
LFM2.5 日本語モデルの活用術|社内データ漏洩を防ぐエッジAI実装ガイド
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIを業務に導入したいが、機密性の高いデータをクラウドへ送信することに不安を感じていませんか。多くの企業が直面している「セキュリティと利便性のジレンマ」を解決する切り札が、Liquid AI社が2026年6月6日に公開した「LFM2.5」シリーズです。
本記事では、この軽量かつ高性能な日本語特化モデルを活用し、オンデバイス(端末内)で完結する安全なAIエージェント環境を構築する方法を解説します。
この記事に対する編集部の見解
- 日本語特化モデルは多いが、LFM2.5は『スマホ単体で動く軽さ』で他と差がつく
- GoogleのGemmaやQwenなど小型勢と日本語テストで同等以上、しかも省メモリで高速
- ELYZA等は賢いがPC前提になりがち、730MB・2秒応答という軽さが決定的な差
目次
Liquid AI「LFM2.5」とは?日本語特化の次世代AI
「LFM2.5」は、従来のクラウド依存型AIとは一線を画す、次世代の日本語特化型モデルです。なぜ今、これほどまでに注目されているのでしょうか。
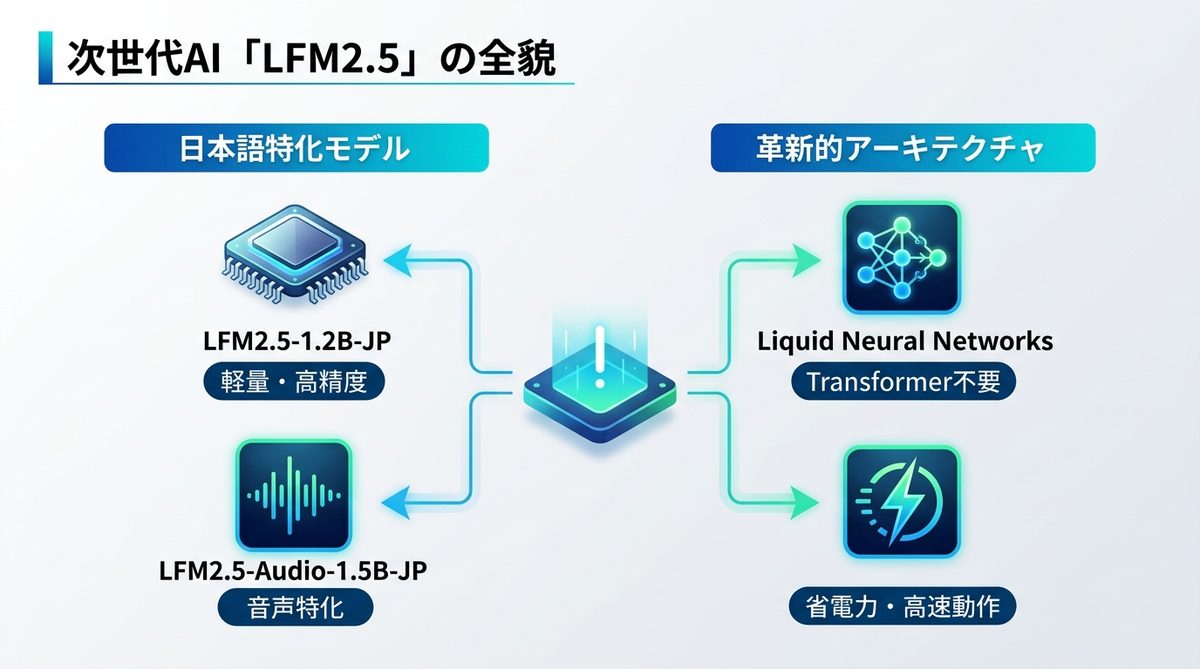
LFM2.5-1.2B-JPの概要
2026年6月6日にリリースされた「LFM2.5-1.2B-JP」は、12億パラメータという極めて軽量なサイズでありながら、日本語の指示追従能力に最適化されています。また、同時にリリースされた「LFM2.5-Audio-1.5B-JP」は、音声処理に特化したモデルとして、高い処理効率を実現しました。
Liquid Neural Networksの省メモリ性能
LFM2.5の最大の特徴は、従来のLLM(大規模言語モデル)の主流であったTransformer(言語処理のための深層学習アーキテクチャ)を必要としない「Liquid Neural Networks(液状ニューラルネットワーク)」を採用している点です。これは、生物の脳の神経回路を模した省エネ設計であり、PCやスマホのような限られたリソースでも驚くほど高速に動作します。
なぜ今、15億パラメータ以下の「LFM2.5 日本語」が選ばれるのか
企業がAI導入で最も懸念する「データ保護」と「コスト」の二大課題を、LFM2.5はどのように解決するのでしょうか。
情報漏洩リスクゼロのセキュリティ環境
LFM2.5は「オンデバイスAI」として動作するため、インターネットに接続せずとも単体で機能します。社内の機密文書や顧客データが外部サーバーへ送信されることがないため、情報漏洩のリスクを根本から遮断できます。「PCの中に優秀なアシスタントが住み着いた状態」を、極めてセキュアな環境で実現できるのです。
日本語特化による推論速度の向上
膨大なパラメータを持つ巨大なモデルは確かに賢いですが、推論に時間がかかり、高額なGPUサーバーが必要です。LFM2.5は日本語に絞って最適化されているため、少ない計算リソースで高速な応答が可能です。業務の待ち時間を劇的に減らし、リアルタイムに近い体験を提供します。

LFM2.5-Audioの実力とWhisper-large-v3比較
音声入力は、これからのAIエージェント活用の鍵となります。LFM2.5-Audioは、既存の定番モデルと比較しても圧倒的なパフォーマンスを発揮します。
音声処理における圧倒的な優位性
LFM2.5-Audio-1.5B-JPは、音声認識の正確性を測る指標であるCER(文字誤り率)において、Whisper-large-v3と比較して約半分という高い精度を達成しています。特に専門用語や日本語特有の言い回しにおける認識精度の高さは、議事録作成や音声対話業務において強力な武器となります。
エンドツーエンド処理の導入メリット
従来の音声AIは「認識→言語モデル→合成」と複数のステップを踏むため、遅延が発生しがちでした。LFM2.5は音声処理を統合した「エンドツーエンド処理(一気通貫で行う処理)」を採用しており、より自然で滑らかな音声対話を実現します。

【経営層必見】LFM2.5のコストとライセンス
導入において気になるのがコストと利用条件です。LFM2.5は、特に中小企業やスタートアップにとって魅力的な価格設計になっています。
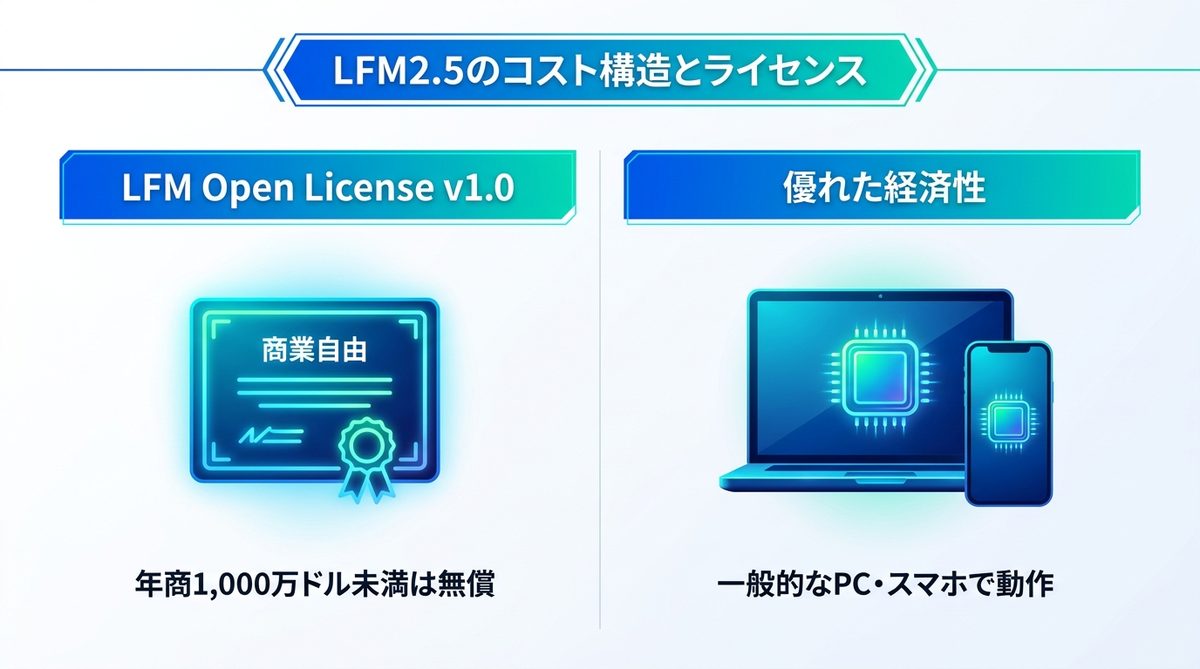
LFM Open License v1.0の適用範囲
Liquid AIが提供する「LFM Open License v1.0」では、年商1,000万ドル未満の企業であれば、この高精度なモデルを無償で商用利用できます。技術を独占するのではなく、広く社会に提供する姿勢が、AIの民主化を後押しします。
GPU不要の経済的な動作環境
LFM2.5は省メモリ設計であるため、高価なGPUサーバーを構築する必要がありません。一般的な業務用のPCや、最新のスマートフォン上で動作するため、ハードウェアへの追加投資を最小限に抑えることが可能です。
LFM2.5 日本語モデルで構築するセキュアなAI活用
最後に、実際にLFM2.5を活用してAIエージェントを構築する2つのステップをご紹介します。
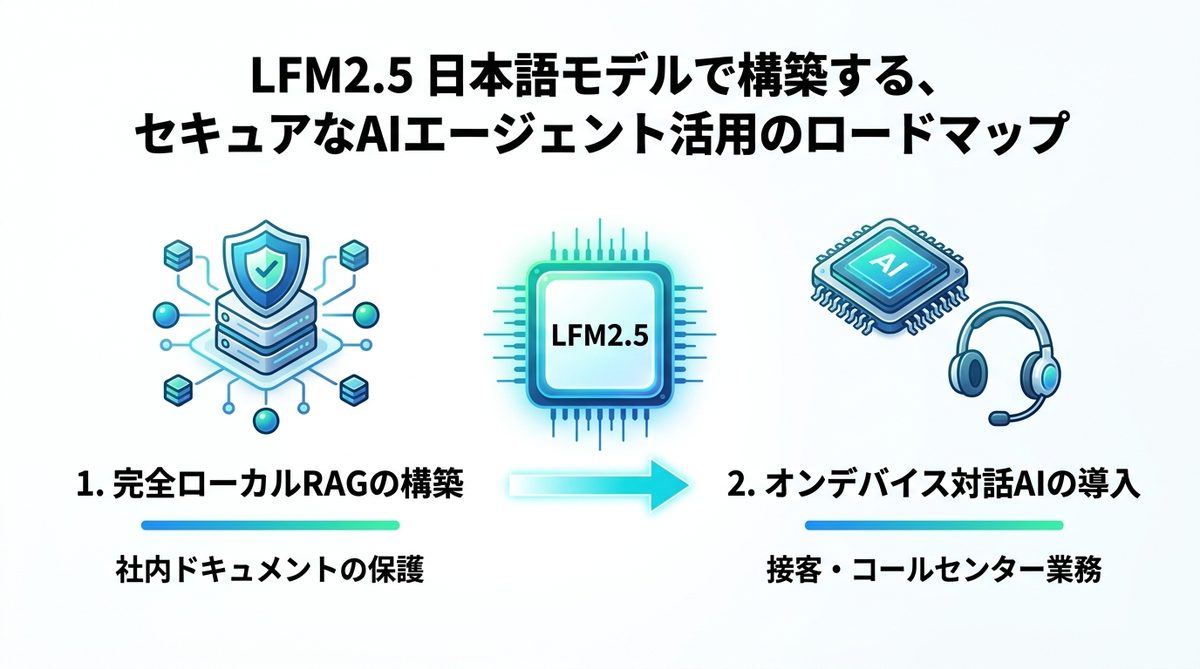
完全ローカルRAGの構築
社内の規定集やマニュアルを安全に活用するために、ローカル環境でRAG(検索拡張生成:外部知識をAIに参照させる手法)を構築します。機密情報を外部に一切出さずに、AIが社内資料に基づいた回答を行うシステムが完成します。
オンデバイス対話AIの導入
音声入力に強いLFM2.5-Audioを活用し、コールセンターの一次対応や接客支援に導入します。オフライン環境でも動作するため、ネットワークが不安定な場所や、絶対的なセキュリティが求められる環境下での利用に最適です。
まとめ
LFM2.5シリーズは、セキュリティ、コスト、性能のバランスを極めた、日本企業のDXに最適なAIです。要点を以下にまとめます。
- 安全性の確保: 完全オンデバイス動作で情報漏洩リスクをゼロにできる。
- 高効率な処理: 1.5B以下の軽量モデルで、一般的なPCでも高速動作が可能。
- 圧倒的な日本語性能: 音声認識精度が向上し、日本語特化の指示追従能力も備える。
- 導入コストの抑制: 年商1,000万ドル未満なら無償で商用利用可能。
ぜひ、御社の業務にLFM2.5を導入し、セキュアで高速なAIエージェント環境を構築してみてください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
・GoogleのGemma、AlibabaのQwen、MetaのLlamaの小型版が代表格
・日本語の知識や指示理解のテストでLFM2.5は同等〜やや上
しかもLFM2.5は独自構造でメモリ消費が少なく、動作が速いのが強みです。
編集長
Nav
・LFM2.5は約730MBと軽く、スマホ単体で約2秒で返答
・簡単な日本語なら、はるかに大きいAI並みの賢さも見せる
「賢さ」より「この軽さでスマホ完結」が決定的な差です。
編集長
Nav
編集長
Nav
編集部のまとめ
- 日本語特化モデルは多いが、LFM2.5は『スマホ単体で動く軽さ』で他と差がつく
- GoogleのGemmaやQwenなど小型勢と日本語テストで同等以上、しかも省メモリで高速
- ELYZA等は賢いがPC前提になりがち、730MB・2秒応答という軽さが決定的な差

