
【徹底比較】Qwen3.6 vs Claude Opus 4.7|APIコストを激減させる業務活用ポートフォリオの作り方
 AIエージェントナビ編集部
AIエージェントナビ編集部
毎月のAPI利用料が予算を圧迫し、DX推進の足かせになってはいませんか。特にAIエージェントの運用を全タスク「Claude Opus 4.7」で統一している場合、大幅なコスト削減の余地が残されています。
本記事では、2026年4月に登場したAlibaba Cloudの「Qwen3.6」シリーズを活用し、性能を維持しながら運用コストを最適化する「ハイブリッド運用」の手法を解説します。
目次
Qwen3.6とは?2026年4月リリースのモデル群とコスト破壊の衝撃
2026年4月に公開されたQwen3.6シリーズは、これまでのAI業界のコスト構造を根底から覆す破壊的なモデル群です。
なぜ今、Qwen3.6への注目度が高まっているのか
Qwen3.6シリーズは、APIコストの劇的な低減と、最高峰の推論性能を両立したことが最大の要因です。これまで「高性能なモデルは高額」という常識がありましたが、Qwen3.6は商用モデルとしてClaude Opus 4.7の1/17という圧倒的なコスト効率を実現しました。これにより、予算規模を気にせずAIエージェントを24時間フル稼働させる環境が整いました。
Max・Plus・Flashの性能比較とビジネス用途への適合性
Qwen3.6には、用途に応じた3つの主要モデルが存在します。それぞれの特徴を整理しました。
| モデル名 | 用途 | 性能特徴 |
|---|---|---|
| Max-Preview | 複雑なアーキテクチャ設計 | Claude Opus 4.7に並ぶ最高峰の推論精度 |
| Plus | 一般的なコーディング業務 | コストと性能のバランスが最適 |
| Flash | 大量のリファクタリングや要約 | 超低コストで高速な大量処理向き |
関連記事:【徹底比較】Qwen3.6 vs Qwen3.5の違いを徹底分析|長期自律エージェントに求められる性能向上とは
【徹底比較】Claude Opus 4.7 vs Qwen3.6|APIコストと推論性能のベンチマーク
コスト削減を検討する際、最も気になるのが「性能低下」ではないでしょうか。しかし、最新のベンチマーク結果は驚くべき事実を示しています。
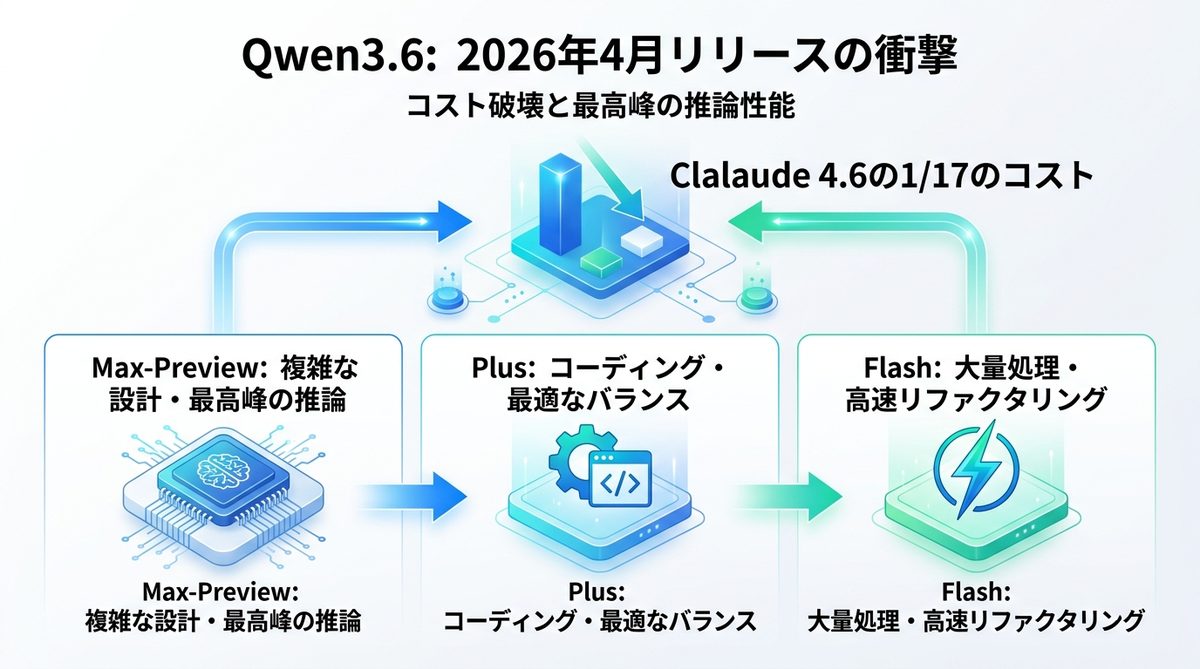
コスト効率1/17を実現!API料金と推論精度の相関データ
100万トークンあたりのコストを比較すると、Qwen3.6 PlusはClaude Opus 4.7のわずか約6%(約1/17)のコストで動作可能です。以下は主要モデルとの比較表です。
| モデル | コスト(入力/1M) | 推論精度(目安) |
|---|---|---|
| Claude Opus 4.7 | 基準(100%) | 非常に高い |
| Qwen3.6 Max | 約70% | 非常に高い |
| Qwen3.6 Plus | 約6% | 高い |
| Qwen3.6 Flash | 約1% | 標準 |
SWE-benchで検証する「エージェント性能」の真実
ソフトウェアエンジニアリング能力を測定する「SWE-bench(自動コード生成・修正能力の評価指標)」において、Qwen3.6はClaude Opus 4.7と遜色ないスコアを叩き出しています。特にルーチンワーク的なコード生成においては、Qwen3.6の軽快な動作がエージェントのレスポンス向上に直結します。
浮いた予算で何ができる?コスト削減によるDX投資の最適化案
APIコストを月間50万円から5万円に削減できたと仮定します。浮いた45万円を再投資することで、以下のようなDX施策を加速できます。
- AIエージェントのさらなる増強(多機能化)
- AI活用を推進する社内研修の充実
- データ基盤の整備(AIの精度を高める土台作り)
関連記事:AIエージェントおすすめ10選|無料で試せる順に個人・法人別で比較
精度の鍵は「preserve_thinking」にあり!長文コード生成を効率化する仕組み
AIエージェントのデバッグ精度を飛躍的に向上させるのが、Qwen3.6の思考保持機能(preserve_thinking)です。
思考プロセスを保持する仕組みとそのメリットとは
AIが回答を出す前に「どう考えたか」というプロセス(思考)を明示的に保持・参照させる技術です。これにより、複雑な依存関係を持つコード生成時でも、AIが過去の判断ミスを自己修正しやすくなります。
デバッグ精度の向上で「AIエージェントの修正コスト」を低減する方法
従来はAIの出力したコードが動かなかった場合、エンジニアが手動で原因を探る必要がありました。「preserve_thinking」を有効にすれば、AI自身が思考ログを振り返り、「先ほどはこのロジックで躓いたため、今回は別のアプローチを取る」といった自己補正が可能となり、修正の手間を大幅に削減できます。
関連記事:【徹底比較】Claude Opus 4.7 性能 比較レポート|GPT-5.4を凌駕する「自己検証能力」の衝撃
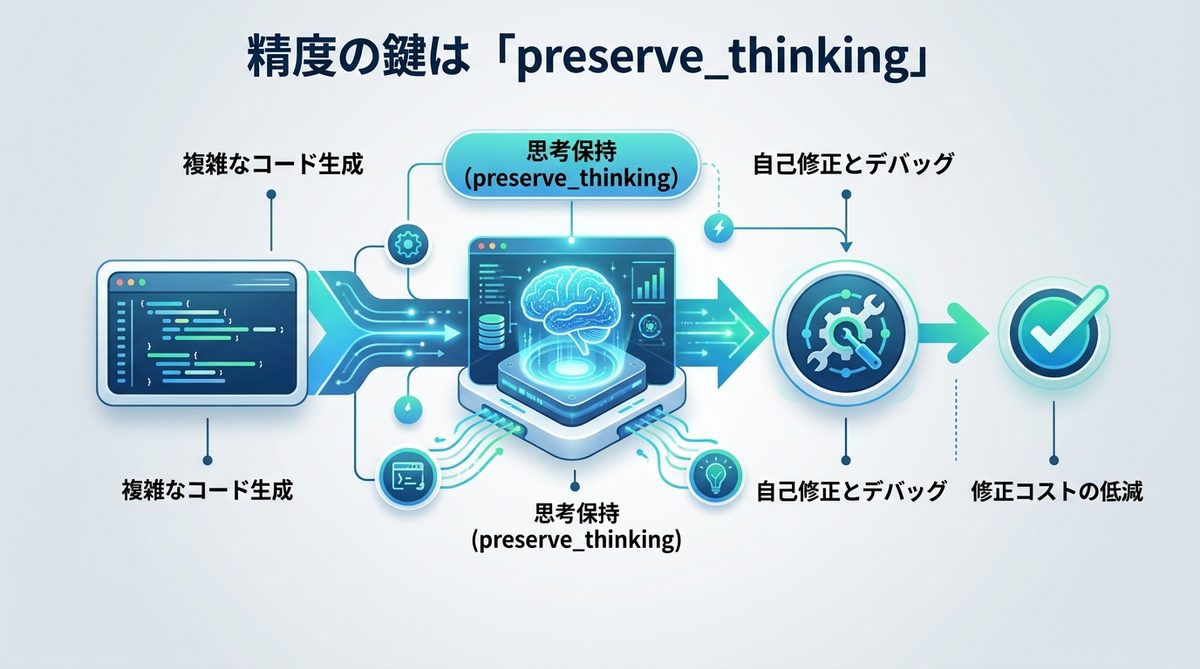
【導入手順】Model StudioからCursor・Continueへの接続ガイド
既存のAIエージェント環境(CursorやContinue)にQwen3.6を組み込む手順を解説します。
APIキー取得とモデル選択のステップ
- Alibaba Cloud「Model Studio」にログインします。
- 左メニューから「API Keys」を選択し、新規キーを発行します。
- 「Model」一覧から利用したいモデル(Max/Plus/Flash)を確認します。
既存のコーディング環境(Cursor/Continue)へ組み込む設定のコツ
- CursorやContinueの設定画面にある「API Provider」または「Model Setting」を開きます。
- エンドポイントをModel StudioのベースURLに設定し、取得したAPIキーを入力します。
- 「Model Name」に希望するQwen3.6のIDを入力すれば完了です。
関連記事:【比較検証】Claude CodeとCursor、結局どっちが最強?AI開発ツール選びの正解
セキュリティとデータ主権を両立する「OSS版・ローカル運用」という選択肢
機密性の高いデータを扱う企業にとって、クラウドAPIを通さずAIを動かすことは非常に重要です。
クラウドAPIを使わない「Qwen3.6-35B-A3B」の導入メリット
「Qwen3.6-35B-A3B」はオープンウェイト(公開モデル)として提供されており、自社のローカルサーバー上で完全に閉じて運用可能です。外部へのデータ送信が一切発生しないため、情報漏洩のリスクをゼロに抑えられます。
ローカル環境で機密情報を守りながらAIを運用する条件
このモデルはMoE(混合専門家)構成を採用しており、VRAM 16GB程度の一般的なAI PCでも軽快に動作します。セキュリティ要件が厳しいプロジェクトには、このOSS版を導入するのが最適解です。
関連記事:【経営戦略】Gemma 4を比較して分かった、データ主権を守りコストを最適化する「ローカルLLM」導入術
全部Claudeはやめる!Qwen3.6を賢く使い分けるハイブリッド運用のすすめ
すべてを最高性能モデルで賄うのはコストの無駄です。タスクの性質に応じてモデルを使い分けるポートフォリオを作成しましょう。
論理的思考が必要なタスク vs 大量処理が必要なタスクの分類法
- 高付加価値タスク(Claude Opus 4.7 / Qwen3.6 Max): 新規機能のアーキテクチャ設計、複雑なリファクタリング
- ルーチンタスク(Qwen3.6 Plus/Flash): 単純な関数作成、ユニットテストの自動生成、ログの分析
まずは「Flash」から試す!今日から始めるAPIエンドポイントの切り替え
まずは、現在利用しているAIエージェントのうち、特にコストがかかっている「定型処理」の一部をQwen3.6 Flashに切り替えてみてください。数時間でそのコスト差を実感できるはずです。
関連記事:【2026年最新】生成AI料金比較!目的別おすすめツールとROIを最大化する選び方
まとめ
AIエージェントの運用コストを最適化し、かつ推論性能を損なわないための戦略をまとめました。
- コスト削減: Qwen3.6 PlusはClaude Opus 4.7の1/17のコストで利用可能。
- 適材適所: 高度な判断はMax、定型作業はFlashへとタスクをオフロードする。
- 精度向上: 「preserve_thinking」機能でエージェントの自己修正能力を高める。
- データ保護: OSS版(35B-A3B)を活用し、ローカル環境で安全に運用する。
まずは、現在利用中の開発環境にQwen3.6のAPIを設定し、一部のルーチンタスクを切り替えることから今すぐ始めてみてください。浮いた予算を、より創造的なDXプロジェクトへ回す準備を整えましょう。


