
AIエージェント論文で学ぶ技術選定と実装フレームワーク
 AIエージェントナビ編集部
AIエージェントナビ編集部
自社サービスへのAIエージェント導入を検討する際、日々発表される膨大な論文や技術トレンドの海で「結局、自社には何が必要なのか」と迷うことはありませんか。技術が急速に進化する今、過去の概念ではなく、最新の一次文献や標準仕様に基づいた設計が不可欠です。
本記事では、エンジニアや技術企画担当者がAIエージェントのアーキテクチャを決定し、実業務へ実装するための選定フレームワークと調査プロセスを解説します。
この記事に対する編集部の見解
- 論文の主流は「1つの万能AI」より「役割分担したチーム型AI(A2A)」への移行
- ベンチマークスコアは実業務の複雑さを反映しない。現場の完遂率とは別物と理解すべき
- 全自動より「AIが迷ったら人間に確認するHITL設計」の方が現場での安定性が高い
目次
AIエージェント設計:対話型からA2Aへ
エージェント開発は今、単一のモデルが指示を待つ「対話型」から、複数のエージェントが自律的に連携するステージへ移行しています。
論文が実務の羅針盤となる理由
AIエージェント分野では数週間単位でパラダイムシフトが起こります。ブログ記事やSNSの要約情報は便利ですが、信頼性と詳細な実装ロジックが欠如しているケースも少なくありません。公式論文やGitHubで公開される仕様書は、技術の根拠となる「一次情報」であり、自社のアーキテクチャに組み込む際の設計指針を正確に読み解くための唯一の羅針盤となります。
論文が示すA2A連携の重要性
近年、大規模言語モデル(LLM)単体の性能向上だけでなく、複数のエージェントが役割を分担する「A2A(Agent-to-Agent:エージェント間連携)」の研究が加速しています。なぜ「最強の1体」ではなく、チームを編成するのでしょうか。それは、単一モデルでは処理できない複雑な長期タスクや、異なる専門知識の統合を可能にするためです。
関連記事:【AIエージェントの協調】オーケストレーションとは?DXを加速させる「AIの組織力」
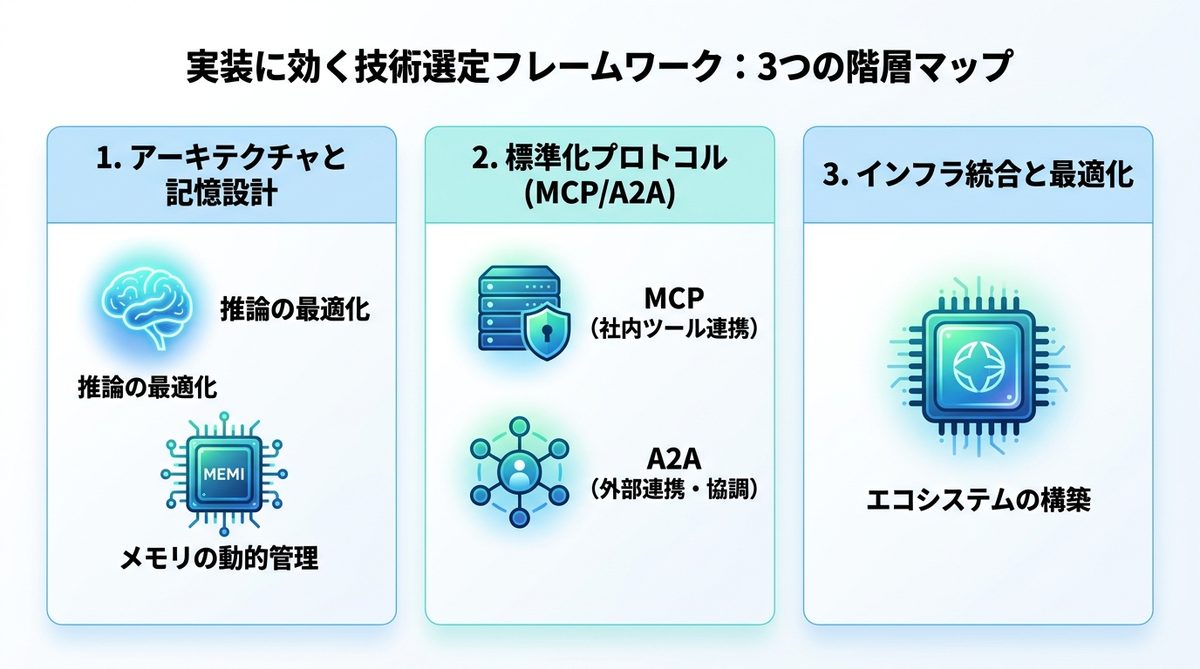
技術選定フレームワーク:3つの階層マップ
AIエージェントを構築する際、技術を以下の3階層で捉えることで、過不足のない設計が可能になります。
1. アーキテクチャと記憶設計(Memory & Reasoning)
エージェントの推論能力を左右する「推論(Reasoning)」と、過去の対話や文脈を保持する「メモリ設計」はシステムの心臓部です。論文から導き出せる主要な設計要素は以下の通りです。
- 推論の最適化: Chain-of-Thought(思考の連鎖)や自己修正フローの導入。
- メモリの動的管理: コンテキスト(記憶容量)の制限を考慮したRAG(検索拡張生成)とベクトルデータベースの活用。
標準化プロトコルによる統合
エージェントを孤立させないためには、共通言語(プロトコル)による連携が不可欠です。
| 分類 | 主な用途 | 目的 |
|---|---|---|
| MCP(Model Context Protocol) | 社内ツール連携 | ローカル環境や社内APIとの安全な接続 |
| A2A(Agent-to-Agent) | 外部連携・協調 | 異種モデル間のタスク受け渡し・協調 |
社内データの活用が最優先であればMCPを優先し、外部サービスとのエコシステムを構築するならA2Aインターフェースを意識した設計が最適解となります。
関連記事:MCPとRAGの違いとは?「知る」と「動く」を統合する業務自動化
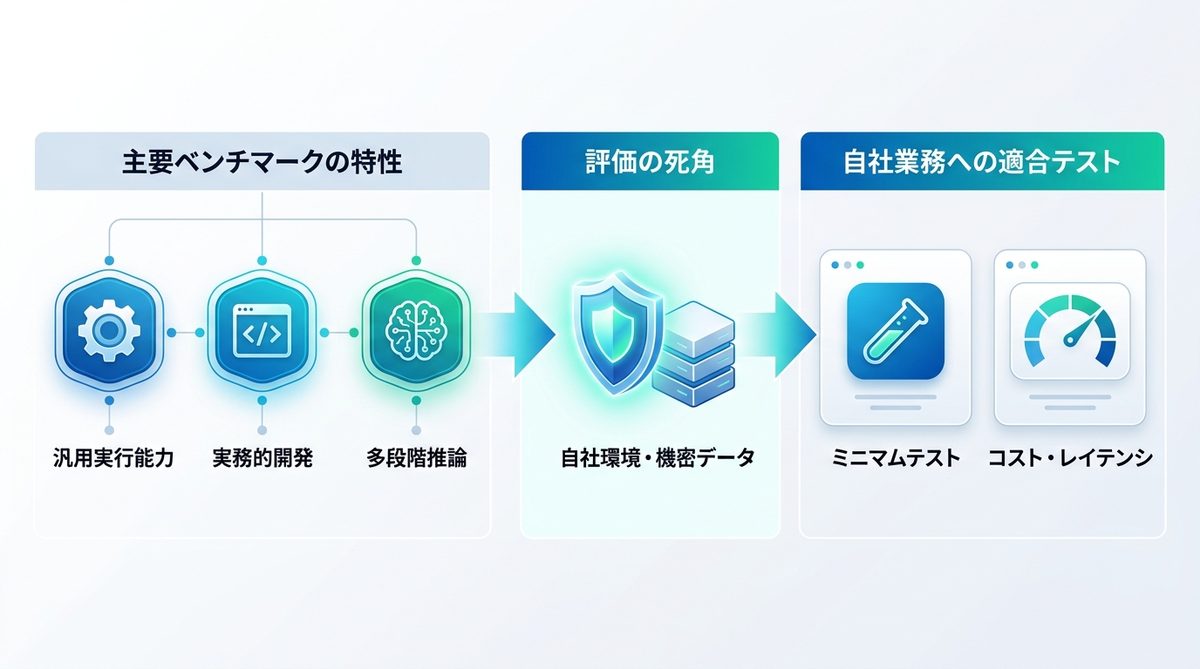
ベンチマーク指標の限界条件
最新のAIモデルを選択する際、リーダーボード(性能評価表)の数値に飛びついてはいけません。
評価指標の特徴と使い分け
主要な評価指標にはそれぞれ「得意な領域」と「死角」があります。
- AgentBench: エージェントの汎用的な実行能力を多角的に評価。
- SWE-bench: ソフトウェアエンジニアリング(GitHub上のIssue解決)に特化した実務的指標。
- GAIA: 人間にとっては容易だがAIには困難な、多段階の推論タスクを評価。
これらはあくまで「一般環境」でのスコアです。自社特有のレガシーシステムや機密データ環境での挙動を保証するものではないことに注意が必要です。
高スコアモデルの適合評価手法
論文の指標を過信せず、自社の業務データで「ミニマムテスト」を実施してください。ベンチマークで高得点のモデルが、自社の特定のAPI呼び出しにおいて最もコスト効率が高いとは限りません。まずは入出力のトークン料金や、タスク完遂までのレイテンシ(遅延時間)を自社指標で計測しましょう。
関連記事:【導入戦略】Qwen3.5-Omniとは?AIエージェントの処理遅延を解決する「ネイティブ」の衝撃
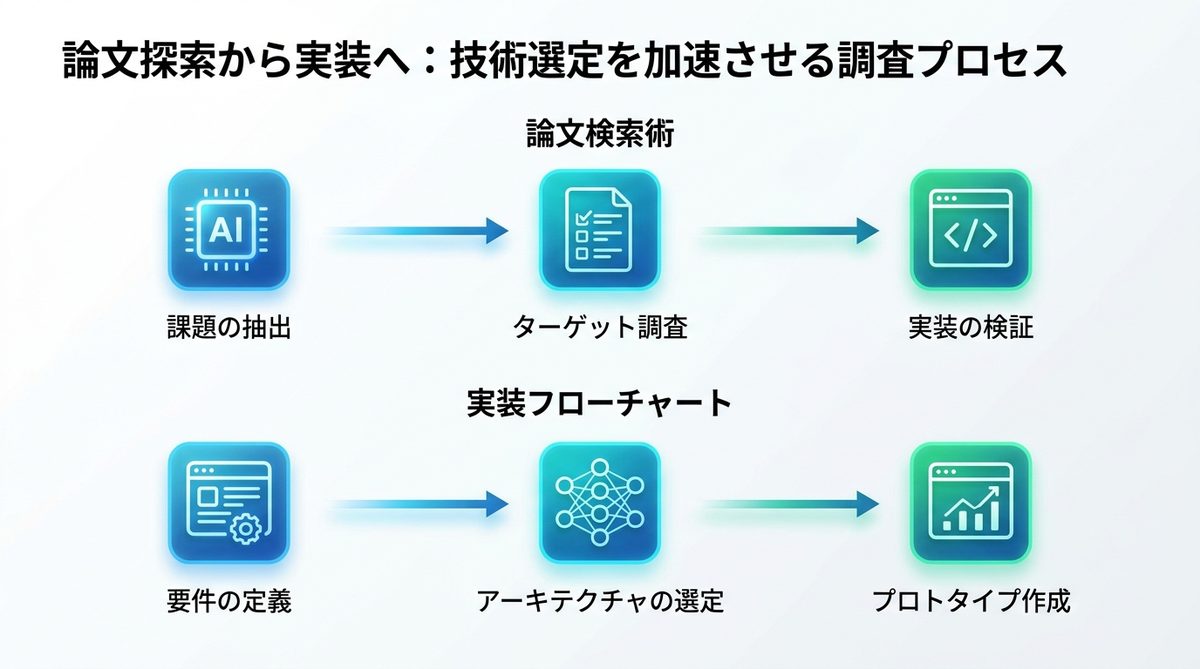
論文探索から実装への調査プロセス
効率的に最新技術を取り入れるための「調査術」を確立しましょう。
実装直結型の論文検索術
単に「AIエージェント」で検索するのではなく、以下のプロセスで調査を行います。
- 課題の抽出: 自社で解決したい課題を「推論・メモリ・連携」のどこに分類するか決める。
- ターゲット調査: Perplexity等で「[解決したい課題] + Agent Architecture + Survey」と検索し、最新のレビュー論文を特定する。
- 実装の検証: Elicitで関連文献を絞り込み、検証環境の構築コードが含まれているかを確認する。
導入判断の実装フロー
- 要件の定義: 外部システムとの連携が必要か(YesならMCP導入)。
- アーキテクチャの選定: 複雑な推論が必要か(YesならCoT等の推論手法を論文から実装)。
- プロトタイプ作成: 小規模なデータセットでベンチマークを実施し、コストを算出。
関連記事:【2026年最新】Claude Code MCP設定の完全ガイド|コマンド操作からスコープ管理まで
AIエージェントの未来:研究と社会実装
追うべき主要カンファレンス
以下の場では、論文の枠を超えた「実装コミュニティ」の動向が共有されます。
- NeurIPS / ICML: AI研究の最先端。
- GitHub / Discord: 特定のエージェントフレームワークのコミュニティ。公式ドキュメントより速い実装事例が流れることもあります。
実装開始のチェックリスト
- [ ] 解決すべきタスクの範囲を1つに限定したか
- [ ] 使用するモデルの入出力コストを確認したか
- [ ] MCP等の標準プロトコルに準拠しているか
- [ ] 評価用の独自テストデータを作成したか
関連記事:AIエージェントとは?概念から実装フェーズへ移行した2026年

まとめ
AIエージェントの技術選定においては、論文という一次情報を読み解き、自社のインフラに適した設計を行うことが成功の鍵です。
- パラダイムシフト: 対話型から自律的な連携(A2A)へ移行していることを理解する。
- 技術の階層化: アーキテクチャ、メモリ設計、標準プロトコル(MCP/A2A)の3層で整理する。
- 指標の解釈: ベンチマークは参考程度に留め、自社データでの検証を優先する。
- 調査の効率化: PerplexityやElicitを駆使して、実務直結型の情報を収集する。
まずは、現在抱えている業務タスクを一つ選び、MCP対応のツールを用いてプロトタイプを構築してみてください。今すぐ小さな成功体験を積み上げましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- 論文の主流は「1つの万能AI」より「役割分担したチーム型AI(A2A)」への移行
- ベンチマークスコアは実業務の複雑さを反映しない。現場の完遂率とは別物と理解すべき
- 全自動より「AIが迷ったら人間に確認するHITL設計」の方が現場での安定性が高い


