
Gemma 4比較|Qwen 3.6との性能差とローカル環境構築の秘訣
 AIエージェントナビ編集部
AIエージェントナビ編集部
社内の機密データを外部のクラウドに送信することなく、高性能なAIを活用したいと考える企業が増えています。しかし、ローカルLLM(大規模言語モデル)の環境構築には、モデルの選定やハードウェアの制約という高い壁が存在します。
本記事では、2026年5月時点の最新モデル「Gemma 4」と競合の「Qwen 3.6」を比較し、失敗しないための環境構築手順と高速化の秘訣を解説します。
この記事に対する編集部の見解
- Gemma 4は速度・軽量さとGoogle製品との親和性が強み・汎用事務や社内チャットに最適
- Qwen 3.6は日本語専門用語への強さと動画まで対応するマルチモーダル性能が最大の強み
- 専門文書の分析はQwen・スピード重視の日常業務はGemmaという用途別の使い分けが基本
目次
Gemma 4 vs Qwen 3.6比較
ローカルLLMを選定する際は、単にベンチマークスコアを見るのではなく、自社の業務に最適なモデルを選択することが重要です。
企業導入の法的・戦略的利点
Gemma 4はGoogleが提供するオープンなモデルであり、Apache 2.0ライセンスを採用しています。これは商用利用が認められているだけでなく、モデルの改変や再配布が極めて自由であることを意味します。企業の知的財産を守りつつ、自社専用のファインチューニング(追加学習)を自由に行える点は、クローズドなモデルにはない強力なアドバンテージです。
性能比較表
| 比較項目 | Gemma 4 | Qwen 3.6 |
|---|---|---|
| 推論速度 | 高速(軽量化に最適) | 標準的(多言語特化) |
| 日本語精度 | 高い(自然な文章) | 非常に高い(専門用語に強い) |
| マルチモーダル | 優秀(画像・音声対応) | 非常に優秀(動画対応) |
| ライセンス | Apache 2.0(商用可) | Apache 2.0(商用可) |
モデルスペックの選び方
以下の3つのパターンから、自社に合うモデルを選択してください。
- 汎用事務・社内チャット: 速度を重視した「Gemma 4 Flash」クラス
- 専門文書の分析: 推論能力が高い「Gemma 4 Pro」クラス
- 高度な画像・データ解析: マルチモーダル性能に優れた「Qwen 3.6 Max」クラス
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説

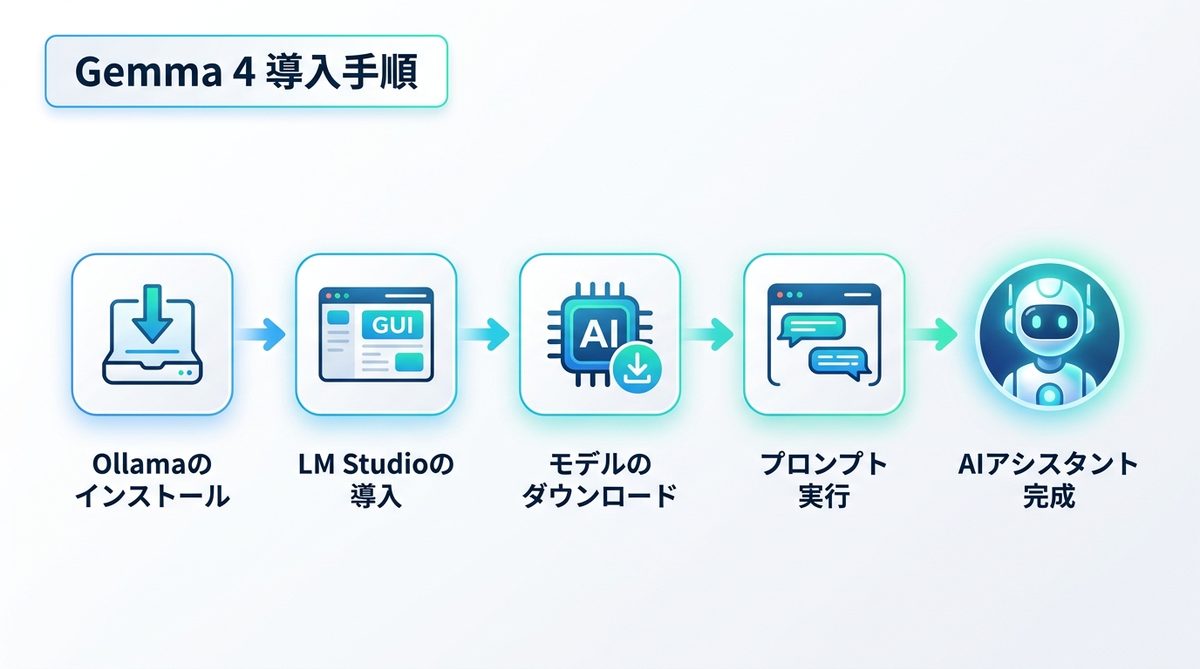
Gemma 4の導入手順
ローカル環境の構築には、専門知識がなくても導入可能なツールを活用するのが近道です。
環境構築の手順
- Ollamaのインストール: Ollama公式サイトからインストーラーをダウンロードし実行します。
- LM Studioの導入: GUIでモデル管理が可能な「LM Studio」をインストールします。
- モデルのダウンロード: 検索窓に「Gemma 4」と入力し、推奨モデルを選択してダウンロードを開始します。
モデル導入と実行方法
ダウンロード完了後、LM Studioのチャット画面で「こんにちは」と入力し、応答が返ってくれば環境構築は成功です。PC内に「優秀なAIアシスタントが住み着いた状態」が完成したことになります。
関連記事:【2026年版】ローカル生成AIの始め方|PCスペック判定表とおすすめソフト徹底解説
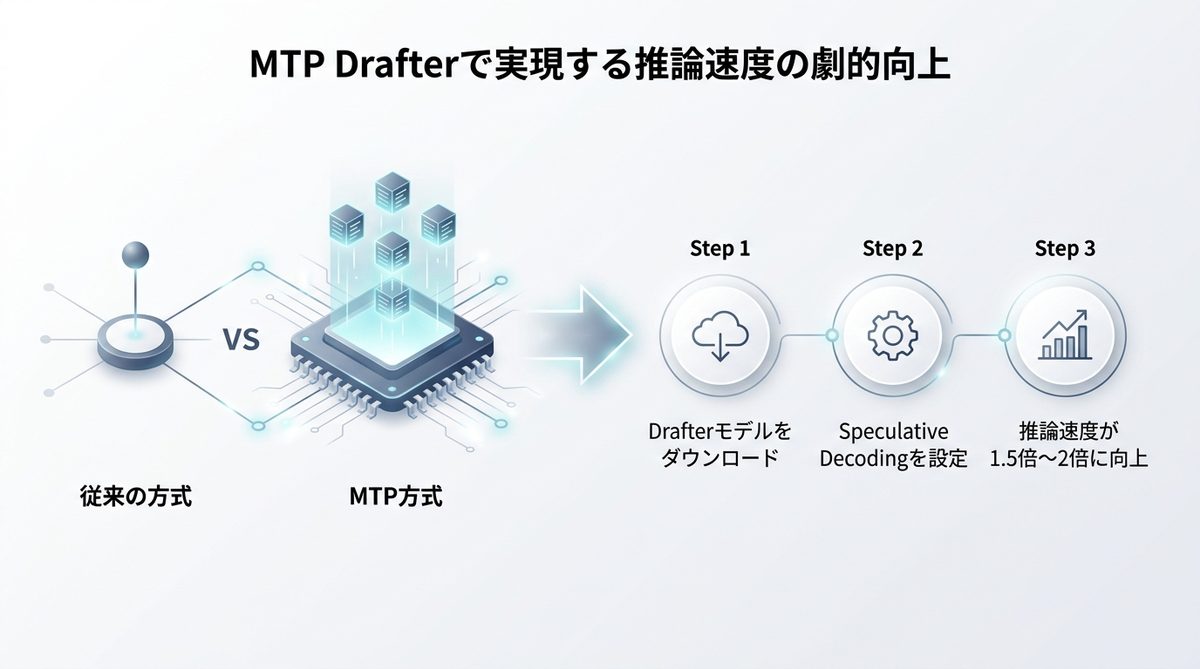
MTPで推論速度を劇的向上
ローカルLLMの最大の課題である「応答速度」を飛躍的に高める技術がMTPです。
MTPの仕組み
従来のLLMは、1単語ずつ時間をかけて生成していました。これに対しMTPは、一度に複数の単語を先読みして予測する仕組みです。いわば「熟練のタイピストが、文章の先を読みながら先回りしてキーボードを叩く」ような状態になり、推論速度が劇的に向上します。
Drafter最適化設定
- Gemma 4専用の「Drafterモデル」をダウンロードします。
- LM Studioの詳細設定(Speculative Decoding)項目を開きます。
- Drafterモデルを読み込ませることで、推論の出力速度が1.5倍から2倍程度向上します。
関連記事:【比較検証】Gemma 4とGemma 3の違いを解説|自社専用モデル構築の選定基準と4つのモデルサイズ
現場のハードウェアと対処法
導入後に陥りやすいトラブルを未然に防ぐためのガイドです。
メモリ最適化基準
Gemma 4の26B(260億パラメータ)クラスのMoE(混合専門家)モデルを快適に動かすには、最低でも24GB以上のVRAM(ビデオメモリ)を搭載したGPUが必要です。メモリが不足すると、処理が極端に遅くなるか、システムがクラッシュします。
エラーのトラブル対応
- OOM(Out of Memory)エラー: モデルの量子化(精度を落として軽量化すること)を行い、メモリ消費量を抑えてください。
- 応答停止: 一度アプリケーションを再起動し、コンテキスト(記憶容量)の制限を調整してください。
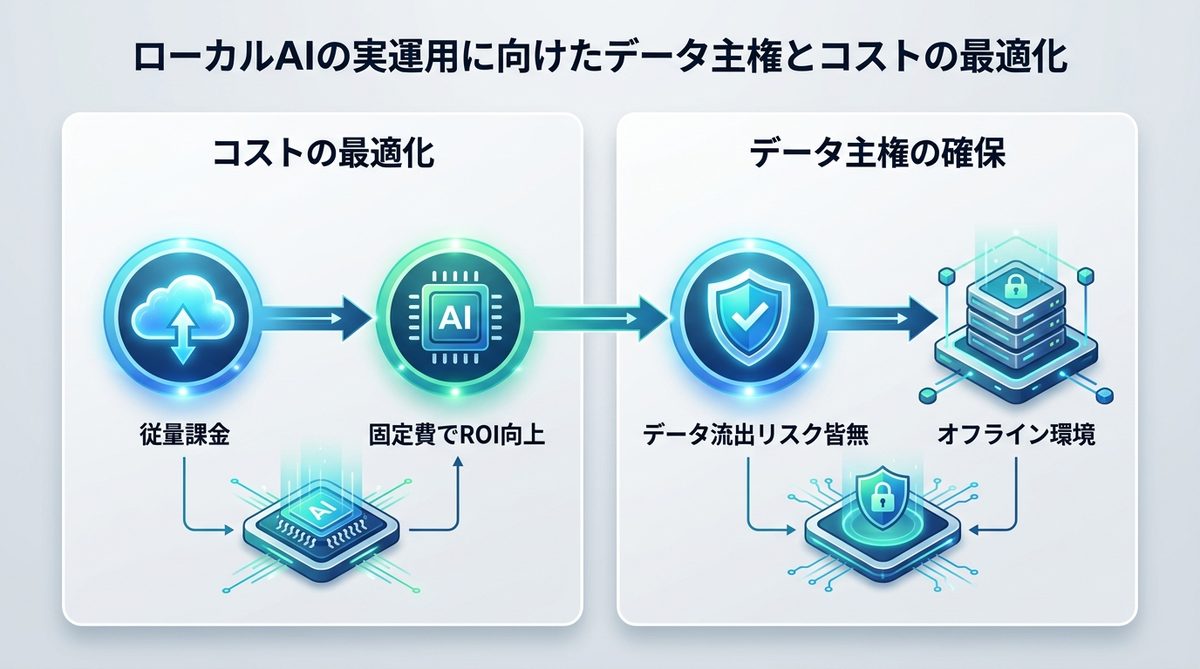
データ主権とコストの最適化
企業にとってのメリットはコスト削減だけではありません。
APIコストとROIの考え方
クラウドAPIの利用料は「従量課金」であるため、利用頻度が増えるほどコストが膨らみます。ローカルLLMであれば、初期のハードウェア投資のみで無制限に活用できるため、中長期的なROI(投資利益率)は非常に高くなります。詳細な料金は生成AI API料金比較を参照ください。
データ主権を守る意義
ローカルLLMはネットワークから遮断された環境で動作するため、外部へのデータ流出リスクが皆無です。機密性の高い議事録や顧客データの解析を安全に行える点は、経営上の強力な防衛策となります。
関連記事:【2026年最新】生成AI比較|企業導入を成功させる6つの選定軸と安全なガバナンス設計
まとめ|Gemma 4の業務効率化
Gemma 4を活用したローカル環境構築のポイントをまとめました。
- Gemma 4とQwen 3.6は用途に応じて使い分けることで最大効果を発揮する
- OllamaやLM Studioを使えば、専門家でなくても環境構築が可能
- MTP Drafterモデルを導入することで、推論速度を大幅に引き上げられる
- データ主権を守りつつ、従量課金コストを抑えた運用がビジネスの武器となる
今すぐ高性能なローカルLLMを構築し、社内データの活用を加速させましょう。まずはLM Studioのインストールから始めてみてください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- Gemma 4は速度・軽量さとGoogle製品との親和性が強み・汎用事務や社内チャットに最適
- Qwen 3.6は日本語専門用語への強さと動画まで対応するマルチモーダル性能が最大の強み
- 専門文書の分析はQwen・スピード重視の日常業務はGemmaという用途別の使い分けが基本
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


