
DeepSeek V4の100万トークン活用法|RAGと全投入を使い分ける最適戦略
 AIエージェントナビ編集部
AIエージェントナビ編集部
社内データの活用において「RAG(検索拡張生成)さえあればすべて解決する」と思い込んでいませんか。実は、膨大な資料を読み込ませる際の精度不足や、検索漏れに悩む現場が増えています。
本記事では、100万トークンの長コンテキストを武器にするDeepSeek V4を軸に、RAGと全投入を組み合わせた「ハイブリッド運用」の具体的な実装指針を解説します。
この記事に対する編集部の見解
- V4 FlashはAPI料金が1Mトークン約0.14ドルで大量処理・繰り返しタスクのコスト削減に向く
- V4 Proは複雑な推論・コーディング・エージェント判断など質が問われる用途に適している
- 長文コンテキスト合成はProが精度で優位だがコスト重視なら先にFlashで検証が現実的
目次
DeepSeek V4と100万トークンが変える実務
100万トークンの巨大図書館
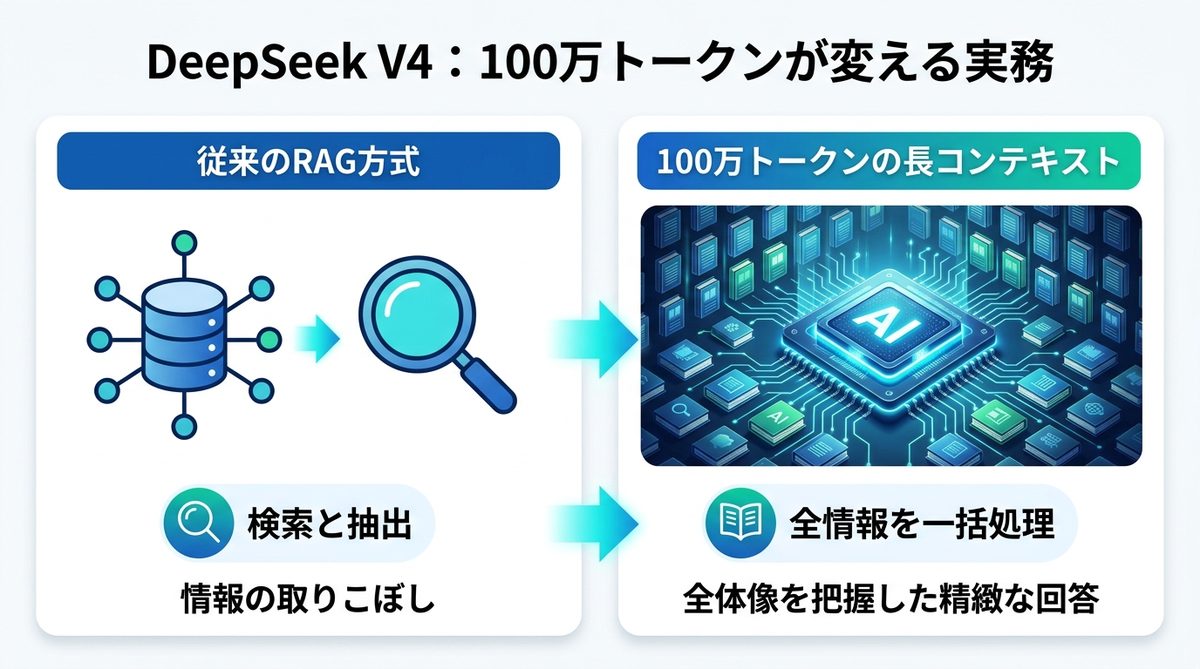
100万トークンという容量は、文庫本であれば約10冊分以上の情報を一度に読み込める計算です。これまでのAIが「辞書をめくりながら回答するアシスタント」だったとすれば、DeepSeek V4は「すべての資料を記憶した状態で即答する専属コンサルタント」がPCの中に住み着いた状態と言えます。
長コンテキストがRAGを補助する理由
従来のRAGは、ベクトルデータベースから必要な情報を検索して抽出し、AIに渡す手法です。しかし、検索の「取りこぼし」や、文脈の断片化が原因で誤回答を生むこともあります。今、長コンテキストを全投入することで、検索の手間を省きつつ、全体像を把握した精緻な回答を得る動きが主流になりつつあります。
関連記事:【2026年最新】MinerUを比較調査!RAGの精度が劇的に変わる「構造解析ツール」の最適解
RAG不要?ハイブリッド運用が最強の選択肢
RAGと全投入の境界と判断基準
「どちらを使うべきか」は、情報の性質と鮮度で判断します。
- 全投入が適しているケース
- 短期間で完了するプロジェクト資料の一括解析
- プログラミングのコードベース全体を理解させる必要がある場合
- 情報の関連性が高く、前後の文脈が重要な場合
- RAGが適しているケース
- 数万件に及ぶ過去の全社規程集からのピンポイント抽出
- 毎日更新されるニュースやログなどの「巨大かつ流動的なデータ」
ハイブリッドワークフローの活用
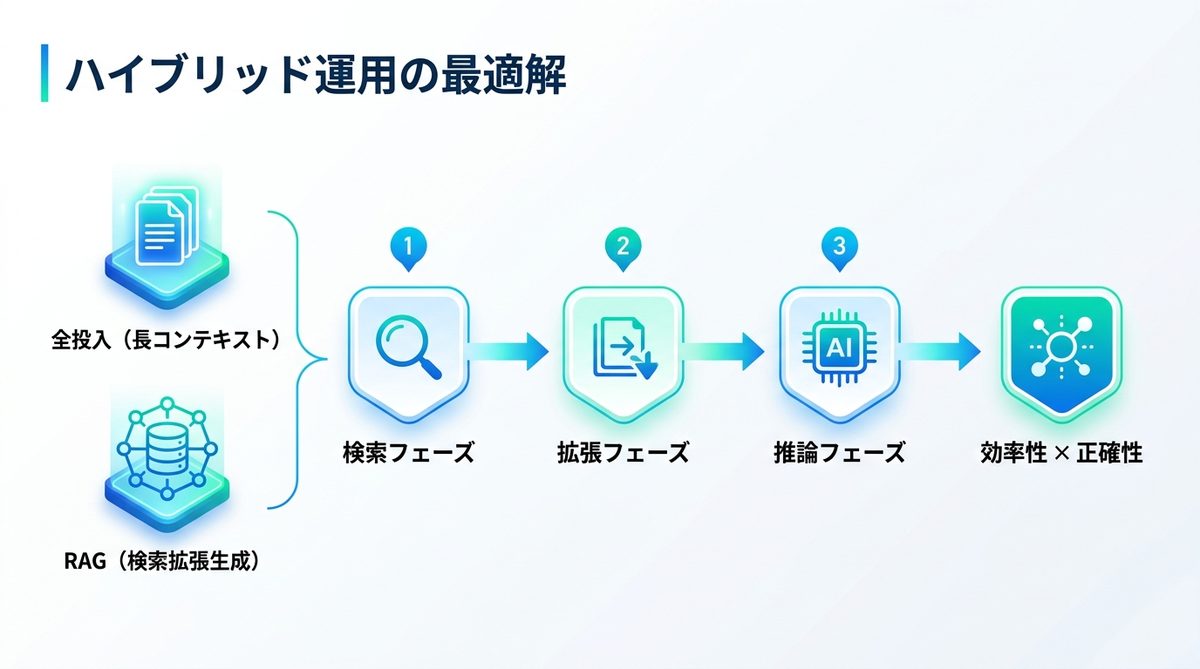
ハイブリッド運用では、まずRAGで「候補となるドキュメント」を絞り込み、最終的な精査をDeepSeek V4の長コンテキストで行う手法をとります。
- 検索フェーズ(LangChain/LlamaIndex):ベクトル検索で関連ドキュメントを抽出。
- 拡張フェーズ(Context Injection):抽出した情報をDeepSeek V4のコンテキストウィンドウに配置。
- 推論フェーズ(Reasoning):モデルが全データを統合して最終回答を生成。
この構成により、RAGの「効率性」と全投入の「正確性」を両立できます。
関連記事:【2026年最新】生成AI API導入の実戦ガイド|コスト・リスク・運用を最適化する実装戦略
DeepSeek V4 ProとFlashの比較と使い分け
API料金と推論コストの比較
DeepSeek V4は、圧倒的なコスト効率が特徴です。以下は主要モデルとの比較です。
| プロバイダー | モデル | 入力料金 (1Mトークン) | 出力料金 (1Mトークン) |
|---|---|---|---|
| DeepSeek | V4 Flash | $0.14 | $0.28 |
| DeepSeek | V4 Pro | $1.74 | $3.48 |
| Anthropic | Claude Sonnet 4.6 | $3.0 | $15.0 |
| OpenAI | GPT-5.4 | $2.5 | $15.0 |
ProとFlashの使い分け戦略
コストと精度のバランスを見極めるための戦略です。
- Flashの優先シーン:大量のデータ要約、単純な分類タスク、プロトタイプ検証。
- Proの優先シーン:複雑な論理構成が求められる分析、ミッションクリティカルなコード生成。
業務の初期段階でFlashを使い、最終的な出力にProを割り当てるステップを踏むことで、トータルコストを大幅に抑制可能です。
関連記事:【比較検証】Qwen3.5-OmniでAI活用を最適化!ビジネス現場での最適なモデル選定基準とは

長コンテキストの実務テクニックと回避策
サンドイッチ配置と構造化ルール
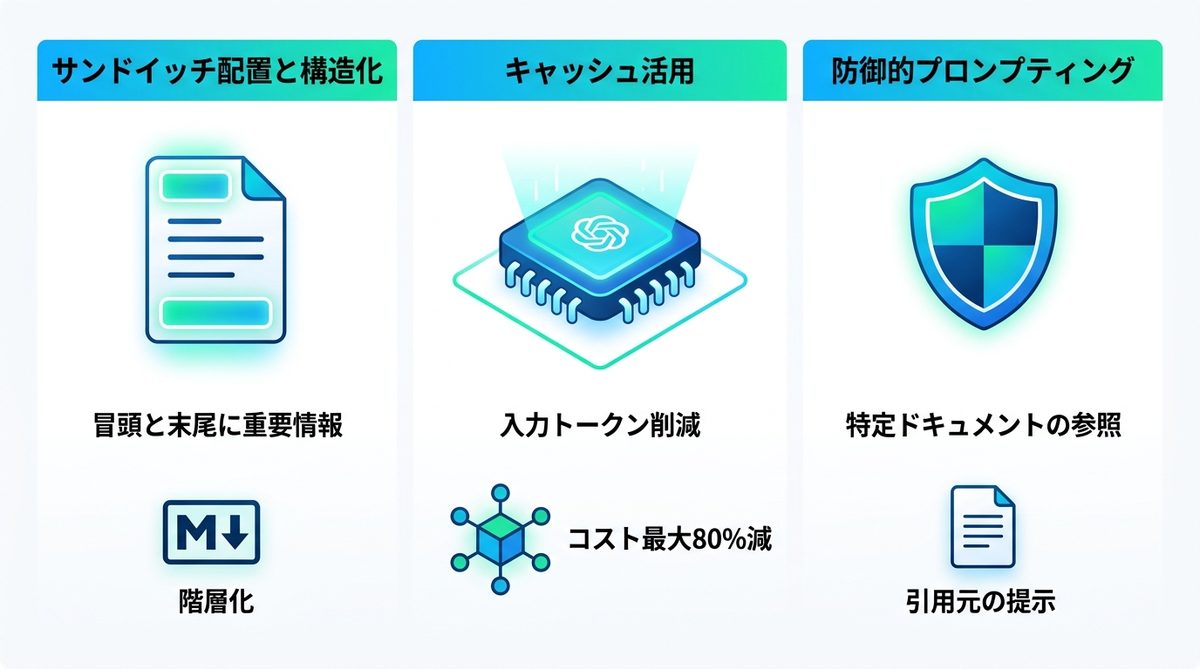
長大なコンテキストでは、中央部分の情報を忘れる「ロスト・イン・ザ・ミドル」という現象が発生しやすくなります。これを防ぐには以下の配置ルールを徹底してください。
- 冒頭と末尾に重要情報を配置:AIは最初と最後を強く認識する傾向があります。
- Markdownタイトルによる構造化:
#や##で階層を明確にすることで、AIの注意力を特定のセクションへ誘導します。
キャッシュ活用の実践フロー
共通のドキュメント(規程集やコーディング規約)はキャッシュとして保存しておくことで、入力トークン料金を削減できます。これにより、反復的なタスクにおいてコストを最大50%〜80%削減可能です。
情報の見落としを防ぐ具体策
「コンテキスト内の特定のドキュメントを必ず参照せよ」という制約をプロンプトに加えます。また、回答の最後に「参照した箇所の引用元を提示せよ」と命じることで、AIの hallucination(もっともらしい嘘)を抑制します。
関連記事:【GoogleのAI】NotebookLMとは?GeminiやAIブラウザとの違いを解説
DeepSeek V4の活用シーン
コードと法務文書の一括解析
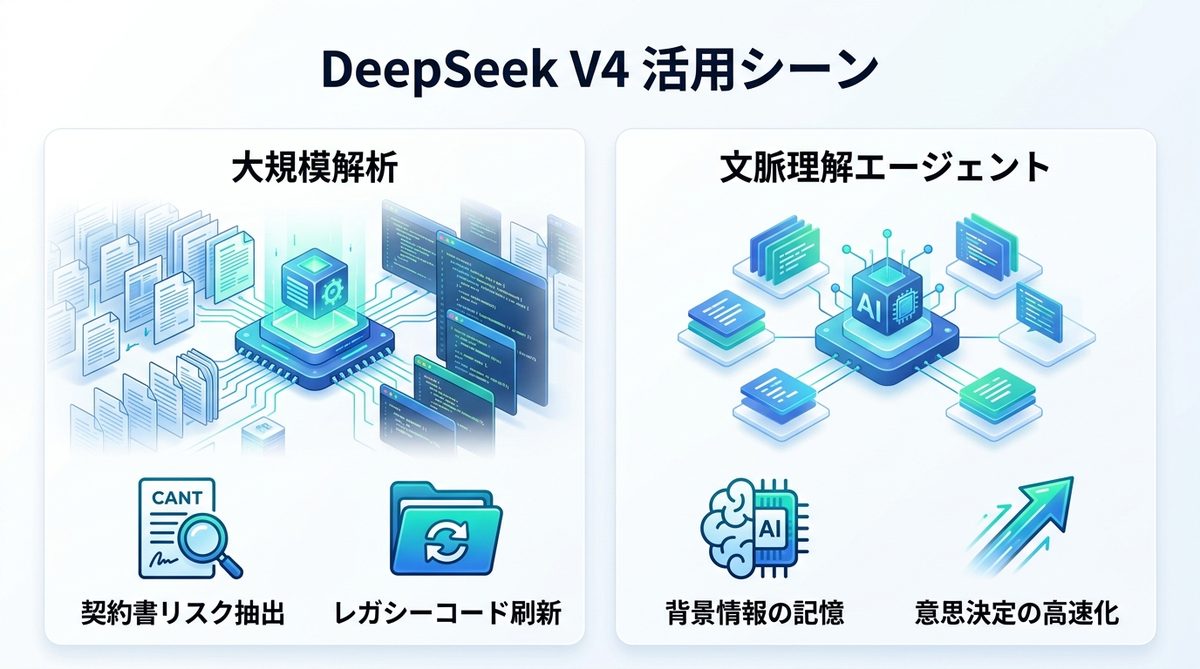
法務担当者が契約書チェックを行う際、過去の類似契約を全投入することで、リスク要因の網羅的な洗い出しが可能です。エンジニアにおいては、数百ファイルあるレガシーコードを一括で読み込ませ、リファクタリング(再構築)の提案を受けられます。
エージェントの構築事例
プロジェクトごとの背景情報を長コンテキストとして持たせることで、エージェントは文脈を理解した上で回答します。これにより、メンバーへの「前提説明」にかかる時間を短縮し、チーム全体の意思決定スピードを向上させます。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
まとめ|100万トークンでAI活用のROI最大化
本記事では、RAGと長コンテキストのハイブリッド運用について解説しました。
- RAGと全投入を使い分ける:検索の効率と全データの正確性をハイブリッド運用で統合する。
- DeepSeek V4でコスト最適化:FlashとProを目的別に使い分け、推論コストを大幅に削減する。
- ロスト・イン・ザ・ミドル対策:サンドイッチ配置や構造化で回答精度を担保する。
- キャッシュ活用:APIコストを抑えつつ、一括解析のスピードを加速させる。
まずは手元のプロジェクト資料をDeepSeek V4に読み込ませ、従来のRAGワークフローに「全投入」を組み込んでみてください。コストと精度のバランスが劇的に改善するはずです。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- V4 FlashはAPI料金が1Mトークン約0.14ドルで大量処理・繰り返しタスクのコスト削減に向く
- V4 Proは複雑な推論・コーディング・エージェント判断など質が問われる用途に適している
- 長文コンテキスト合成はProが精度で優位だがコスト重視なら先にFlashで検証が現実的
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


