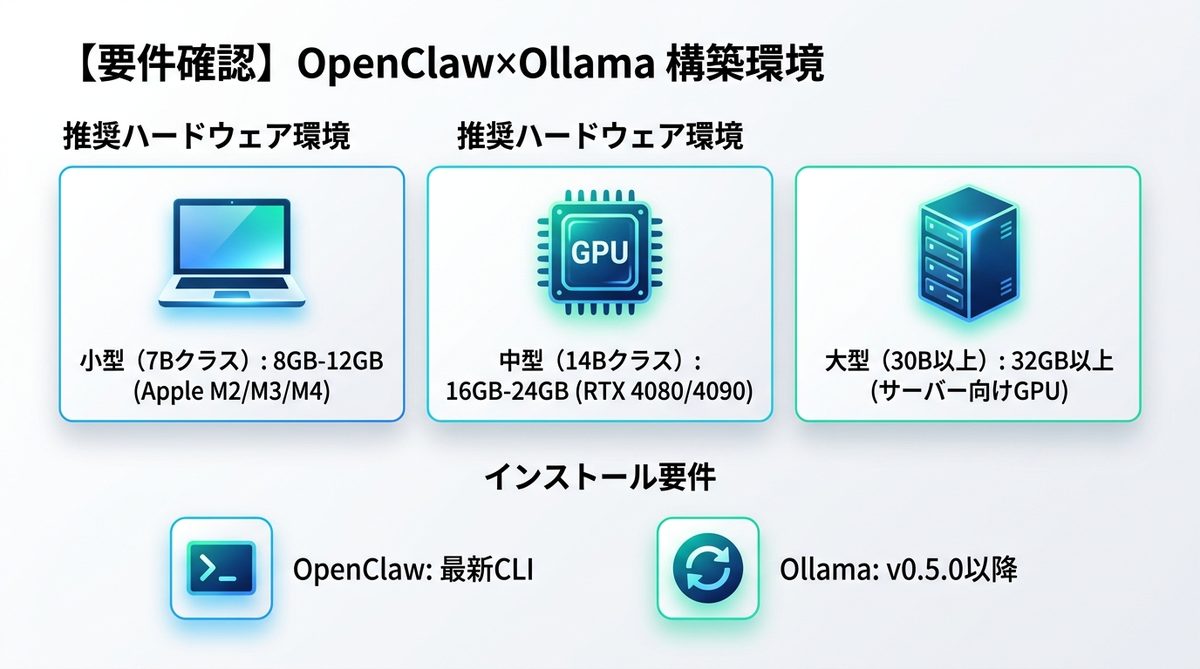
推奨ハードウェア環境
ローカルLLMの動作は、搭載されているVRAM(ビデオメモリ)量に直結します。
| モデル規模 | 必要VRAM目安 | 推奨ハードウェア |
|---|---|---|
| 小型 (7Bクラス) | 8GB - 12GB | Apple M2/M3/M4 (16GB RAM以上) |
| 中型 (14Bクラス) | 16GB - 24GB | RTX 4080/4090搭載のWindows PC |
| 大型 (30B以上) | 32GB以上 | サーバー向けGPU (A6000/H100等) |
インストール要件とバージョン
- OpenClaw: 最新のCLI(コマンドラインインターフェース)バージョンをインストールしてください。
- Ollama: v0.5.0以降を推奨します。最新のMCP仕様に対応するためです。
関連記事:【2026年版】ローカル生成AIの始め方|PCスペック判定表とおすすめソフト徹底解説
【実装編】OpenClawとOllamaの接続設定
ここでは、実際にエージェントがPC内で稼働するまでの3ステップを解説します。
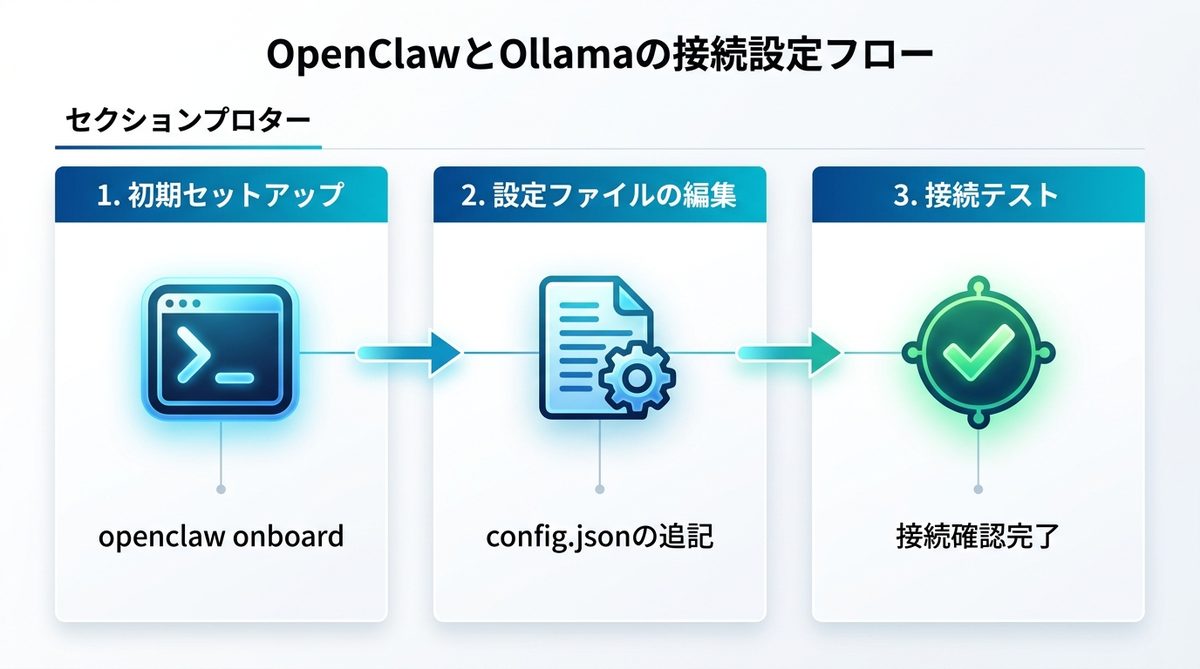
1. openclaw onboardによる初期セットアップ
ターミナルを開き、以下のコマンドを実行して設定を初期化します。
openclaw onboard --provider ollama
このコマンドにより、プロジェクトフォルダ直下に.openclawディレクトリとconfig.jsonが生成されます。
2. config.jsonへのOllamaエンドポイント追記とダミーAPIキー設定
生成されたconfig.jsonを編集します。ローカル接続のため、APIキーは任意の値で問題ありません。
{ "llm_provider": "ollama", "api_endpoint": "http://localhost:11434/v1", "api_key": "dummy-key-for-local", "model_name": "llama3.2:latest" }
3. localhost:11434のルーティングと接続テストの実施
以下のコマンドで接続を確認します。
openclaw healthcheck
「Connection established」と表示されれば成功です。Ollamaがローカルサーバーとして正しく認識されています。
関連記事:【2026年最新】OpenClaw導入設定マニュアル|初期構築からチャット連携・エラー解決まで完全網羅
【技術深掘り】ローカルモデルのTool Use
自律型AIが「自分でファイルを編集する」「テストを実行する」ためには、モデルの選定が鍵となります。
モデル選定とメモリ最適化
Tool Use(ツール呼び出し)には、論理的推論能力が高いモデルを選ぶ必要があります。llama3.2やqwen2.5などの最新モデルを推奨します。
- メモリ節約術: 不要なバックグラウンドアプリを終了し、LLM専用のVRAMを確保してください。
モデルが見つからない・ポート競合時のトラブルシューティングQ&A
Q: 「Model not found」と表示されます。
A: ollama pull [モデル名]が完了しているか確認してください。
Q: 「Port already in use」というエラーが出ます。
A: 他のアプリケーションがポート11434を占有しています。タスクマネージャーで競合プロセスを終了させてください。
関連記事:【徹底比較】Claude Code vs OpenClaw:自律型AIエージェントの選び方

【発展編】企業導入へ:NemoClawへの移行
OpenClawでの検証が完了したら、次はチーム全体での運用を検討しましょう。
OpenClawとNemoClawの使い分け
- OpenClaw: 個人または小規模チームの検証用。
- NemoClaw: 企業版。AD(Active Directory)認証やログ監視機能が統合されており、管理者のガバナンスが効く設計になっています。
制限環境下の運用ベストプラクティス
企業導入の際は、外部への不要な通信をファイアウォールで遮断し、Ollamaのインスタンスを専用セグメントに隔離することで、より堅牢なセキュリティ体制が構築できます。
関連記事:【2026年最新】生成AI比較|企業導入を成功させる6つの選定軸と安全なガバナンス設計
まとめ:安全なローカルAI運用チェックリスト
最後に、構築後に必ず確認すべきポイントを整理しました。
- [ ]
config.jsonのAPIキーがダミーであること(誤送信防止) - [ ]
localhost:11434へのアクセス制限が適切か - [ ] GPUメモリがモデルに対して十分な空き容量を確保できているか
- [ ] モデルのバージョンが最新に更新されているか
ローカル環境でのAI構築は、最初は難しく感じるかもしれませんが、一度環境を整えてしまえば、セキュリティを担保したまま開発効率を劇的に向上させることが可能です。ぜひ、まずは小規模なプロジェクトから自動化を始めてみてください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- クラウドAIへの機密データ入力はオプトアウトしていても外部送信が発生しコンプライアンスリスクになる
- OpenClaw+Ollamaは完全ローカル動作でデータが外に出ないためシャドーAI対策にも有効
- 企業版NemoClawに移行すればAD認証・ログ監視でAI利用のガバナンスを一元管理できる


