
OpenClawとローカルLLM構築ガイド|自律エージェント導入手順
 AIエージェントナビ編集部
AIエージェントナビ編集部
ローカルLLM(大規模言語モデル)環境での自律エージェント構築を検討しているものの、環境構築時のエラーやセキュリティ設定に不安を感じていませんか。本記事では、OpenClawを活用し、Ollamaと連携した自律稼働環境を最短で構築するための手順を解説します。
この記事に対する編集部の見解
- Macは16GB以上で追加投資なしに試せ、Windowsはグラボ12GB(8〜10万円)が実用的な入口
- WindowsビジネスノートはGPU非搭載が多く、まずタスクマネージャーでVRAMを確認する
- 月数百件程度の処理ならAPIの方が安く、ローカルとAPIは処理量で使い分けるのが正解
目次
OpenClawとローカルLLMの利点
ローカル環境でAIエージェントを動かすことは、単なる趣味の範囲を超え、ビジネス上の強力な武器となります。
ローカル運用のメリット
クラウドベースのAIサービスは便利ですが、機密情報の取り扱いやネットワークレイテンシ(遅延)が課題となります。ローカルでエージェントを稼働させる主なメリットは以下の通りです。
- データプライバシーの完結: 社内コードや個人情報が外部サーバーへ送信されません。
- 低レイテンシ: ネットワークを介さないため、高速な推論(回答生成)が可能です。
- コストの固定化: API利用料を気にすることなく、何度でも試行錯誤が可能です。
開発効率とコスト削減
ローカルLLM環境を構築することで、月額数万円かかっていたAPI費用をほぼゼロに抑えることができます。さらに、自社専用のファインチューニング(追加学習)済みモデルをエージェントに搭載することで、特定の業務領域において既存の汎用AIを凌駕する生産性を実現します。
関連記事:【2026年最新】OpenClawとは?AIエージェントの仕組みと、安全に業務導入する「NemoClaw」活用ガイド
【最短5分】OllamaでOpenClaw導入
複雑な設定を排除し、まずは環境を立ち上げることを最優先にします。
OS別インストール手順
以下のコマンドを、お使いの環境に合わせて実行してください。
- Windows (PowerShell):
npm install -g openclaw@latest - macOS / Linux (bash):
sudo npm install -g openclaw@latest
インストール後、ターミナルで openclaw --version と打ち込み、バージョンが表示されれば導入成功です。
自動接続と疎通確認
Ollamaがインストールされた状態で以下のコマンドを実行します。
ollama launch openclaw
このコマンドはOpenClawに必要な接続設定を自動的に生成し、ローカルサーバーとのリンクを確立します。起動後、ブラウザから指定のポート(デフォルトは3000)へアクセスし、OpenClawのダッシュボードが表示されるか確認してください。
関連記事:【2026年最新】OpenClaw導入設定マニュアル|初期構築からチャット連携・エラー解決まで完全網羅
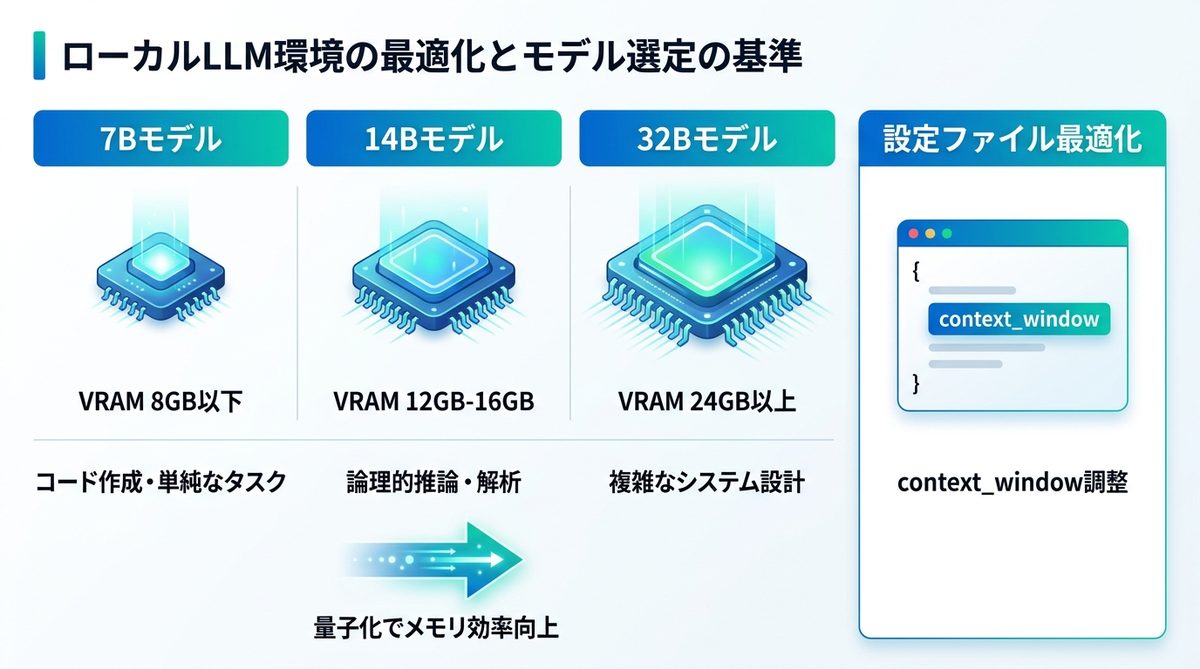
ローカルLLM環境の最適化とモデル選定
エージェントの賢さはモデルの性能に依存します。使用するPCのハードウェアスペックに応じて最適なモデルを選定しましょう。
VRAM別推奨モデル一覧
GPUのVRAM(ビデオメモリ)容量に応じた推奨モデルの目安です。
| VRAM容量 | 推奨モデルクラス | 用途 |
|---|---|---|
| 8GB以下 | 7B (70億パラメータ) | コード作成・単純なタスク |
| 12GB - 16GB | 14B (140億パラメータ) | 論理的推論・ドキュメント解析 |
| 24GB以上 | 32B (320億パラメータ) | 複雑なシステム設計・高度なタスク |
※いずれも量子化(モデルの軽量化処理)版を使用することで、メモリ効率を向上させることが可能です。
設定によるコンテキスト最適化
設定ファイル ~/.openclaw/openclaw.json を編集することで、モデルの挙動を詳細に指定できます。
{ "model": "llama3.2", "context_window": 8192, "temperature": 0.2 }
context_window(記憶容量)を大きくすると長いソースコードも一度に把握できますが、メモリ消費量が増加するため、お手持ちのVRAMに合わせて調整してください。
関連記事:【2026年版】ローカル生成AIの始め方|PCスペック判定表とおすすめソフト徹底解説
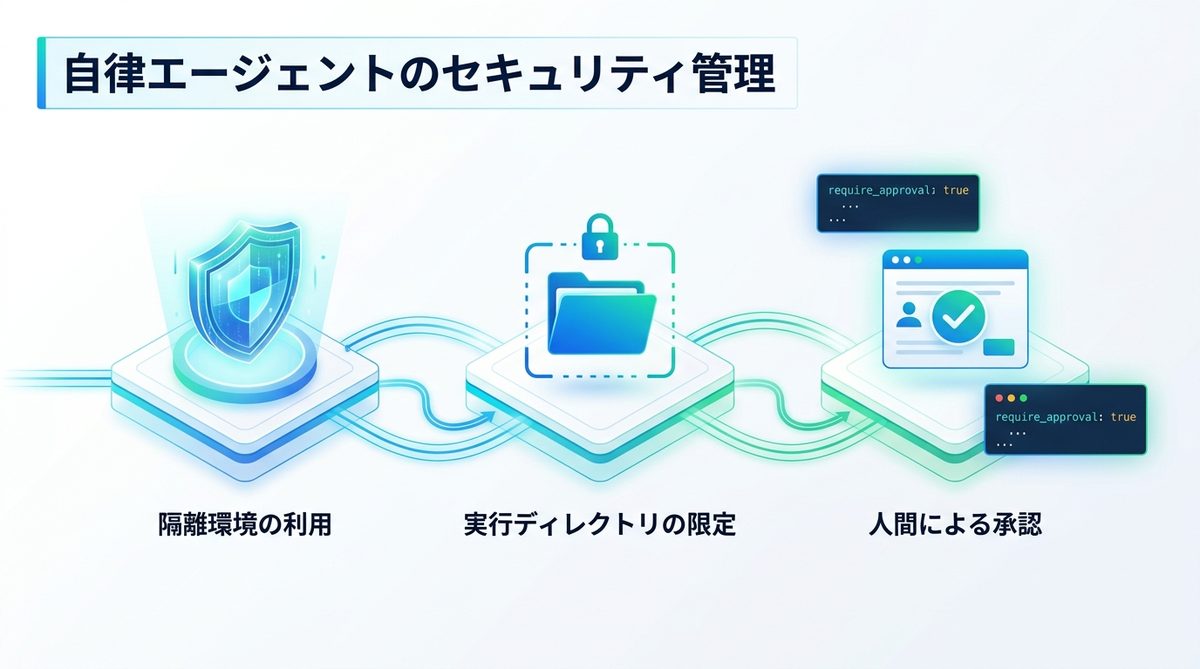
自律エージェントのセキュリティ管理
ローカルで動作させるとはいえ、エージェントにはPCを操作する権限があることを忘れてはいけません。
権限制限とゲートウェイ保護
OpenClawのエージェントには、ファイルの削除やコマンド実行の権限が与えられます。予期せぬ事故を防ぐため、以下の対策を徹底してください。
- 隔離環境(コンテナ)の利用: エージェントを実行する専用ユーザーを作成する。
- 実行ディレクトリの限定: 重要なシステムファイルにアクセスできないよう、作業用フォルダを限定する。
実行承認の設定方法
エージェントの判断のみで外部通信やファイル操作を行う設定はオフにし、重要な操作の前には必ず「人間による承認」を挟むフローを構築しましょう。設定ファイルの require_approval: true を有効にすることが、最も堅実な防衛策です。
関連記事:【2026年最新】OpenClaw初期設定ガイド|安全にスマホからAI秘書を操るビジネス構築術
OpenClaw導入のトラブルシューティング
導入時に直面しやすい課題と解決策をまとめました。
接続・依存エラーの解決策
「Connection Refused」が表示される場合は、Ollamaのサービスが起動しているか確認してください。また、node -v を実行し、Node.jsのバージョンが最新のLTS(長期サポート版)であることを確認してください。バージョンが古い場合、npm経由で最新版へアップデートすることをおすすめします。
WSL2のポート設定確認
WSL2(Windows Subsystem for Linux)環境では、Windowsホストとポートの転送設定が必要です。.wslconfig ファイルでポート開放が許可されているか確認し、ファイアウォール設定で該当ポートの通信を許可してください。
関連記事:【完全図解】OpenClaw(ロブスター)のインストール方法|初心者でも5分でAI秘書を起動する全手順
ローカルLLMのコストと投資効果
AI資産の蓄積とロックイン回避
特定のクラウド事業者に依存せず、ローカル環境を整備することで、モデルを自由に差し替え可能な「自社のAIインフラ」が完成します。
運用コスト削減シミュレーション
API従量課金モデルと比較すると、ローカル環境は初期のハードウェア投資こそ必要ですが、1年間の運用でAPIコストを100%削減できるケースも珍しくありません。特に、定常的にエージェントを活用する開発チームにとって、この投資は高いROI(費用対効果)をもたらします。
関連記事:【経営戦略】Gemma 4を比較して分かった、データ主権を守りコストを最適化する「ローカルLLM」導入術
まとめ
本記事では、OpenClawを用いたローカル環境の構築手順から、安全な運用方法までを解説しました。要点は以下の通りです。
- ローカル化の意義: プライバシー保護、低レイテンシ、コスト削減の3点が最大のメリット。
- 導入の速さ:
ollama launch openclawコマンドで最短5分で構築可能。 - 最適化: VRAM容量に応じた適切なモデル選定と、設定ファイルでのパラメータ調整が鍵。
- セキュリティ: エージェントへの権限付与には慎重になり、必ず承認プロセス(Human-in-the-loop)を導入する。
ローカル環境のAIエージェントは、あなたのPCを「自律的に働く優秀なパートナー」に変えるポテンシャルを秘めています。ぜひ今日から自身のマシンで構築を始めてみてください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- Macは16GB以上で追加投資なしに試せ、Windowsはグラボ12GB(8〜10万円)が実用的な入口
- WindowsビジネスノートはGPU非搭載が多く、まずタスクマネージャーでVRAMを確認する
- 月数百件程度の処理ならAPIの方が安く、ローカルとAPIは処理量で使い分けるのが正解


