
【Alibaba最新AI】Qwen 3.5とは?最新5大モデルを徹底比較
 AIエージェントナビ編集部
AIエージェントナビ編集部
2026年2月、Alibaba Cloud(アリババクラウド)は、最新の大規模言語モデル(LLM)シリーズ「Qwen 3.5」を発表しました。
前世代のQwen3から、アーキテクチャの効率化とエージェント機能の強化が図られ、テキスト、画像、動画、音声といった多様な情報をネイティブに扱えるマルチモーダル性能が特徴です。
本記事では、Qwen 3.5の特徴、ラインナップ、そして競合モデルであるGLM-5、Kimi K2.5、Gemini 3.1 Pro、Claude Opus 4.6との比較を通して、その実力と最適な利用シーンについて解説します。
1. Qwen 3.5の主な特徴とラインナップ
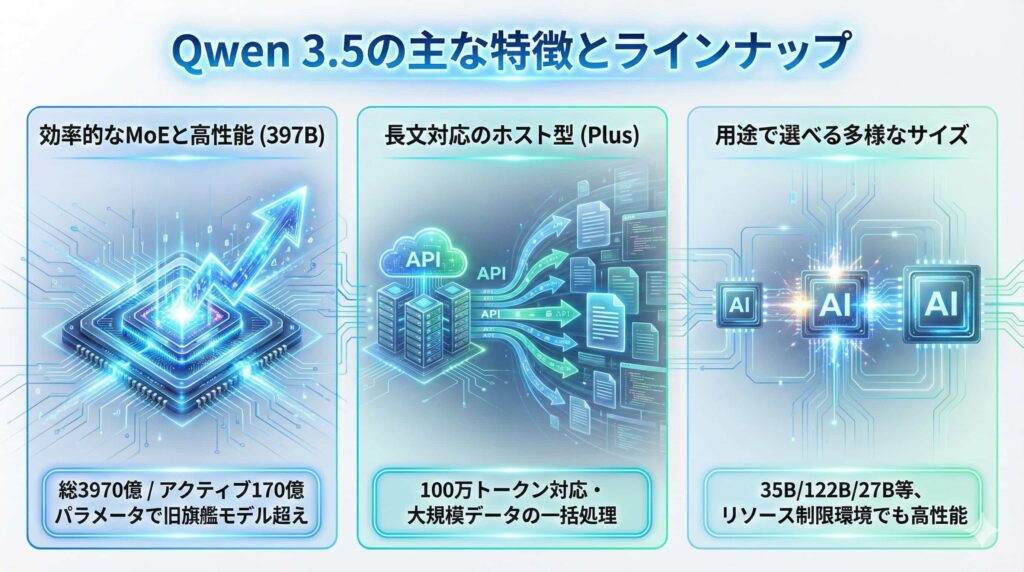
Qwen 3.5は、単一の巨大なモデルではなく、用途やリソースに応じて選択できる複数のサイズ展開が特徴です。
効率的なMoEアーキテクチャと高性能(397Bモデル)
シリーズ初のオープンウェイトモデルとなる「Qwen3.5-397B-A17B」は、総パラメータ数3,970億という巨大モデルですが、Mixture-of-Experts(MoE)構造を採用しています。これにより、推論時に実際にアクティブになるのはわずか170億パラメータのみに抑えられます。この効率的な仕組みにより、計算資源を節約しつつ、Alibabaの旧フラッグシップである1兆パラメータ超の「Qwen3-Max」を上回るベンチマーク性能を実現しています。
長文対応のホスト型モデル(Plusモデル)
Alibaba CloudのModel Studioを通じて提供される「Qwen3.5-Plus」は、API経由で利用できるホスト型モデルです。標準で100万トークンという長大なコンテキストウィンドウをサポートしており、大規模なマニュアル、契約書、コードベース全体の分析など、膨大な情報を一度に処理するタスクに適しています。
用途に合わせて選べる多様なサイズ
2026年2月24日には、さらなる追加モデル群(35B-A3B / 122B-A10B / 27B)がリリースされました。特に35Bモデルは、中規模サイズでありながら、前世代の235Bモデルを凌駕する性能を持つと報告されており、リソース制限のある環境でも高性能なAIを利用できる選択肢が広がっています。
2. Qwen 3.5の性能と利用シーン
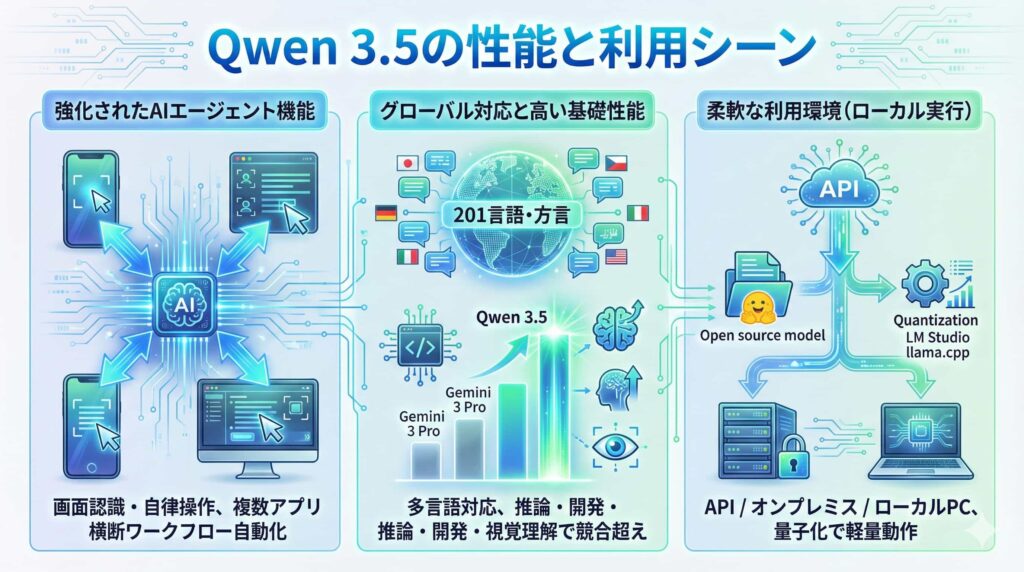
Qwen 3.5は、特に自律的にタスクを遂行する「AIエージェント」としての能力に重点を置いて設計されています。
強化されたAIエージェント機能
Qwen 3.5には、スマートフォンやコンピュータの画面を認識し、自律的に操作を行うビジュアルエージェントとしての機能が統合されています。これにより、Webブラウザを使った情報収集や、複数のアプリケーションを横断する複雑なワークフローの自動化などが期待できます。
グローバル対応と高い基礎性能
サポート言語が従来の119言語から201の言語と方言にまで拡大され、よりグローバルなビジネスシーンで利用できるようになりました。基礎性能も高く、推論、プログラミング、視覚理解などの主要なテストにおいて、GoogleのGemini 3 ProやOpenAIのGPT-5.2を上回るスコアが報告されています。
柔軟な利用環境(ローカル実行対応)
Qwen 3.5の大きな強みは、その柔軟性です。APIでの利用はもちろん、Hugging Faceなどからモデルの重みをダウンロードし、LM Studioやllama.cppなどのツールを使って量子化(軽量化)することで、自社のオンプレミス環境やローカルPC上でも動作させることが可能です。
関連記事:OpenClaw(旧MoltBot/Clawdbot)とは?PCを直接操作するローカルAIエージェント
3. 競合モデルとの比較:Qwen 3.5の強みとは?
Qwen 3.5は、他の最新フラッグシップモデルと比較して、どのような特徴があるのでしょうか。比較表と各モデルとの違いを解説します。
主要AIモデル比較表(2026年最新版)
| 特徴 | Qwen 3.5 (Alibaba) | Kimi K2.5 (Moonshot) | GLM-5 (Z.ai) | Gemini 3.1 Pro (Google) | Claude 4.6 Opus (Anthropic) |
| 最大の特徴 | 圧倒的コスパ・開発効率 | 論理推論・数学・思考 | 自律型エンジニアリング | 科学・マルチモーダル | 最高精度のツール操作 |
| 得意分野 | コード生成・多言語対応 | じっくり考える複雑な問題 | 長時間のタスク完遂 | 長文読解・データ解析 | 企業の業務自動化 |
| 思考プロセス | 高速・即答型 | 「思考の連鎖」を可視化 | 実行・検証の繰り返し | 確率論的な推論 | 厳密な指示遵守 |
| 提供形態 | オープンウェイト / API | API / Kimiアプリ | API / 中国国内向け | API / Google統合 | API / Web |
| コンテキスト | 100万トークン | 200万トークン以上 | 長期タスク対応 | 200万トークン | 長文解析に強い |
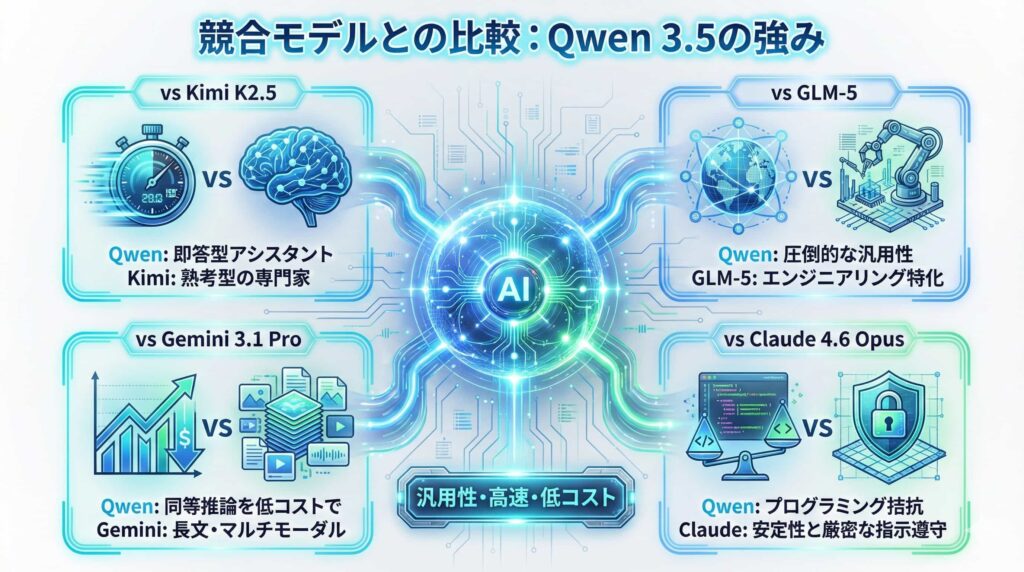
vs Kimi K2.5:汎用性と速度のQwen、思考力のKimi
Qwen 3.5は、幅広い知識に基づき、高速かつ低コストで回答を生成する「即答型」の優秀なアシスタントです。対してKimi K2.5は、数学の難問や複雑な論理パズルにおいて、時間をかけて思考プロセスを積み上げ、高い正答率を叩き出す「熟考型」の専門家です。思考プロセスを可視化できる点もKimiの大きな強みです。
関連記事:【頂上決戦】Kimi K2.5爆誕!GPT-5.2、Claude 4.5、Gemini 3.0と徹底比較
vs GLM-5:同じ中国発、汎用性で勝るQwen
GLM-5は、複雑なシステム開発を自律的に行う「エンジニアリング・エージェント」能力に特化しています。Qwen 3.5は、プログラミング能力の高さに加え、オープンウェイトモデルとして自由に利用できる汎用性の高さが最大の差別化ポイントです。
関連記事:【徹底比較】GLM-5 vs Claude Opus 4.6|エージェント性能で凌駕する高コスパAI
vs Gemini 3.1 Pro:同等の推論能力を低コストで
Gemini 3.1 Proは、200万トークンの長文処理能力と、マルチモーダルな表現力に優れます。Kimi K2.5は同等以上の長文読解力と、より深い論理的整合性のチェック能力を持っています。Qwen 3.5は、Geminiと同等の推論能力を、より低いコストで提供できる点が魅力です。
関連記事:【推論性能2.5倍】Gemini 3.1 Pro vs Gemini 3.0 Pro徹底比較
vs Claude 4.6 Opus:プログラミング性能は拮抗、安定性はClaude
Claude 4.6 Opusは、実際の開発現場でのバグ修正や、正確なGUI操作において非常に高い信頼性を誇ります。Qwen 3.5はプログラミングのベンチマークスコアでは匹敵しますが、複雑な業務フローにおける確実性・厳密な指示遵守という点では、Claudeに一日の長があります。
関連記事:【徹底比較】Claude 4.6 vs GPT-5.2 vs Gemini 3 Pro|ビジネスを変える最強AIはどれだ?
4. ユースケース別・最適なモデルの選び方
各モデルの特性を踏まえ、具体的なユースケース別にどのモデルを選ぶべきかをまとめました。
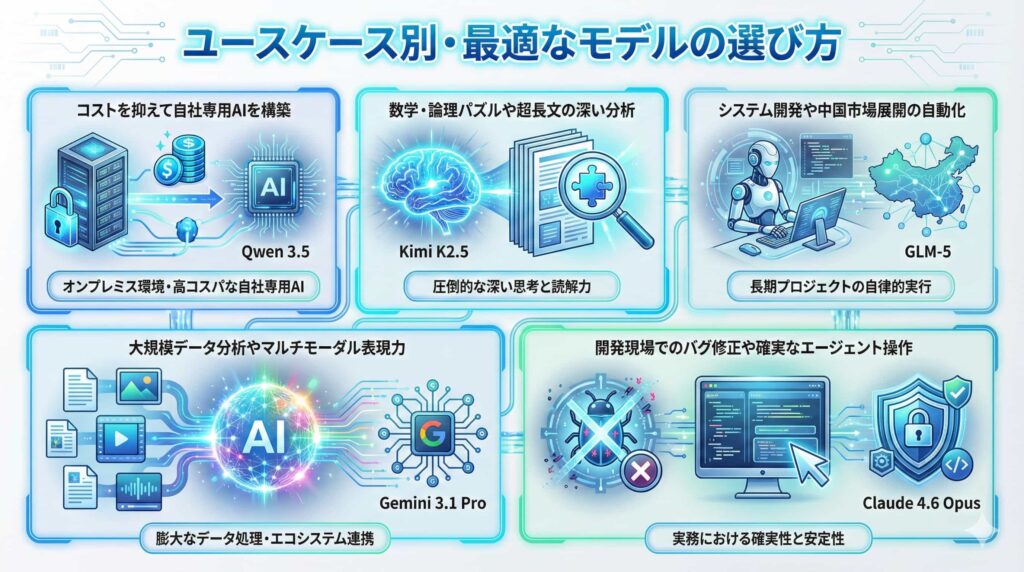
コストを抑えて自社専用AIを構築したい(Qwen 3.5推奨)
「自社の機密データを扱うためオンプレミス環境で動かしたい」「APIコストを気にせず大量に処理したい」といったニーズには、Qwen 3.5が最適です。オープンウェイトであり、MoEによる効率的な動作が可能なため、高コスパな自社専用AIを構築・運用できます。
数学・論理パズルや超長文の深い分析が必要(Kimi K2.5推奨)
「非常に難解な数学や物理の問題を解かせたい」「数千ページのPDF資料から論理的な矛盾点を洗い出したい」といった、深い思考と読解力が必要なタスクには、Kimi K2.5が圧倒的な能力を発揮します。思考プロセスを確認したい場合にも最適です。
高度なシステム開発や中国市場での展開を自動化したい(GLM-5推奨)
「長期にわたる複雑なシステム開発プロジェクトをAIエージェントに任せたい」「中国のビジネス環境に最適化されたAIが必要」という場合は、GLM-5が有力な選択肢です。
大規模データ分析やマルチモーダル表現力が必要(Gemini 3.1 Pro推奨)
「膨大なデータを読み込ませてマルチモーダルに分析したい」「Googleのエコシステムと連携させたい」といった用途には、Gemini 3.1 Proの総合力が適しています。
開発現場でのバグ修正や確実なエージェント操作を求める(Claude 4.6 Opus推奨)
「既存のコードベースのバグを正確に特定して修正してほしい」「PCの画面操作を伴う定型業務をミスなく自動化したい」といった、実務における確実性や安定性が最優先される場面では、Claude 4.6 Opusが最も信頼できるパートナーとなります。
まとめ
Qwen 3.5は、効率的なMoEアーキテクチャと強化されたエージェント機能、そしてオープンモデルとしての高い汎用性を兼ね備えた、非常に強力なAIモデルです。特にそのコストパフォーマンスと運用の柔軟性は、多くの開発者や企業にとって大きな魅力となるでしょう。自身のプロジェクトやビジネスの要件に合わせて、最適なモデルを選択してください。


