
AIエージェントのベンチマーク活用術|6指標で測る実務適合性
 AIエージェントナビ編集部
AIエージェントナビ編集部
「AIエージェントのリーダーボードで1位のモデルを採用したのに、実務では使い物にならなかった」という経験はないでしょうか。公開されている性能スコアはあくまで基礎能力を示すものであり、自社特有の業務への適合性を保証するものではありません。
本記事では、公開ベンチマーク(性能評価の基準)と自社検証を組み合わせ、実務で成果を出すための「評価ハーネス(検証用テスト環境)」の構築手法を解説します。
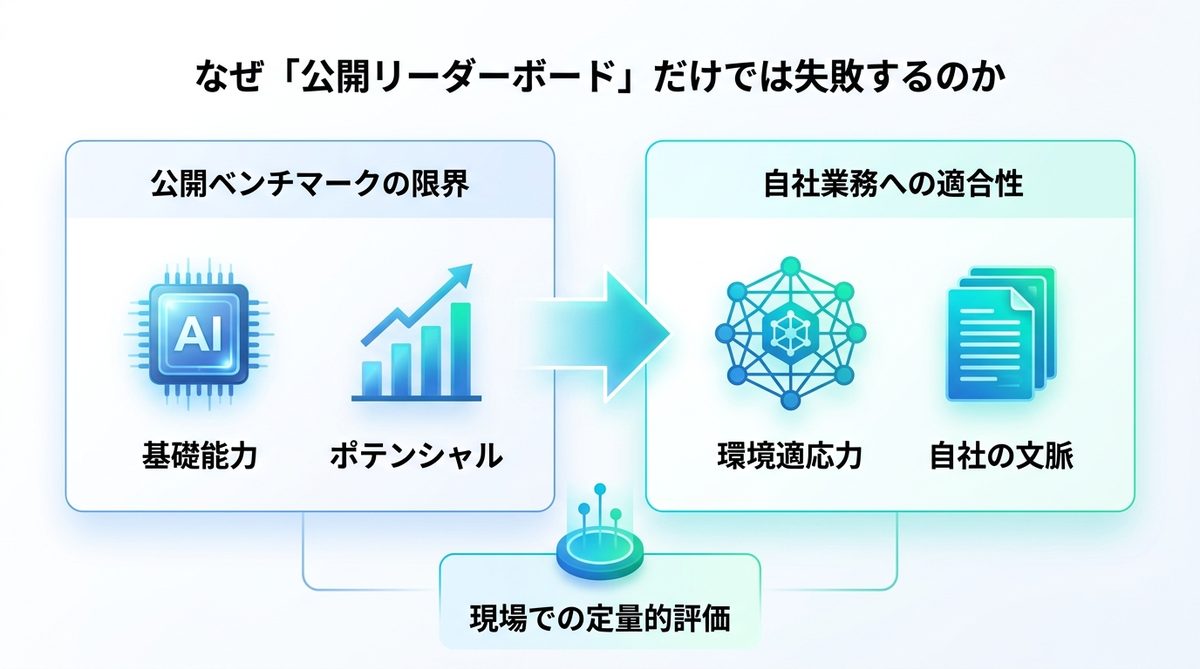
公開リーダーボードで導入に失敗する理由
多くの企業が陥る罠は、公開されている高い数値を「そのまま自社の業務効率」に直結させてしまうことです。しかし、汎用的なベンチマークと現場の実務は、似て非なるものなのです。
公開ベンチマークの限界
SWE-bench(ソフトウェアエンジニアリング能力を測る指標)やAgentBench(汎用推論能力の評価ツール)といった公開ベンチマークは、モデルの「ポテンシャル」を測るには最適です。しかし、これらは隔離された環境下での標準的なタスクに特化しており、社内ネットワークや独自のレガシーシステム、特有のドキュメントが絡む実務環境を考慮していません。
汎用性と業務適合性の違い
「賢さ」の定義は状況によって異なります。LLM(大規模言語モデル)がどれだけ高度なコードを書けても、自社のAPI仕様書を読み違えていれば業務効率は低下します。ベンチマークのスコアは「平均的な優秀さ」を指しますが、ビジネスで必要なのは「自社の文脈(コンテキスト)を理解する専門性」なのです。
環境適応力の重要性
AIエージェントの実装において重要なのは、複雑な推論能力よりも、環境適応力(ツールや社内データとの親和性)です。現場で成果を出すためには、公開スコアを鵜呑みにせず、自社の環境で「何が失敗し、何が成功したか」を定量的(数値的)に追跡する仕組みが不可欠です。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説
AIエージェント評価の6つの主要メトリクス
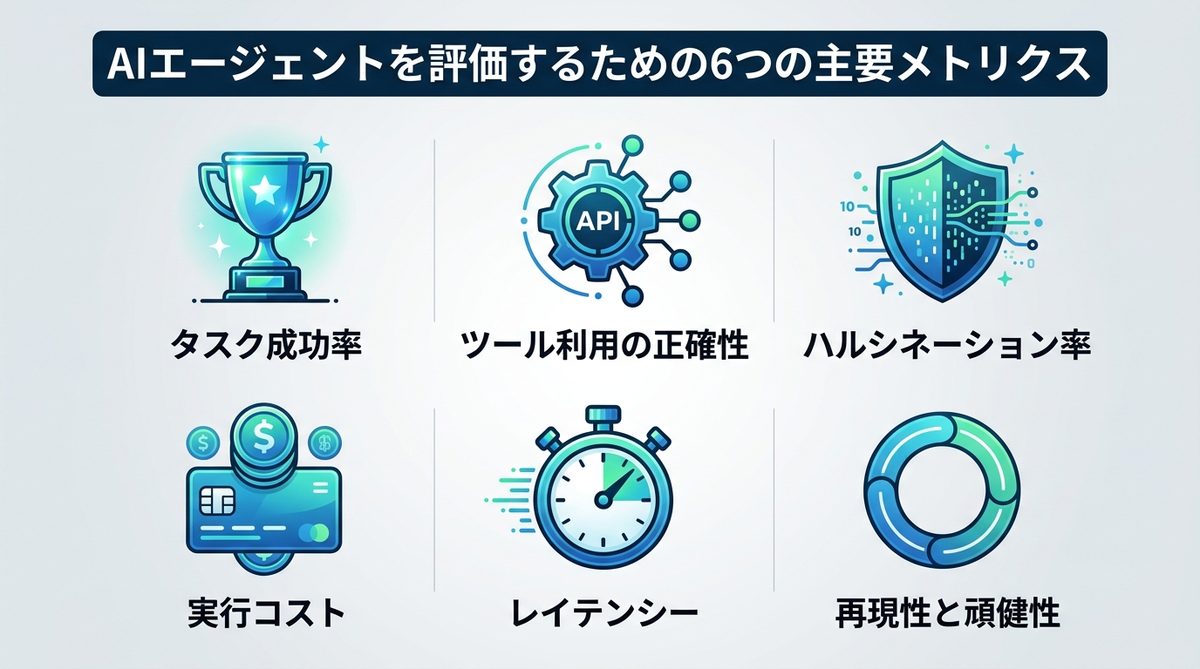
エージェントのパフォーマンスを客観的に測定するためには、以下の6つのメトリクス(評価指標)を軸に評価環境を整える必要があります。
| 指標名 | 測定の目的 |
|---|---|
| 1. タスク成功率 | ゴールに正しく到達したか |
| 2. ツール利用の正確性 | 外部APIや関数を適切に呼び出せているか |
| 3. ハルシネーション率 | 事実に基づかない誤情報を生成していないか |
| 4. 実行コスト | タスク完了までにいくらのAPI費用がかかったか |
| 5. レイテンシー | 回答までの待機時間は許容範囲内か |
| 6. 再現性と頑健性 | 同じ条件で何度実行しても同じ結果が得られるか |
これらの指標を継続的に追跡することで、AIの導入が「コスト削減」や「業務時間の短縮」に直結しているかを明確に判断できます。
関連記事:【2026年最新】AIエージェントの料金比較|導入費用・隠れコスト・ROIの計算方法まで徹底解説
LLM-as-a-Judgeによる評価の効率化
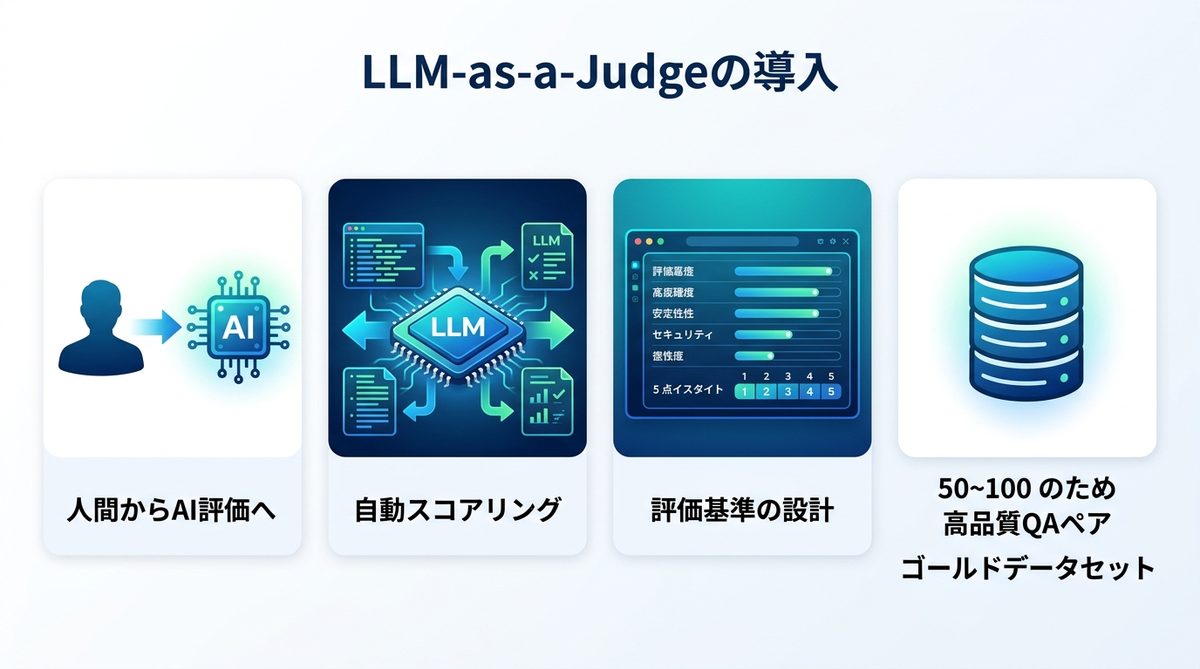
AIエージェントの評価を人間がすべて行うのは、コスト的にもスピード的にも現実的ではありません。そこで注目されているのが、LLM-as-a-Judge(AIに別のAIを評価させる手法)です。
LLM自動評価の仕組み
高性能なLLMを「評価者」として設定し、エージェントが生成した回答や行動ログを自動的にスコアリングさせる手法です。これにより、膨大な検証テストを高速かつ低コストで回すことが可能になります。
評価コストを抑えるプロンプト設計
評価用のLLMには、「期待される成果物」の条件と「評価基準」を明確に記述したプロンプト(命令文)を与えます。例えば、「コードの正確性」「コメントの記述量」「セキュリティ規定の遵守」の3項目で5段階評価させるなど、ルールを厳格化することで精度の高い評価が得られます。
ゴールドデータセット作成手順
評価の精度を担保するには、自社業務の過去データから「正解」となるゴールドデータセット(教師用データ)を作成することが重要です。「どの質問に対し、どのツールを使って、どのような結果を出すのが正解か」というQAペアを少なくとも50〜100セット蓄積することから始めましょう。
関連記事:【2026年最新】AIエージェント一覧|目的別に機能とツールを徹底比較
主要ベンチマークの選定と使い分け
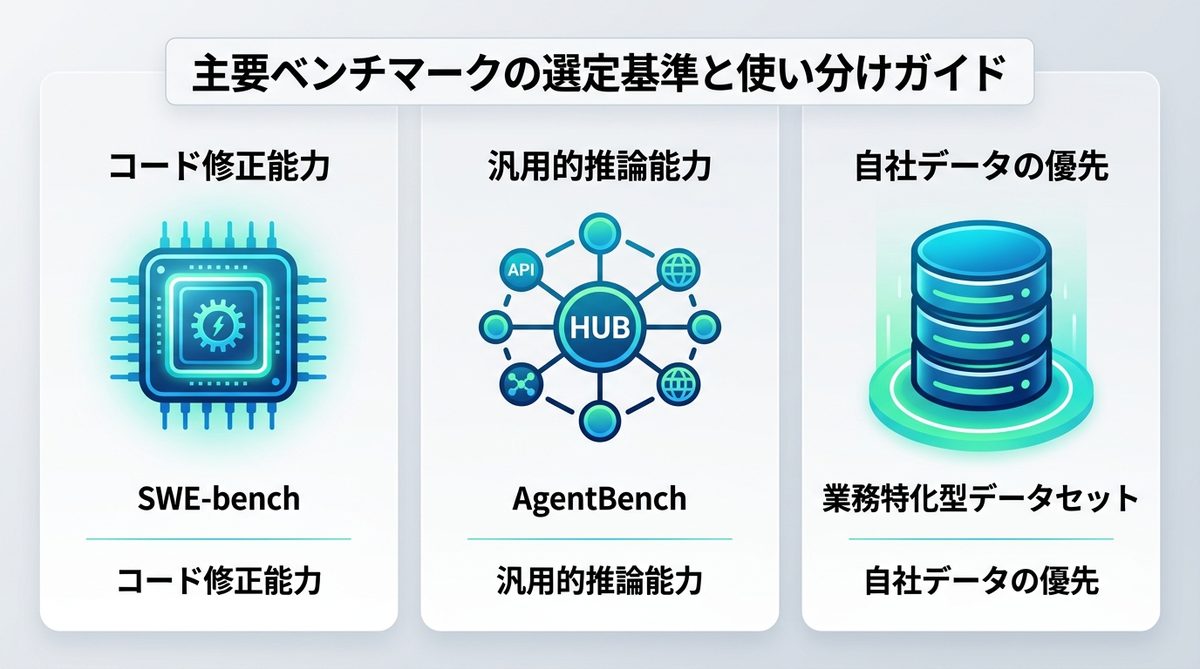
既存のベンチマークは、AIの特性によって使い分けるのが鉄則です。
- SWE-bench: 複雑なリポジトリ操作やコード修正能力を検証する場合に使用します。開発支援エージェントの導入時に必須の指標です。
- AgentBench: API呼び出し、Web閲覧、データベース操作など、汎用的な推論能力を多角的に評価する場合に適しています。
- 業務特化型データセット: 上記はあくまで「基礎体力測定」です。自社の業務プロセスに合わせた評価には、必ず社内データから抽出した独自のテストケースを優先してください。
関連記事:【2026年最新】AIエージェントおすすめ10選|MCP対応で実現する業務自動化の実装ロードマップ
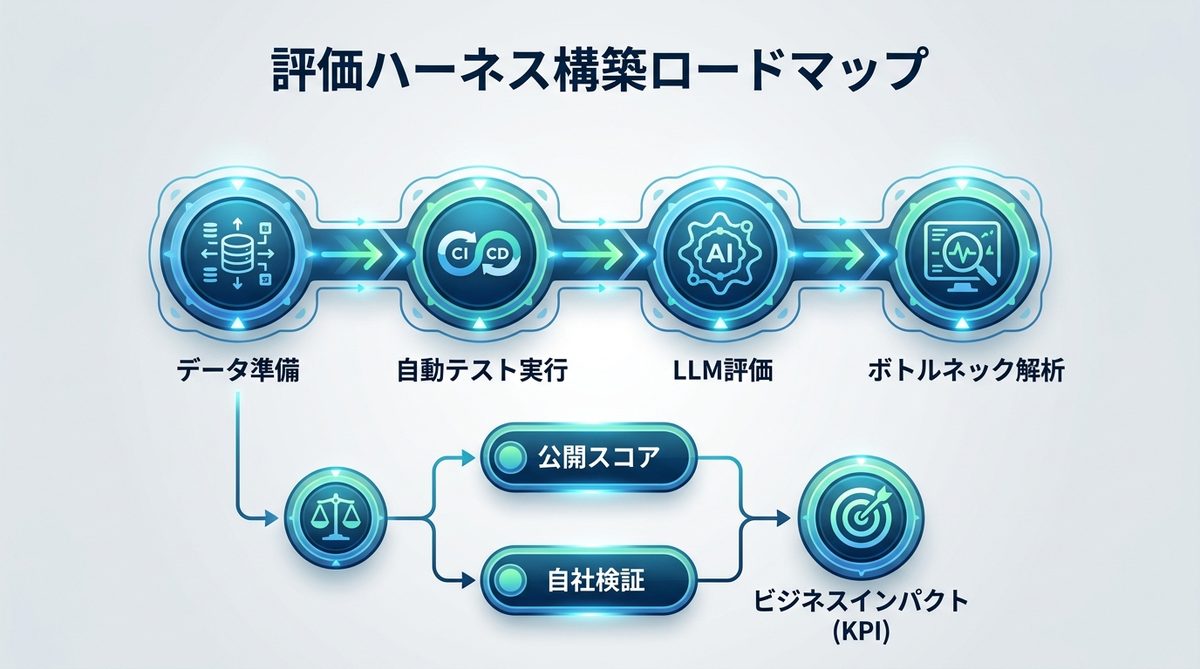
評価ハーネスの構築ロードマップ
最後に、実務で運用可能な検証パイプライン(一連の自動化フロー)を構築するステップを解説します。
検証パイプラインの自動化
- データ準備: 業務で頻出するタスクを抽出し、テストケース(検証用データ)化する
- 自動テスト実行: CI/CD(継続的インテグレーション/デリバリー)環境に組み込み、コード変更のたびにテストを回す
- LLM評価: LLM-as-a-Judgeを用いて、結果を自動でスコアリングする
- ボトルネック解析: 失敗したケースのログを分析し、エージェントの指示(システムプロンプト)を修正する
公開スコアと自社検証の判断フロー
公開スコアは「モデルの選定」という初期フィルタリングに使い、自社検証は「導入後の継続改善」に使うのが定石です。公開スコアが高いものをベースに選び、自社データでの評価で基準を超えたものだけを本番運用へ昇格させましょう。
KPIに紐づく評価設定
最終的には、「週20時間の工数削減」「回答精度の95%以上維持」といった自社のKPI(重要業績評価指標)と検証結果を紐づけます。ベンチマークの数値そのものではなく、AIを導入した結果、ビジネスインパクトがどれだけ出たかを追うことが成功の鍵です。
関連記事:【2026年最新】生成AI料金比較!目的別おすすめツールとROIを最大化する選び方
まとめ
AIエージェントの評価において、公開データはあくまで目安に過ぎません。以下のポイントを意識して、自社専用の検証体制を構築しましょう。
- 公開ベンチマークはモデルの基礎能力を確認するために使う
- 実務への適合性は、必ず自社データを用いた独自のテストで判断する
- 6つの主要メトリクス(成功率、コスト等)を定量的に追跡する
- LLM-as-a-Judgeを活用し、評価プロセスを自動化・高速化する
- ベンチマークの結果をビジネスKPIの改善に直結させる
まずは、現在最も手のかかっている業務を1つ選び、小さなテストケースから自動検証を始めてみてください。自社業務に最適化された評価環境こそが、AI導入成功への最短ルートです。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


