【2026年最新】生成AI API導入の実戦ガイド|コスト・リスク・運用を最適化する実装戦略
 AIエージェントナビ編集部
AIエージェントナビ編集部
生成AIを自社製品や社内業務に組み込む際、単にAPIを繋ぐだけではコスト高騰やセキュリティリスクという「実装の壁」に直面します。2026年現在、API導入の勝敗を分けるのは、開発初期からの堅実なコスト設計と将来を見据えた疎結合(モジュール間の依存度を低くする)なアーキテクチャ設計です。
本記事では、PdM(プロダクトマネージャー)やエンジニアが明日から実践できる、生成AI API実装の意思決定ガイドを解説します。
目次
生成AI APIを活用した「エンジンの部品化」で業務を自動化する
生成AI APIとは何か?:PCの中に優秀なアシスタントを常駐させる仕組み
生成AI APIとは、AIモデルの頭脳をネットワーク経由で外部から呼び出すためのインターフェースです。自社システムにAPIを組み込むことは、PCの中に24時間稼働する優秀なアシスタントを常駐させることに等しく、定型業務の自動化から複雑なデータ解析までを飛躍的に高速化します。
なぜAPIを直接呼び出すのか:社内システム・自社製品と連携するメリット
Web上のチャット画面を使うのではなく、APIを直接呼び出す理由は「自社製品への完全な統合」にあります。
- UX(ユーザー体験)の向上:ユーザーがAIを意識することなく、アプリケーションの一部として自然に推論結果を利用できる。
- データフローの自動化:データベースと直結することで、人間がコピー&ペーストする手間をゼロにする。
- スケール対応:数千、数万のリクエストをシステムが自動で処理可能。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
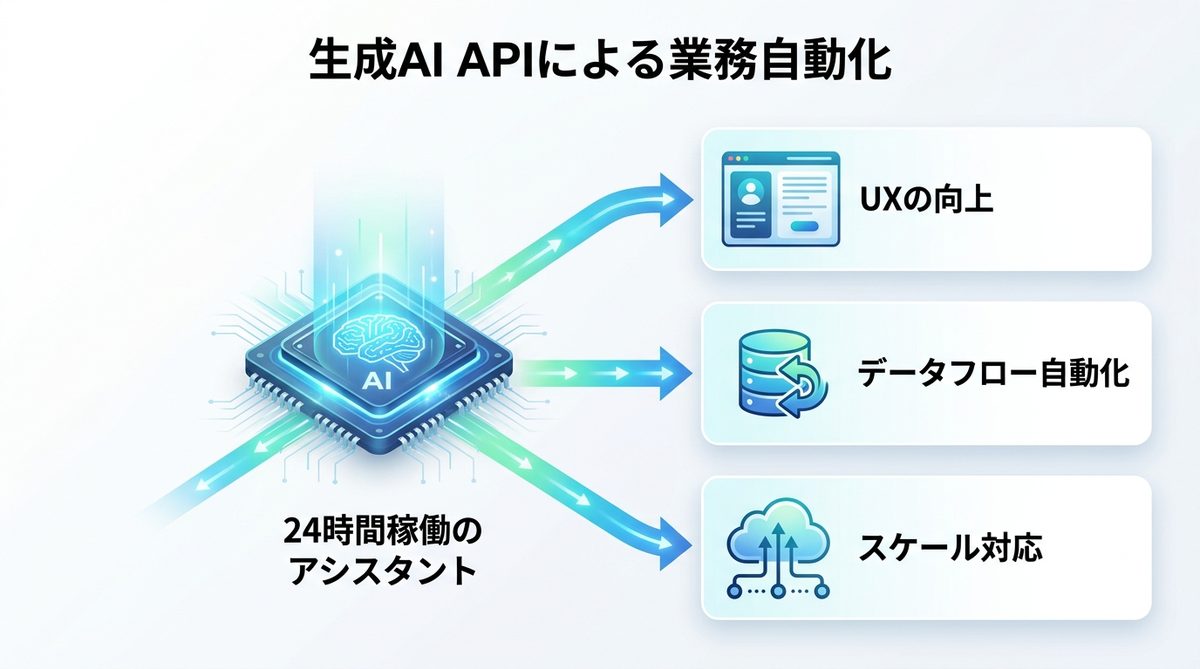
【意思決定】用途別モデル選定マトリクス:精度とコストを最適化する
高度推論と定型処理の使い分け:GPT-5系と超軽量モデルの階層化運用モデル
すべての業務に最高性能のモデルを割り当てるのはコストの無駄です。以下のような階層化運用が基本となります。
| 業務カテゴリ | 推奨モデルクラス | 理由 |
|---|---|---|
| 戦略策定・複雑な設計 | 最上位モデル (GPT-5系等) | 推論能力と論理的整合性が必須のため |
| テキスト要約・分類 | 中位モデル | 速度と精度のバランスが良いため |
| ログ分析・単純変換 | 超軽量モデル | 低コストかつリアルタイム性が重要のため |
レイテンシ・コンテキスト長・単価を比較するモデル選定フローチャート
モデル選定は「4つの基準」に基づき、意思決定を行います。
1. タスクの複雑性:回答の論理構築が必要か?
2. 許容レイテンシ(応答速度):ミリ秒単位の応答が必要か?
3. コンテキスト長(記憶容量):一度に読み込ませる文書量はどれくらいか?
4. 予算(トークン単価):月間のリクエスト数はどの程度か?
進化し続けるモデルとの向き合い方:最新スペックがビジネスに与える影響
AIモデルは数ヶ月単位でアップデートされます。常に最新モデルへ追従するのではなく、「安定稼働」と「性能向上」のバランスを見て、ビジネス上のROI(投資対効果)を計算し続ける姿勢が重要です。
関連記事:【比較検証】Qwen3.5-OmniでAI活用を最適化!ビジネス現場での最適なモデル選定基準とは
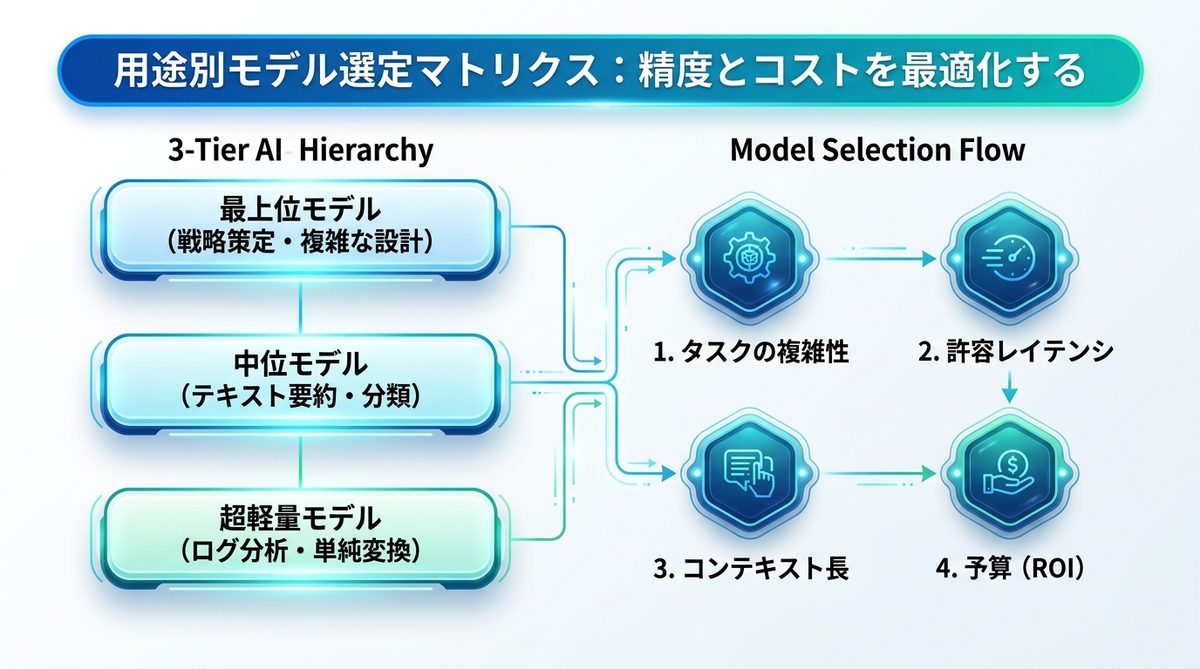
【運用】生成AI APIのコストを半減させる技術的アプローチ
Batch APIで非同期処理を行いコストを50%カットする方法
即時の応答が不要な処理(レポート生成や大量のデータ分類など)には、Batch APIを活用してください。リクエストをまとめて送信することで、コストを50%程度削減できるだけでなく、レート制限の影響を受けにくくなります。
Prompt Caching(プロンプトキャッシュ)を活用したトークン節約術
システムプロンプトや、繰り返し参照する膨大なドキュメントをキャッシュする「Prompt Caching」を積極的に活用しましょう。これにより、入力トークンの消費を劇的に抑えられます。
API使用量を監視し、レート制限(429エラー)を回避するモニタリング体制
APIの利用状況をダッシュボードで可視化し、予算アラートを設置することは不可欠です。429エラー(過剰リクエストによる制限)が発生しないよう、指数バックオフ(間隔を空けて再試行する仕組み)の実装を徹底しましょう。
関連記事:【2026年版】生成AI導入の決定版:自社PC vs クラウドGPU 失敗しない選び方と投資基準
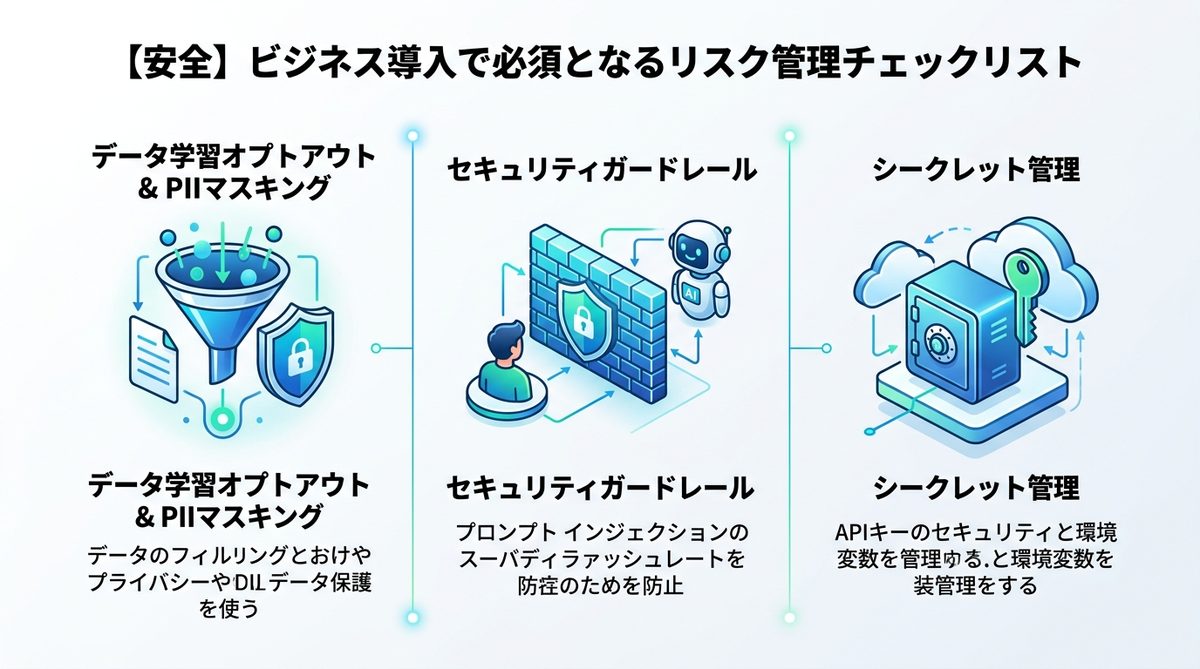
【安全】ビジネス導入で必須となるリスク管理チェックリスト
データ学習のオプトアウト設定とPII(個人情報)マスキングの具体的手順
企業利用において「自社データがモデルの学習に使われないこと」は絶対条件です。API設定でデータ学習オプトアウトを確実に有効化し、送信前のPII(氏名・電話番号等の個人情報)マスキングを実装して、AIに機密情報を渡さない設計を構築してください。
プロンプトインジェクションを防ぐ:セキュリティガードレール構築の要点
攻撃者からAIを保護するための「セキュリティガードレール」を導入しましょう。ユーザー入力がモデルに渡る前に検証を行い、有害な命令や予期せぬ挙動を引き起こす入力をブロックします。
APIキーの漏洩リスクと、環境変数およびシークレット管理のベストプラクティス
APIキーをコード内に直書きするのは厳禁です。クラウドプラットフォームが提供する「Secret Manager(シークレット管理ツール)」を使用し、環境変数として動的に呼び出す運用を徹底してください。
関連記事:【DX最前線】Mistral AIとは?企業が選ぶべき「安全で高コスパ」なAIインフラの正体
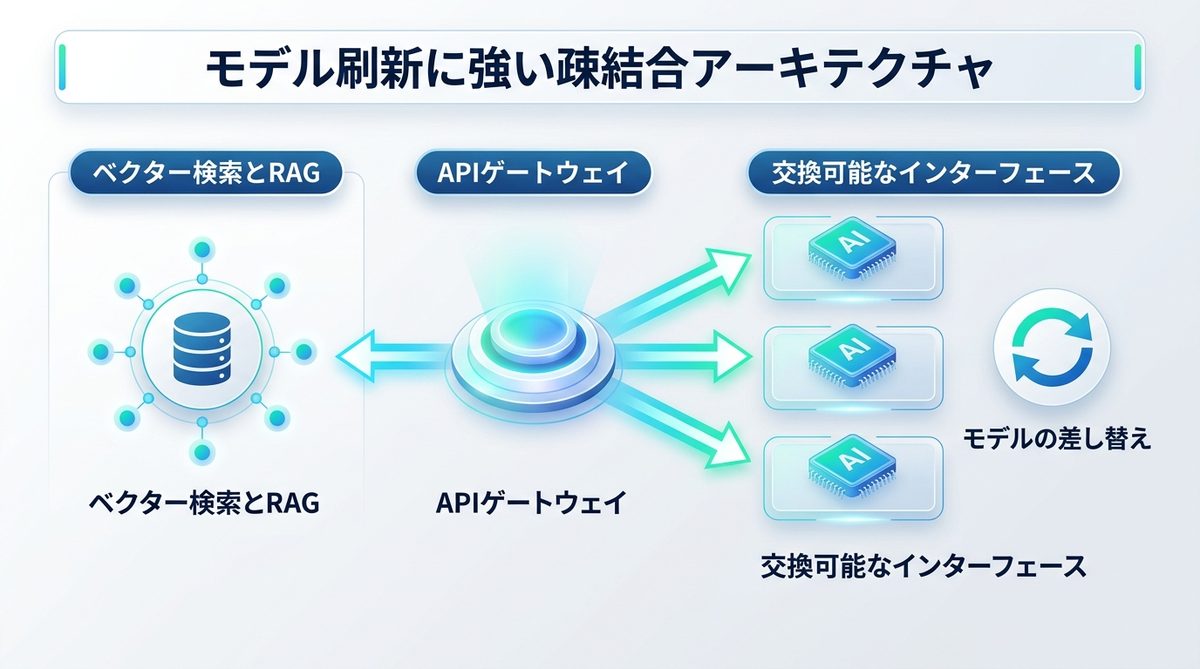
【設計】モデル刷新に強い疎結合アーキテクチャの構築法
APIゲートウェイを導入し、特定プロバイダーへの依存を回避する設計
特定のモデルに深く依存しないよう、「APIゲートウェイ」を挟む設計が有効です。これにより、将来より安価で高性能なモデルが登場した際、システム側の改修を最小限に抑えて「モデルの差し替え」が可能になります。
RAG(検索拡張生成)連携のためのベクター検索基礎とデータの取り回し
社内ドキュメントを活用するRAG(検索拡張生成)では、データをベクトル化してデータベースに保存します。この際、生のテキストとベクトルを分けることで、検索精度を後から調整できる柔軟性を確保してください。
半年後のモデルアップデートを前提とした「交換可能」なインターフェース設計
APIゲートウェイのインターフェースを標準化し、モデルごとの固有パラメータを隠蔽することで、どんなプロバイダーのモデルでも同じコードベースで扱えるよう設計します。
関連記事:【検証】Rakuten AI 3.0はなぜ選ばれるのか?導入コストと計算資源から見る「自社AI基盤」構築の現実
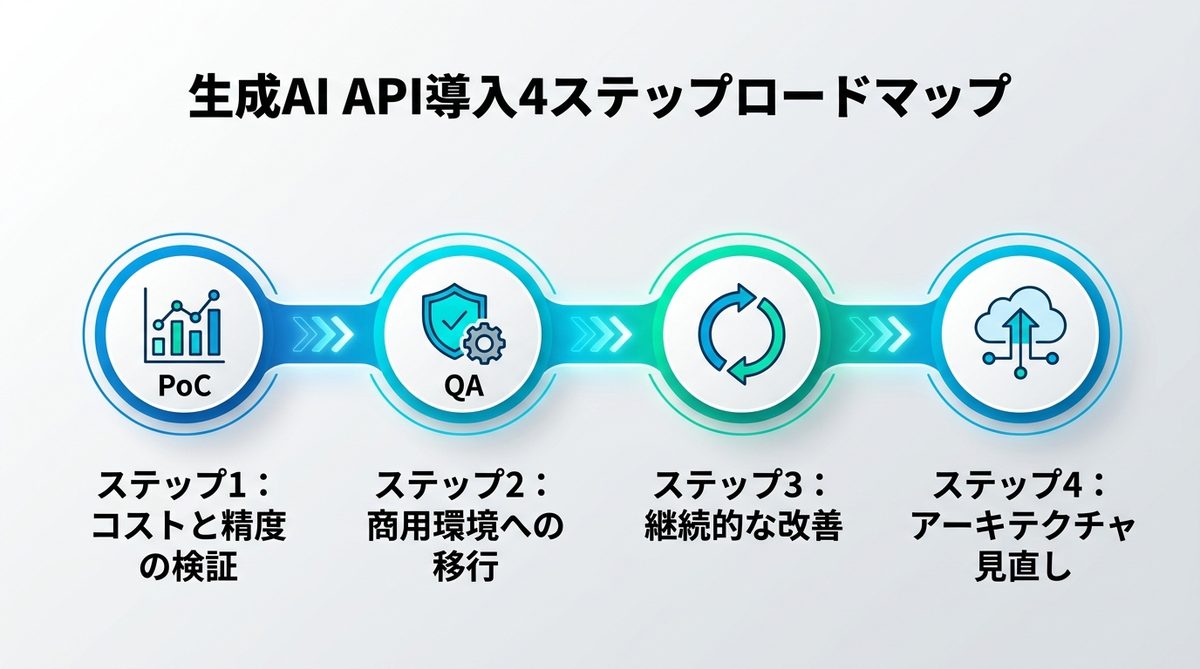
【実践】PoCから本番運用へ:生成AI API導入4ステップロードマップ
- ステップ1:PoCで検証すべき「コストと精度の損益分岐点」
- 定量的な精度評価指標(正解率や再現率)を定め、コストに見合うかを確認する。
- ステップ2:開発環境から商用環境へ移行する際のQA基準
- セキュリティ、速度、エラーハンドリングのテストを通過させる。
- ステップ3:本番運用開始後の継続的な性能評価と改善サイクル
- ユーザーのフィードバックとAPIログを元に、プロンプトの微調整を行う。
- ステップ4:定期的なアーキテクチャ見直し
- 半年に一度、モデルの単価と性能を確認し、ゲートウェイ経由でモデルを切り替える検討を行う。
関連記事:【図解】Rakuten AI 3.0を「使いこなす」には?無償公開モデルの運用コストと技術要件
まとめ
生成AI APIの実装は、単なる技術的な試行ではなく、コスト・リスク・運用を考慮した戦略的な意思決定が必要です。最後に要点を整理します。
- コスト管理:Batch APIとキャッシュを駆使し、トークン消費を最適化する。
- セキュリティ:学習オプトアウトと入力マスキングを必須項目とする。
- アーキテクチャ:APIゲートウェイを導入し、モデル刷新に強い設計を維持する。
- 評価サイクル:PoCから本番運用まで、4ステップで継続的な改善を回す。
まずは自社の業務で最も効果が出やすいユースケースを特定し、スモールスタートでAPI実装を始めましょう。今日から堅実な設計を導入すれば、半年後の競争力は大きく変わります。