
【徹底解説】Nemotron 3 Superとは?コストを抑えてAIエージェントの精度を最大化する新手法
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの運用コスト高騰に頭を悩ませていませんか?2026年3月にNVIDIAが発表した「Nemotron 3 Super」は、120B(1200億)規模の知能を、わずか12B相当のコストで運用可能にするゲームチェンジャーです。本記事では、既存のAIワークフローを維持しつつ、コストと精度のジレンマを解消するための活用法を解説します。
目次
Nemotron 3 Superとは?AIエージェント運用の常識を変える「高効率MoE」の正体
これまでのAIモデルは、単純な問い合わせから複雑な推論まで、すべてのタスクに対して巨大な演算リソースを消費していました。しかし、Nemotron 3 Superの登場によって、その常識は過去のものとなります。
なぜ「120Bの知能」を「12Bのコスト」で扱えるのか
Nemotron 3 Superの最大の革新は、MoE(Mixture of Experts:専門家混合モデル)の進化にあります。これを「省エネ経営」に例えると非常に分かりやすくなります。
- 従来のモデル: 何か質問があるたびに、社内の「全社員(120B分)」が会議に参加して回答を考えていた状態です。
- Nemotron 3 Super: 質問内容に応じて、必要な専門知識を持つ「精鋭数名(12B分)」だけが会議に参加し、残りの社員は待機する仕組みです。
この仕組みにより、AIの知的能力は広大なまま、実際に動かす脳の領域を絞り込むことで、劇的なコストダウンと高速化を実現しているのです。
NVIDIAが推論効率にこだわる戦略的背景
AIエージェントがPCの中に住み着き、24時間稼働し続ける未来において、推論コストはそのまま経営の固定費となります。NVIDIAはハードウェアメーカーとしての知見を活かし、「モデルを大きくする」こと以上に「いかに効率よく稼働させるか」に軸足を移しました。この最適化は、AIを「試験的なおもちゃ」から「利益を生む労働力」へと昇華させるための重要な一歩と言えます。
関連記事:【中規模ビジネス向け】Claude Codeの料金体系と主要API比較ガイド
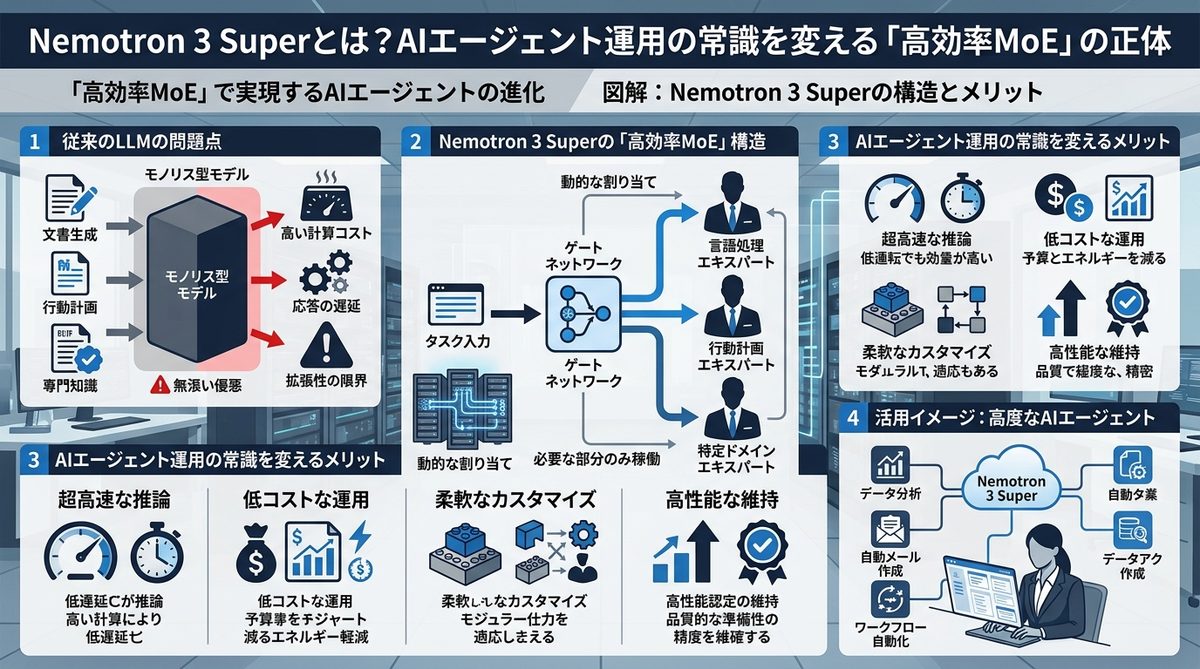
ビジネス現場で実感できる!Nemotron 3 Superの強み3選
具体的なビジネスメリットとして、特に注目すべきポイントは以下の3点です。
思考プロセス(Reasoningモード)によるタスク完遂率の向上
AIエージェントが複雑なタスクをこなす際、一度の回答で失敗してしまうケースが多々あります。Nemotron 3 Superは「思考プロセス(Reasoningモード)」を備えており、途中で行き詰まった場合に自ら軌道修正を行うことが可能です。人間が細かく指示を出さなくても、エージェントが勝手に「考えながら動く」ため、タスクの完了率が飛躍的に向上します。
100万トークンがもたらす「長期間の文脈把握」の価値
100万トークン(約75万語相当)という圧倒的なコンテキスト(記憶容量)により、エージェントは長期記憶を持つことが可能になりました。例えば、以下のような作業を丸ごと任せられます。
- 過去数ヶ月分の全議事録を読み込ませた状態でのプロジェクト進捗管理
- 大量の社内規定・契約書データに基づくコンプライアンスチェック
- 数万行に及ぶコードベース全体を俯瞰したバグ修正
文脈を忘れないため、何度も同じ指示を繰り返す必要はありません。
既存環境からの「エンジニア不要」な差し替えやすさ
Nemotron 3 Superは、NVIDIA Build APIを通じて提供されます。現在Claudeや他のモデルで構築しているAIエージェントのAPIエンドポイントを書き換えるだけで、即座にエンジンを換装可能です。大規模な再構築なしに、明日からコスト構造だけを改善できる柔軟性が、現場担当者にとって最大の魅力です。
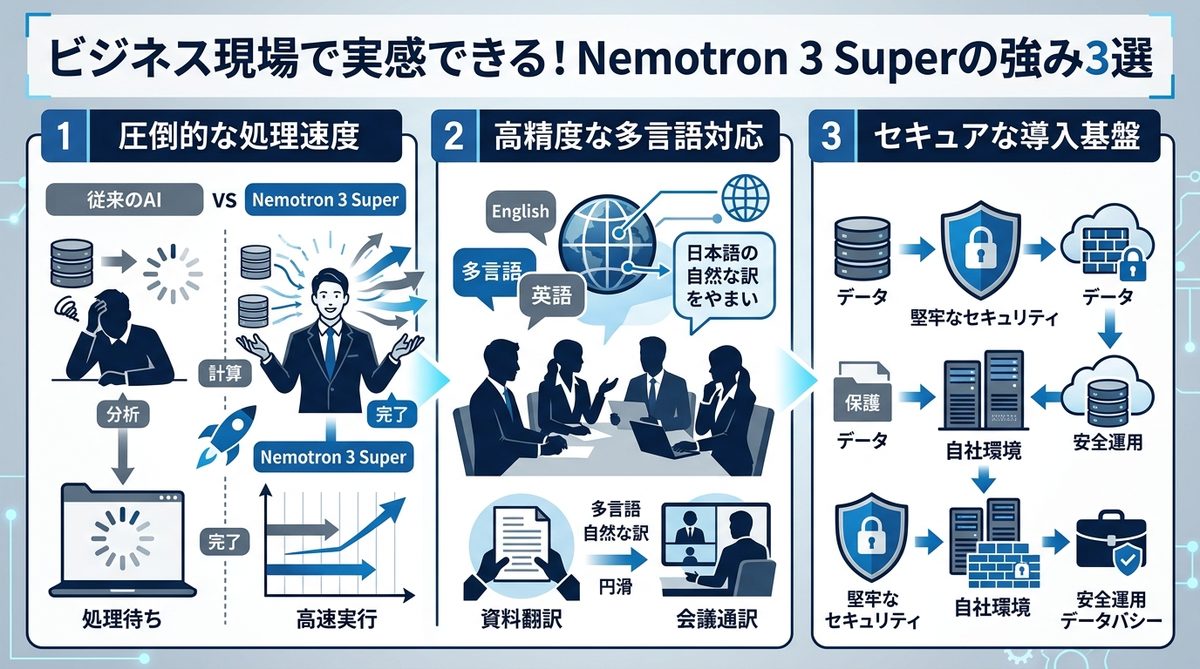
【比較検証】既存のAI環境とNemotron 3 Super、どちらを選ぶべきか?
既存のAIエージェントとの住み分けを整理します。すべてのタスクを単一のモデルで処理するのではなく、適材適所で使い分けるのが賢い戦略です。
Claude Codeや汎用モデルとの使い分け戦略
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| 極めて抽象的な戦略立案・創作 | Claude等 | 創造的推論において高い安定性を発揮 |
| 定型的な定時タスク・データ分析 | Nemotron 3 Super | 圧倒的なコスパで高精度な処理が可能 |
| ログ監視・エラー修正・社内検索 | Nemotron 3 Super | 100万トークンによる文脈保持が不可欠 |
推論コスト削減による投資対効果(ROI)のシミュレーション
仮に毎日1,000回のAPIリクエストを行うエージェントを運用している場合、120Bのモデルを使い続けるとコストは膨大ですが、Nemotron 3 Superへ移行することで、推論効率の差により実質的な推論コストを約60〜80%削減できる可能性があります。浮いた予算を、より高度なR&D(研究開発)に充てるのが成功企業の定石です。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
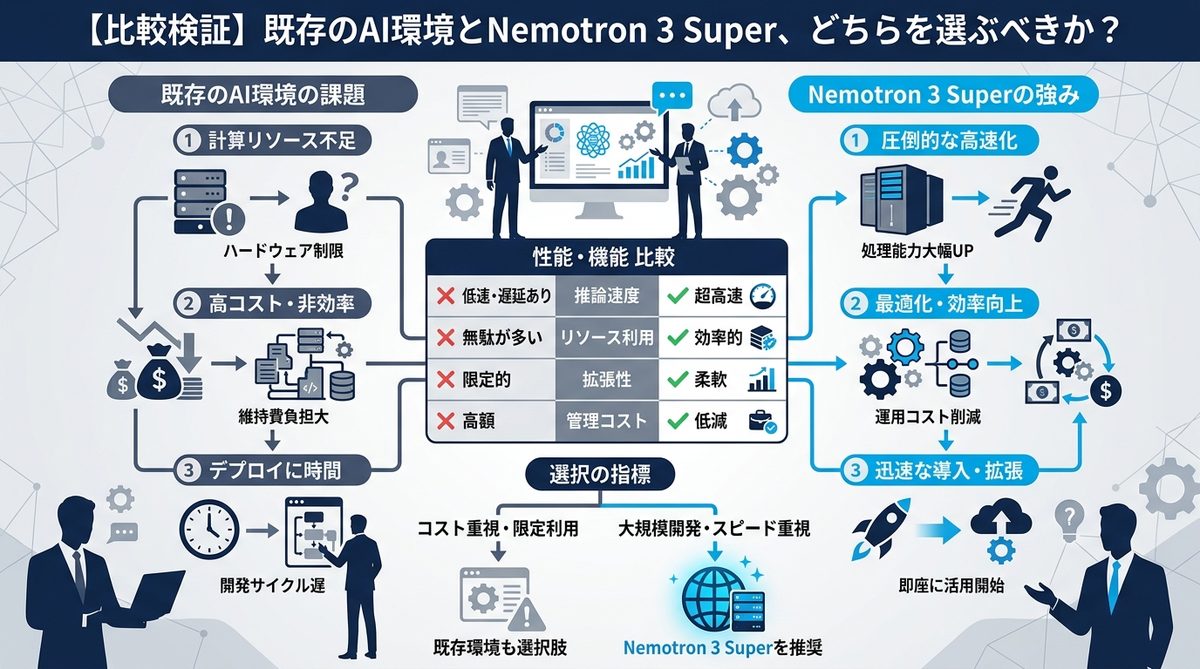
今すぐ始める!AIエージェントの「エンジン換装」ステップ
導入は非常にシンプルです。まずは以下のプロセスで検証を開始してください。
NVIDIA Build APIを活用したスモールスタートの方法
まずは全業務を切り替えるのではなく、特定のエージェント(例:社内FAQ検索ボット)のみを対象にAPIを接続します。
1. NVIDIA Build APIへアクセスし、APIキーを発行する
2. 既存ツール(CursorやAIワークフローツール)のモデル設定をNemotron 3 Superに変更する
3. 1週間の精度比較を行う
検証すべき「精度維持」と「パフォーマンス」の指標
導入初期は、以下のKPI(重要業績評価指標)をモニタリングしてください。
* コスト削減率: 従来モデルと比較したトークン単価の差額
* タスク完遂率: エージェントが途中でエラーを吐かず、目的の成果物を出力した割合
* 応答速度: 思考プロセスを含めた回答完了までのレイテンシ(遅延時間)
まとめ
Nemotron 3 Superは、単なるスペックアップのモデルではなく、AIエージェントを「実用的なビジネスの戦力」として自律稼働させるための最適解です。要点を以下にまとめます。
- 120Bの知能×12Bのコスト: 高効率MoEで経済性と知性を両立。
- 100万トークン: 長期的な文脈保持により、複雑なプロジェクト管理も可能。
- 容易な移行性: NVIDIA Build APIにより、既存のエージェントを即座にエンジン換装可能。
まずはNVIDIA Buildを通じて、既存のワークフローの一部を本モデルへ置き換え、そのコストパフォーマンスをぜひ体感してみてください。今すぐスモールスタートで検証を始めましょう。



