
GPT-5.5 vs Opus 4.7の比較|特徴と選び方
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの導入が当たり前になった今、多くのDX責任者やエンジニアが「どのモデルを使えば、指示出しのコストを最小化できるのか」という悩みに直面しています。モデルの性能が向上する一方で、単純なAPIコストの比較だけでは見えない「タスク完遂までの手戻りコスト」が重要視されています。
本記事では、2026年4月時点における最強モデル、OpenAIの「GPT-5.5」とAnthropicの「Claude Opus 4.7」の特性を徹底比較し、自社のワークフローに合わせた最適な使い分けとコスト最適化の方針を解説します。
※本記事は2026年4月時点の情報です。その後2026年5月28日にAnthropicの「Claude Opus 4.8」、2026年7月9日にOpenAIの「GPT-5.6」ファミリーが公開されており、2026年7月時点の最新モデルはこちらです。
目次
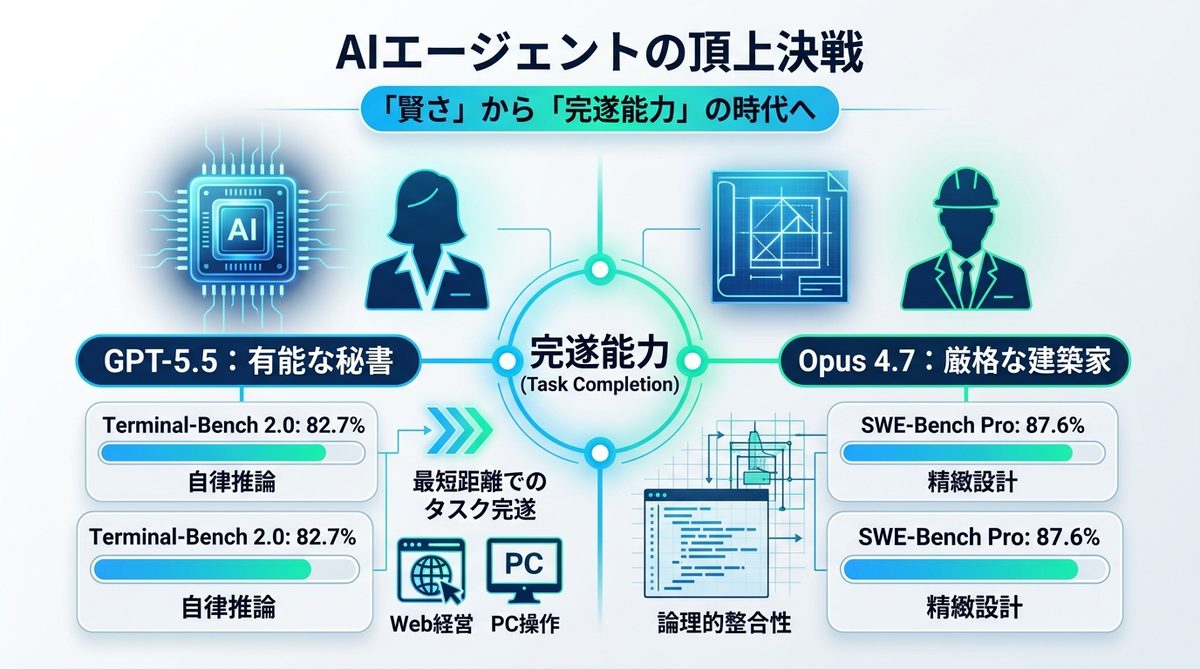
AIエージェントの頂上決戦|「賢さ」から「完遂能力」の時代へ
モデルの評価指標は、単純な回答精度から「どれだけ少ないステップで目的を達成できるか」という完遂能力へとシフトしています。
ベンチマークが示す2つの頂点
現在のトップモデルが、それぞれどのような領域に強みを持つのか。直近のベンチマーク結果は以下の通りです。
| 指標 | GPT-5.5 (自律推論) | Claude Opus 4.7 (精緻設計) |
|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% |
| SWE-Bench Pro | 78.2% | 87.6% |
「Terminal-Bench 2.0(環境操作の完遂度)」ではGPT-5.5が圧倒的な自律性を示し、一方で「SWE-Bench Pro(大規模リポジトリの修正能力)」ではOpus 4.7が極めて高い精度を誇ります。
擬人化で理解する両モデルの性質
両モデルの挙動を例えるなら、以下のようになります。
- GPT-5.5:有能な秘書
指示の背景を汲み取り、最短距離でタスクを完遂する高い「行動力」を備えています。PC画面を操作し、Webを巡回して情報をまとめるような業務に最適です。 - Opus 4.7:厳格な建築家
設計図の論理的整合性を最優先し、細部まで妥協しません。複雑なシステム構成や、バグが許されないコード修正において、持ち前の厳密さを発揮します。
関連記事:【徹底比較】Claude Opus 4.7 性能 比較レポート|GPT-5.4を凌駕する「自己検証能力」の衝撃
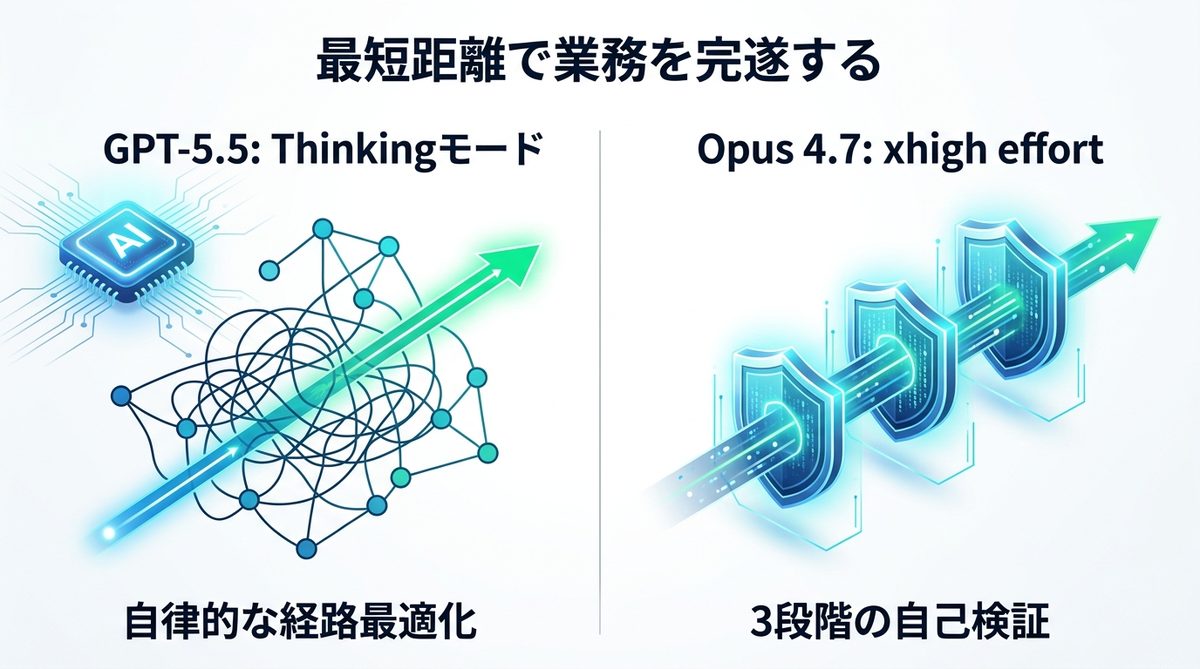
【シナリオ別比較】どちらが「最短距離」で業務を完遂できるか
エージェントの価値は、モデルがどれだけ自律的に、かつ修正回数少なくタスクを終わらせられるかで決まります。
GPT-5.5の「Thinkingモード」|曖昧な指示から最短経路を導き出す自律推論
GPT-5.5の最大の特徴は「Thinkingモード(動的推論)」です。これは、指示を受けた瞬間にAIが自ら計画の無駄を削ぎ落とし、成功確率の高いルートを再計算する機能です。「来週の市場調査をやっておいて」という曖昧なプロンプトでも、目的から逆算して必要なWebサイトを特定し、データを整理し終えるまでのプロセスを最適化します。
Opus 4.7の「xhigh effort」|3段階の自己検証で大規模リポジトリの欠陥を排除する厳密性
Opus 4.7の「xhigh effort(高負荷検証)」モードは、出力したコードに対して「論理的矛盾はないか」「依存関係に影響はないか」を自ら3段階でチェックします。これにより、大規模リポジトリの改修時、一度の実行で確実に品質を担保できるため、修正のやり直しを極限まで減らします。
関連記事:【徹底比較】Claude Opus 4.7と前世代4.6の違いとは?コスト増でも「監督コスト」を削減する3つの判断基準
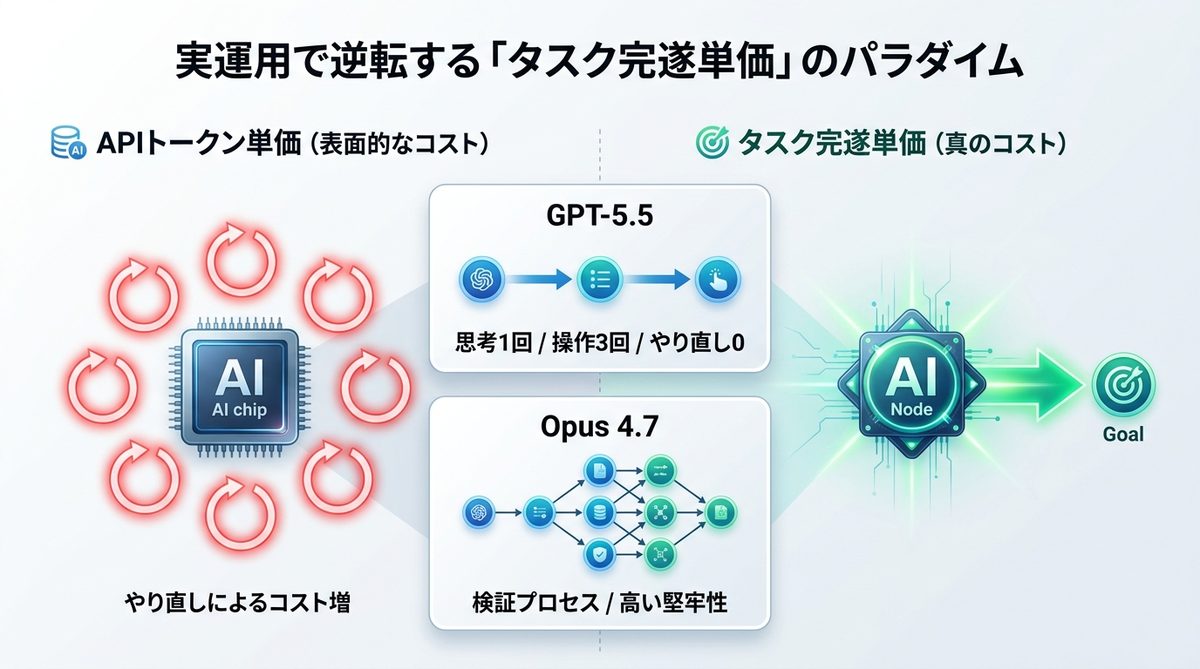
実運用で逆転する「タスク完遂単価」のパラダイム
APIのトークン単価(利用料)だけでモデルを選ぶのは危険です。エージェント運用においては「1つのタスクを終わらせるまでにいくらかかったか」という「タスク完遂単価」が全てです。
APIトークン単価の比較ではなく「やり直し回数」でコストを測る
例えば、安価なモデルを使って何度も「やり直し」が発生すれば、トータルコストは高くなります。逆に、高価なモデルでも一度で完璧に仕事を終わらせれば、最終的なコストは安くなります。
【検証データ】擬似APIログで見るタスク完遂までのコスト差
ある複雑なWebクローリングタスクでの比較ログをご覧ください。
- GPT-5.5: 思考ステップ1回、環境操作3回で完遂。やり直しなし。
- Opus 4.7: 思考ステップ3回(検証含む)、環境操作2回で完遂。検証プロセスにより「コードの堅牢性」は高いが、時間はやや長引く。
単発の事務作業はGPT-5.5、複雑な修正や長期間の運用が必要な設計業務はOpus 4.7というように、タスクの性質によって「やり直し」を避けるための最適解は変わります。
関連記事:【2026年最新】AIエージェントの料金比較|導入費用・隠れコスト・ROIの計算方法まで徹底解説
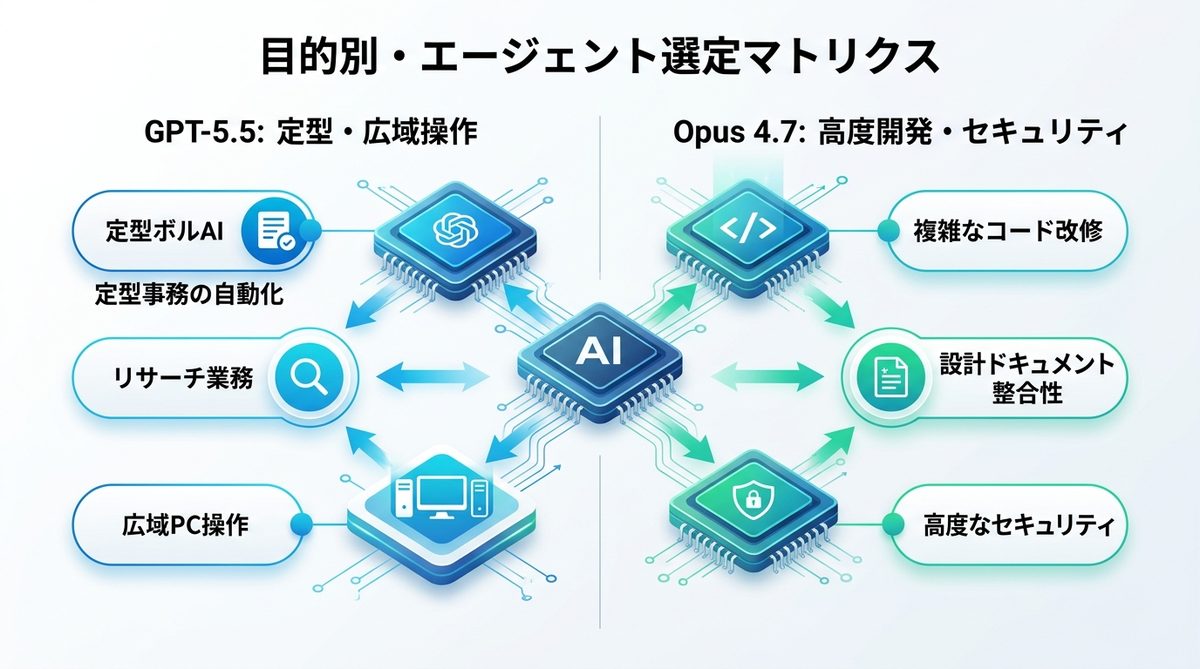
DX現場で迷わない!目的別・エージェント選定マトリクス
自社業務を以下の2つの基準で切り分け、モデルを選定しましょう。
GPT-5.5を選択すべき業務
- 定型事務の自動化:メールの整理、カレンダー管理など。
- リサーチ業務:競合調査、トレンド情報の要約。
- 広域PC操作:ブラウザ・ファイル・スプレッドシートを横断する作業。
Opus 4.7を選択すべき業務
- 複雑なコード改修:レガシーシステムの移行、大規模リファクタリング。
- 設計ドキュメントの整合性確認:仕様書とソースコードの齟齬チェック。
- 高度なセキュリティが求められる作業:機密性の高いプロセスの自動化。
組織への統合方針|Cursor・Claude Code等への具体的な組み込み方
適切なモデルを現在の開発・業務環境へ統合することで、生産性は飛躍的に向上します。
開発フローの最適化|「設計はOpus 4.7、実行はGPT-5.5」の併用戦略
CursorやClaude Codeを利用する際、設計フェーズではOpus 4.7を呼び出し、論理的ミスを徹底的に排除したコードベースを構築します。その後、テスト実行や軽微な調整、周辺ツールの操作についてはGPT-5.5の自律能力を活用することで、開発速度と品質を両立可能です。
非エンジニアの業務を自動化する|GPT-5.5を主軸とした自動化BOTの構築法
非エンジニア部門には、GPT-5.5の自律推論を活かしたエージェントBOTを配置しましょう。Thinkingモードにより「指示が少し曖昧でもAIが解釈して形にする」ことが可能なため、プロンプトエンジニアリングの学習コストを大幅に下げることができます。
関連記事:【2026年最新】AIエージェントおすすめ10選|MCP対応で実現する業務自動化の実装ロードマップ
まとめ
GPT-5.5とClaude Opus 4.7の特性を理解し、使い分けることで業務の自動化レベルは劇的に変わります。
- GPT-5.5は「自律的な完遂力」に長けており、PC操作を含む汎用業務に最適。
- Opus 4.7は「論理的な厳密性」を誇り、修正コストを減らしたい開発プロジェクトに必須。
- タスク完遂単価を意識し、やり直し回数を減らすことがコスト最適化の鍵。
- 設計にはOpus 4.7、実行にはGPT-5.5を組み合わせてハイブリッド運用を実現しましょう。
まずは現在のプロジェクトで「タスク完遂までに何回やり直しているか」を計測し、特性に合ったモデルへの置き換えを今すぐ検討してみましょう。


