
AIエージェント開発用PCの最適解|NPU・GPU・RTX Sparkの判断基準
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの開発環境を構築しようとした際、最新のハードウェア選択に迷うビジネスパーソンやエンジニアは少なくありません。「結局、クラウドとローカルのどちらが良いのか?」「NPU搭載の最新PCは必要なのか?」といった疑問を抱えている方も多いでしょう。
本記事では、AIエージェント開発に最適なハードウェア環境の選び方を、開発規模と投資対効果の観点から徹底的に解説します。
この記事に対する編集部の見解
- 入門GPU(12〜16GB)は5〜15万円、本格スペック(32GB以上)は40〜50万円が目安
- AIエージェントを「使う」だけならGPUは不要。API経由が個人・中小企業の現実解
- 自社ホストが必要な大企業は社内GPUサーバー導入が2025年後半から主流に
目次
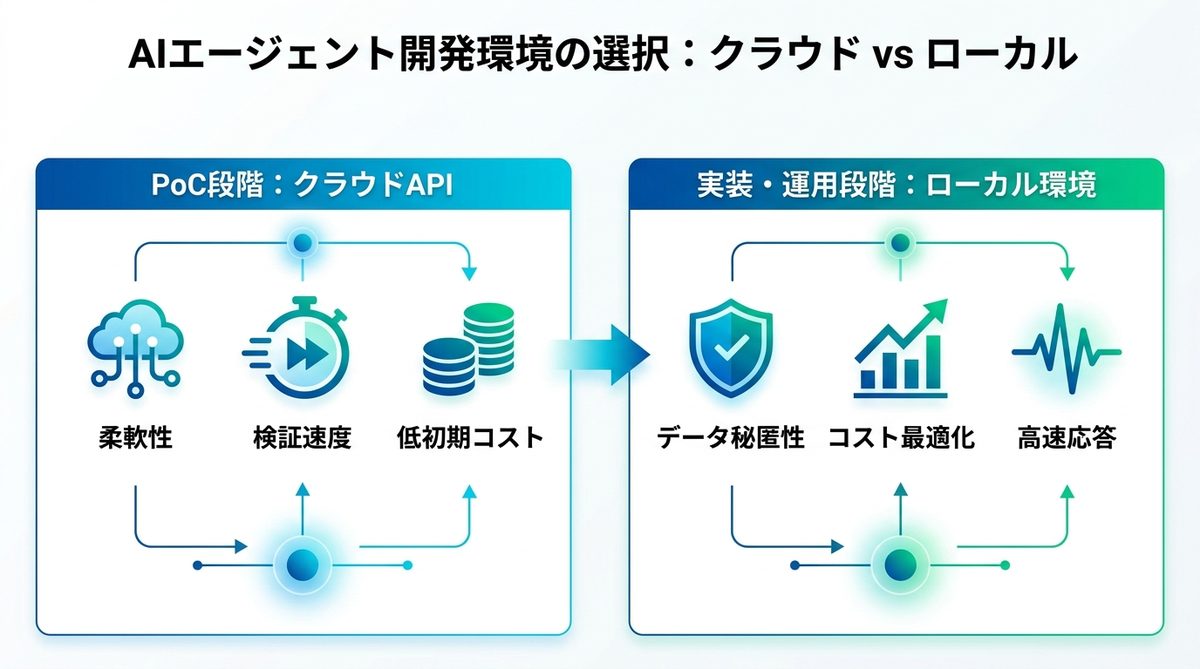
AI開発環境:クラウドか、ローカルか
AI開発における環境選びは、現在の「開発フェーズ」に合わせて柔軟に変えることが鉄則です。
PoCでクラウドAPIを選ぶ理由
開発の初期段階(PoC:概念実証)では、迷わずクラウドAPIを活用することをおすすめします。自前の高額なPCを購入する前に、まずはクラウド上でモデルの挙動やエージェントの推論精度を検証するのが最もコスト効率の高い方法だからです。
- 柔軟性: 必要な時に必要なだけ計算リソースを確保できる
- 検証速度: セットアップ時間を短縮し、すぐに開発に着手できる
- コスト: 開発の初期段階では、機材購入費よりもAPI使用料の方が安価に収まる
ローカル移行の判断基準
開発が進み、特定のAIエージェントを定常的に稼働させるフェーズに入った時点で、ローカル環境への移行を検討しましょう。特に「機密データの取り扱い」と「APIの継続利用コスト」が判断基準となります。
以下の状況に当てはまる場合は、ローカル環境への移行が推奨されます。
- データ秘匿性: 社外秘のドキュメントをエージェントに読み込ませる必要がある
- コストの最適化: 大規模な推論を頻繁に行う場合、API料金より電気代の方が安くなる損益分岐点を超える
- 応答速度: ネットワーク遅延を排除し、極限まで推論速度を上げる必要がある
関連記事:AIエージェントフレームワーク比較|本番運用に向けた選定ガイド
目的別スペック:NPU・GPU・RTX Spark
AI開発におけるハードウェアは、役割によって選ぶべきチップが明確に異なります。
NPUの役割と限界
近年のCopilot+ PCに搭載されているNPU(神経回路網プロセッサ)は、OSのバックグラウンド処理や軽量AIの省電力実行には優れていますが、自律型AIエージェントの構築には不十分です。NPUはあくまで補助的な役割であり、エージェントが複雑な推論を行うためのメインエンジンにはなり得ないことを理解しておきましょう。
GPUとRTX Sparkの優位性
AIエージェントの自律動作において重要なのは、GPU(画像処理ユニット)のパワーです。特に2026年6月現在、注目すべきは最新チップ「RTX Spark」です。
| チップ種別 | 主な役割 | AIエージェント適正 |
|---|---|---|
| NPU | OS最適化・軽量タスク | 低 |
| 汎用GPU | 一般的な学習・推論 | 中 |
| RTX Spark | エージェント実行・構築 | 高 |
RTX Sparkは、エージェントが必要とする「推論」と「外部ツール呼び出し」の最適化に特化しており、従来のGPUと比較して、マルチタスク環境での処理能力が大幅に強化されています。
モデル規模とVRAM容量
エージェントが使用するモデルのパラメータ数によって、必要なVRAM(ビデオメモリ)容量は以下のように変化します。
| モデル規模(パラメータ数) | 推奨VRAM容量 |
|---|---|
| 7B〜14B(軽量エージェント) | 12GB 〜 16GB |
| 30B〜70B(複雑な意思決定) | 24GB 〜 48GB |
| 100B以上(高度な自律エージェント) | 64GB以上(要複数枚) |
関連記事:【2026年最新】ローカルAIエージェントの作り方|Ollama×Open WebUIで完全オフライン構築

Windows vs Mac:メモリ技術の比較
OSの選択は、開発の「何に重きを置くか」で決まります。
Macユニファイドメモリの利点
Macの最大の強みは、CPUとGPUがメモリを共有する「ユニファイドメモリ(CPU・GPU共有メモリ)」構造にあります。これにより、大容量のLLM(大規模言語モデル)を効率的にVRAMへ読み込めるため、巨大なモデルを扱うエンジニアからの評価が極めて高いのが特徴です。特に開発環境としての安定性は、長時間のAI実行において強力な武器となります。
Windowsの推論速度と拡張性
一方で、Windows環境(RTX 50シリーズ搭載機)は、特定のAIライブラリへの最適化や、最新のRTX Sparkを活かした圧倒的な推論速度を求める場合に適しています。パーツの追加・交換による拡張性も高く、将来的なスペックアップも容易です。
関連記事:【初心者向け】Claude CodeをWSL2で最短構築!Windows環境の生産性を劇的に変える導入ロードマップ

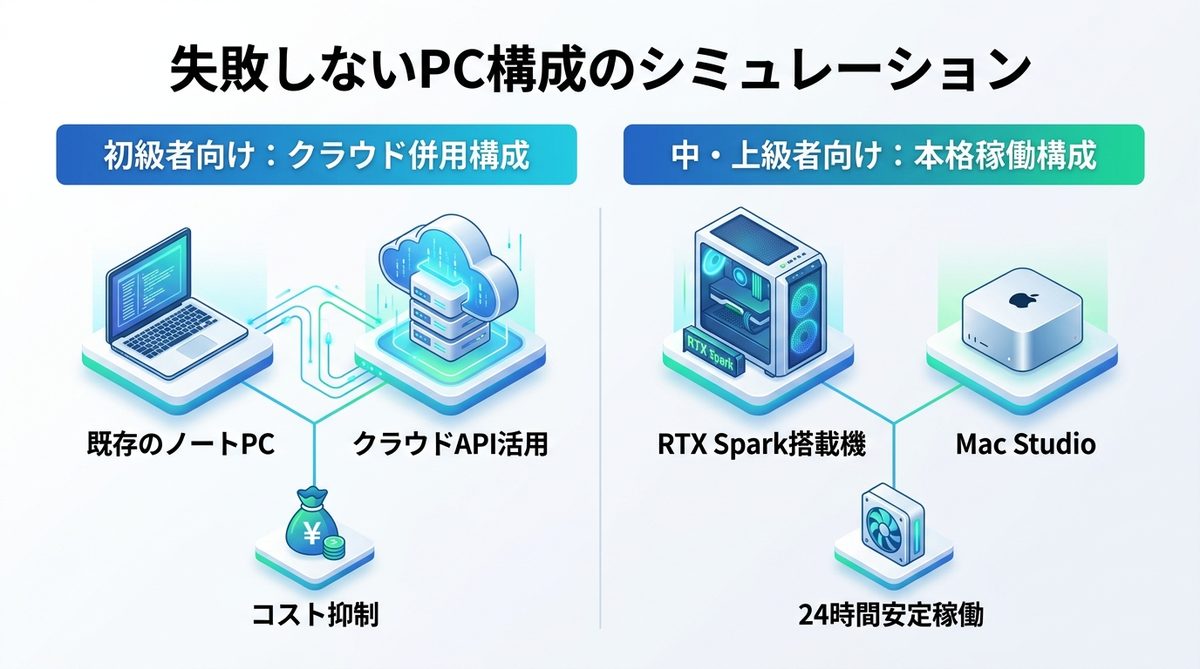
失敗しないPC構成シミュレーション
自身の目的に合わせた構成を検討しましょう。
初級:クラウド併用構成
まずは、既存のノートPCや最小限のGPU搭載PCでPoCを行い、クラウドAPIを賢く活用するハイブリッド構成がおすすめです。無理に高額な機材を買わず、API利用料を学習コストと割り切るのが賢い選択です。
中上級:RTX Spark・Mac構成
本格的な自律エージェントを24時間体制で稼働させるなら、RTX Spark搭載のWindowsワークステーション、あるいは大容量ユニファイドメモリを搭載したMac Studioが最適です。冷却効率を考慮したデスクトップ構成にすることで、長時間の高負荷推論でも安定したパフォーマンスを発揮します。
関連記事:【2026年最新】Claude Codeの始め方|開発を自動化する初期設定と運用Tips
まとめ:開発規模に合わせた環境選択
AIエージェント開発環境を成功させる要点をまとめます。
- フェーズで使い分ける: 初期はクラウドAPIを活用し、定常稼働段階でローカルPCへ移行する
- 役割を理解する: NPUは補助、GPU・RTX Sparkこそがエージェント構築のメインエンジン
- メモリの重要性: モデルのパラメータ数に合わせ、VRAM容量を最優先で確保する
- MacかWindowsか: 大容量LLMならMac、推論速度と拡張性ならWindowsを選ぶ
最初から最高スペックを追い求める必要はありません。まずはクラウドでボトルネックを確認し、必要に応じてローカル環境を強化するスモールスタートを今すぐ始めましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- 入門GPU(12〜16GB)は5〜15万円、本格スペック(32GB以上)は40〜50万円が目安
- AIエージェントを「使う」だけならGPUは不要。API経由が個人・中小企業の現実解
- 自社ホストが必要な大企業は社内GPUサーバー導入が2025年後半から主流に


