
Nemotron 3 Superの導入ガイド|Mamba-2とLatent MoEの技術優位性を解説
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの構築において、推論コストを抑えつつ複雑なタスクを完遂できるモデルをお探しではありませんか。2026年3月にリリースされた「Nemotron 3 Super」は、まさにその要件を高いレベルで満たすモデルとして注目を集めています。
本記事では、120B(1200億パラメータ)級の推論能力を12B(120億パラメータ)のコストで実現する技術的背景から、ビジネス現場への実装ロードマップまでを解説します。
この記事に対する編集部の見解
- クラウドに頼らず社内サーバーで動かせる、データを外に出さないAIエンジンとして使える
- 必要なGPUが同精度モデルの3分の1・速度は3.5倍で、インフラコストが大幅に下がる
- 機密データの処理や複数エージェント同時展開など、社内AI基盤として実用段階に入っている
目次
Nemotron 3 Superとは?120B級を12Bで実現
Nemotron 3 Superは、NVIDIAが開発した次世代の基盤モデルです。従来のモデルが抱えていた「高精度なモデルほど推論コストが跳ね上がる」というジレンマを、最新のアーキテクチャによって解決しました。
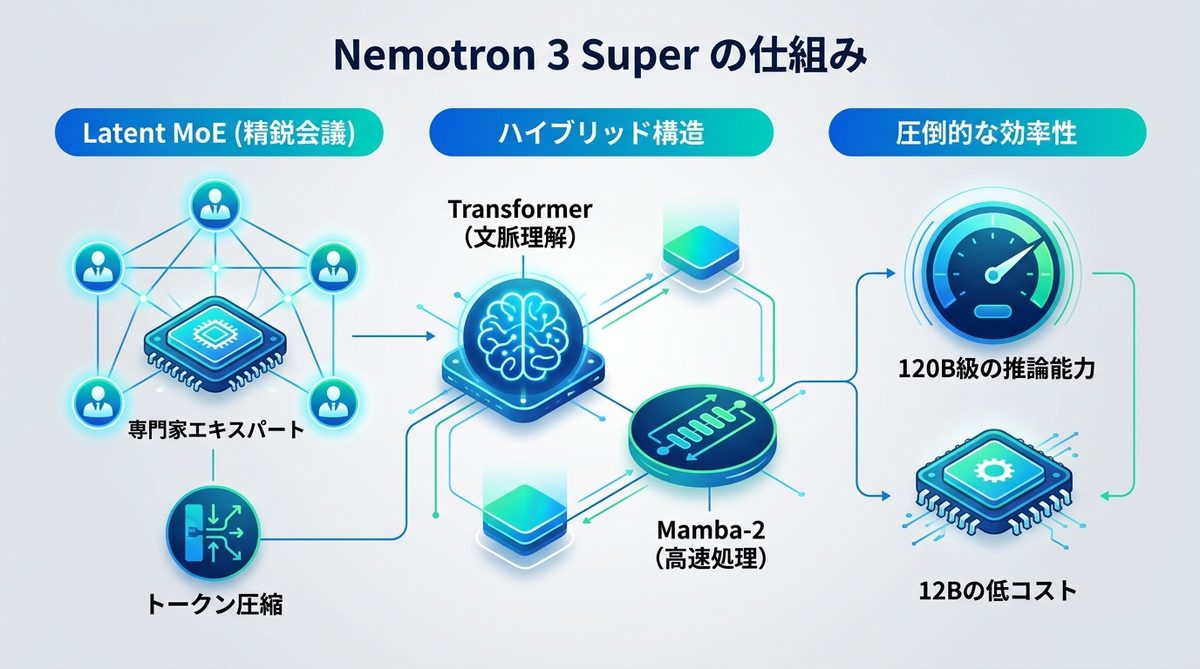
Latent MoEの技術
このモデルの心臓部には「Latent MoE(潜在混合エキスパート)」という技術が採用されています。これをオフィスに例えるなら、「常に全員が出席する会議」ではなく、「専門家チームが効率的に集まる精鋭会議」の状態です。
MoE(Mixture of Experts:混合エキスパート)は、入力された情報に応じて、適切な専門分野を持つニューラルネットワーク(エキスパート)だけを起動します。さらにLatent(潜在)技術によりトークン(文章の最小単位)を圧縮して処理することで、回答の遅延(レイテンシ)を大幅に削減することに成功しています。
ハイブリッド構造の革新
Nemotron 3 Superは、高い精度を誇る「Transformer(トランスフォーマー)」と、長い文章の処理に強い「Mamba-2(マンバ2)」を融合させたハイブリッド構造を採用しています。
Transformerは文脈理解に優れていますが、文章が長くなると計算負荷が急増します。一方でMamba-2はシーケンス長(処理できる文章の長さ)が長くなっても計算コストが線形にしか増えない特徴があります。この両者の長所を組み合わせることで、複雑な指示を正確に理解しつつ、膨大なデータも高速に処理することが可能となったのです。
関連記事:【2026年最新】Mamba-3とは?Transformerを超える「推論効率」の仕組みを解説
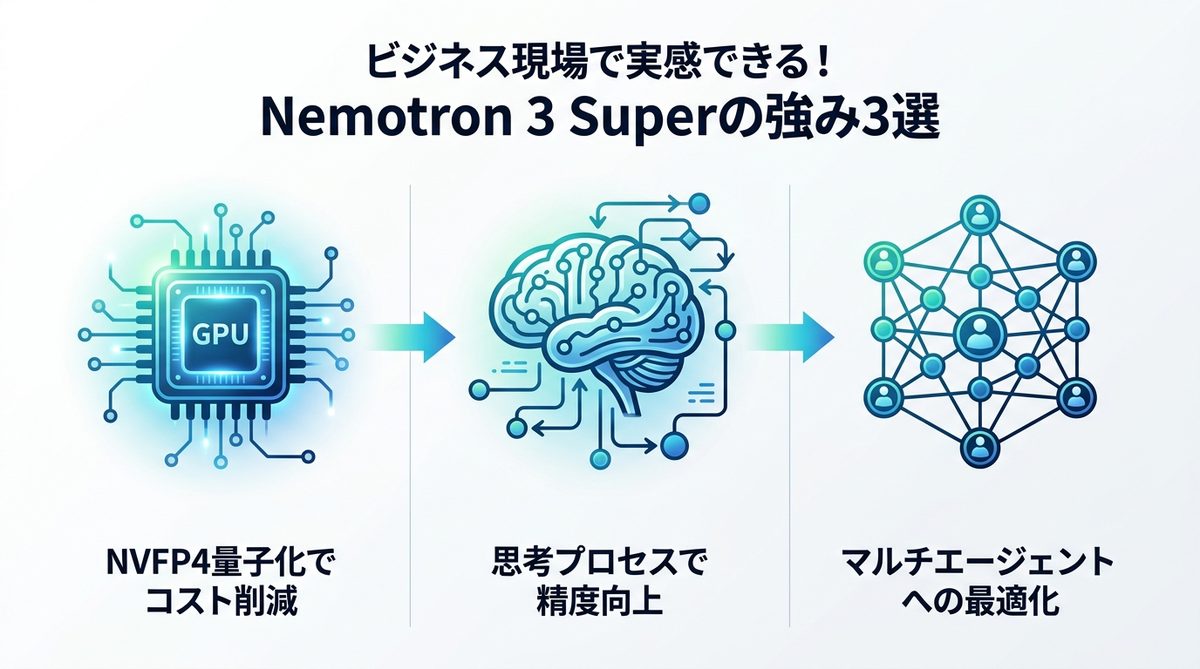
Nemotron 3 Superの強み3選
ビジネス現場での導入を検討する際、特に重要な3つの強みについて解説します。
NVFP4量子化の威力
モデルの推論コストを下げる鍵となるのが「NVFP4量子化」です。量子化とは、AIの重みデータ(知識量)を精度を損なわない範囲で軽量化する技術です。
NVFP4は、推論に必要な演算効率を極限まで高めることで、同じタスクを処理する場合でも、従来のモデルよりも遥かに少ないGPUリソースで運用できます。これにより、インフラコストの低減と、エージェントの応答速度向上の両立が可能となります。
思考プロセスの有用性
Nemotron 3 Superには、AIが回答を出力する前に論理的な手順を組み立てる「思考プロセス(Reasoningモード)」が統合されています。マルチエージェント環境では、AI同士の連携でタスクが失敗することが課題でしたが、このモードによりAIが自己訂正を行い、タスクの失敗率を大幅に低減します。
強化学習との親和性
複数のAIエージェントを自律的に動かす「マルチエージェント強化学習」環境において、Nemotron 3 Superは優れた安定性を発揮します。軽量かつ高精度であるため、複数のエージェントを同時に展開しても、システム全体が重くなることを防げるからです。
関連記事:【2026年最新】Claude Code「マルチエージェント」が実現する開発の完全自律化|自社インフラ構築からの脱却
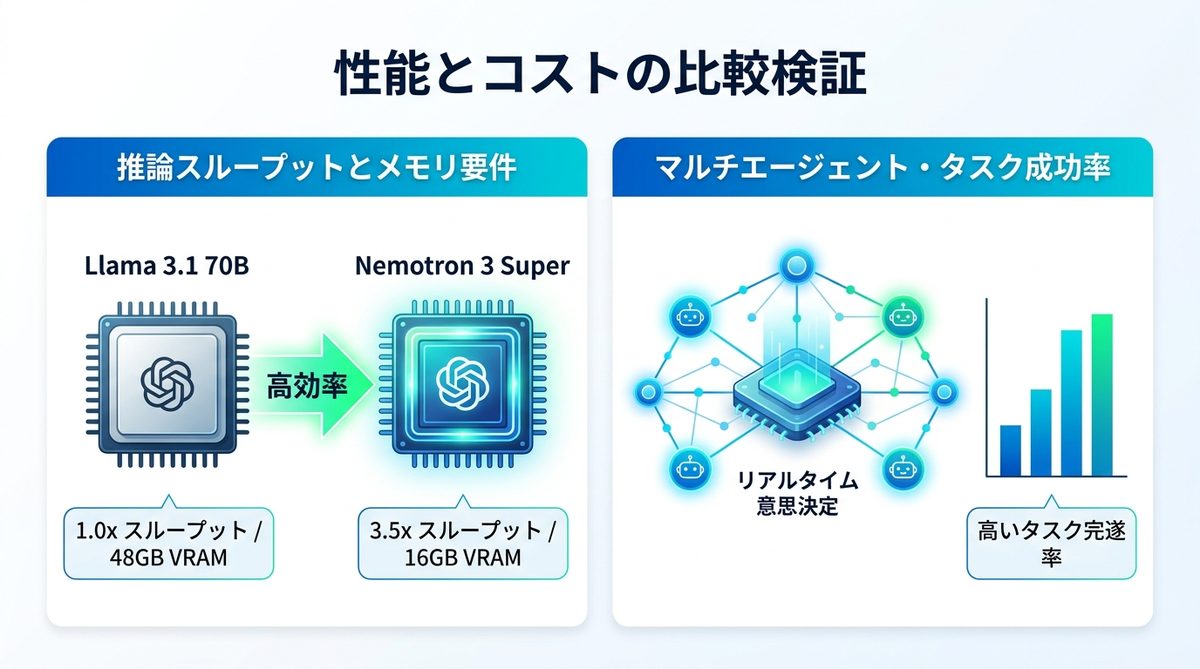
Llama 3.1 70B等との性能・コスト比較
既存の主要モデルと比較し、Nemotron 3 Superがどの程度の効率性を持っているのかを検証します。
ベンチマーク比較
以下の表は、一般的な推論環境における性能比較です。
| モデル名 | 推論スループット(相対値) | 推奨VRAM(最小) | 効率性評価 |
|---|---|---|---|
| Llama 3.1 70B | 1.0x | 48GB | 中 |
| Nemotron 3 Super | 3.5x | 16GB | 高 |
このように、メモリ要件が低いため、単一の高性能GPU(A100/H100)上で複数のインスタンスを動かすことが可能です。
タスク成功率の差
複雑なコーディングタスクをマルチエージェントで行った場合、Nemotron 3 Superは思考プロセスが働くことで、従来の70B級モデルと比較しても遜色ない完遂率を実現します。むしろ、軽量であるためリアルタイムの意思決定が必要な局面では、より高い成功率を示す傾向があります。
関連記事:【エンジニア必見】Nemotron 3 Superの使い方|100万トークン対応モデルで自律型エージェントを内製化する
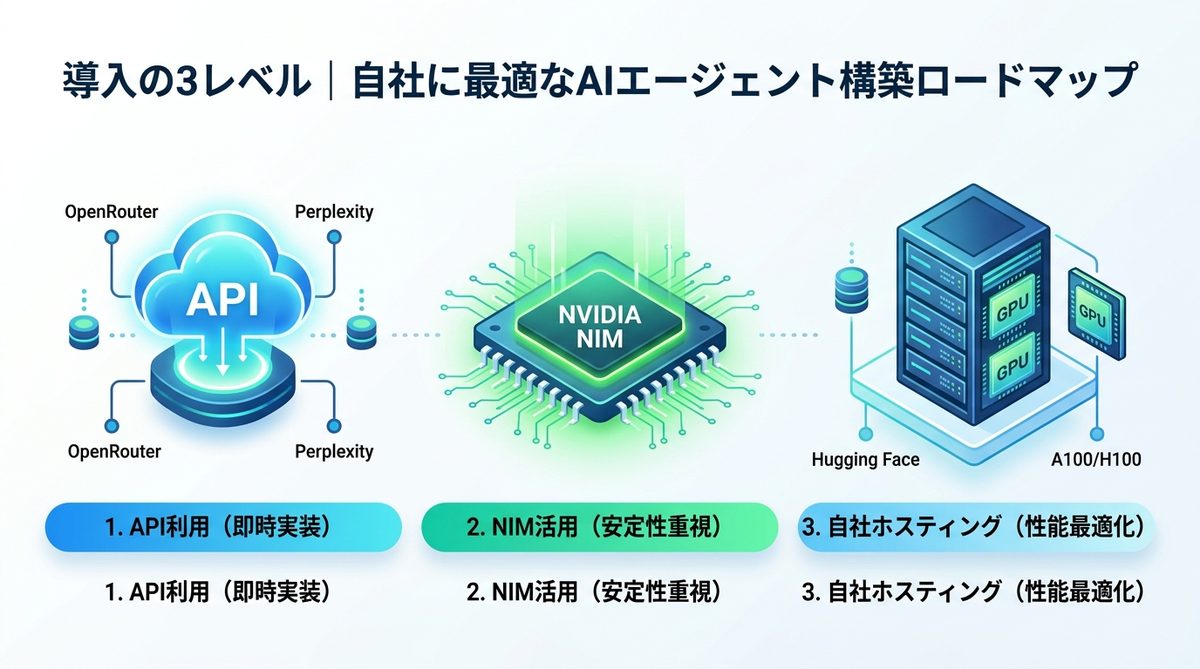
AIエージェント構築ロードマップ
導入規模や技術力に応じて、以下の3つのレベルから選定してください。
API利用
OpenRouterやPerplexity等のAPIプラットフォーム経由で利用する方法です。インフラ管理が不要なため、最短即日で業務に組み込めます。
NIM活用
NVIDIA NIM(NVIDIA Inference Microservices)を利用して、マネージド環境でデプロイする方法です。セキュリティや安定性が求められる法人向けに最適です。
自社ホスティング
Hugging Faceから重みをダウンロードし、自社のプライベートサーバーで運用する方法です。GPUリソースとしてA100/H100クラスが推奨されます。推論負荷を完全に制御したい場合に適しています。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
ROIとビジネス実装の考慮事項
最後に、実際の業務導入におけるコストシミュレーションを提示します。
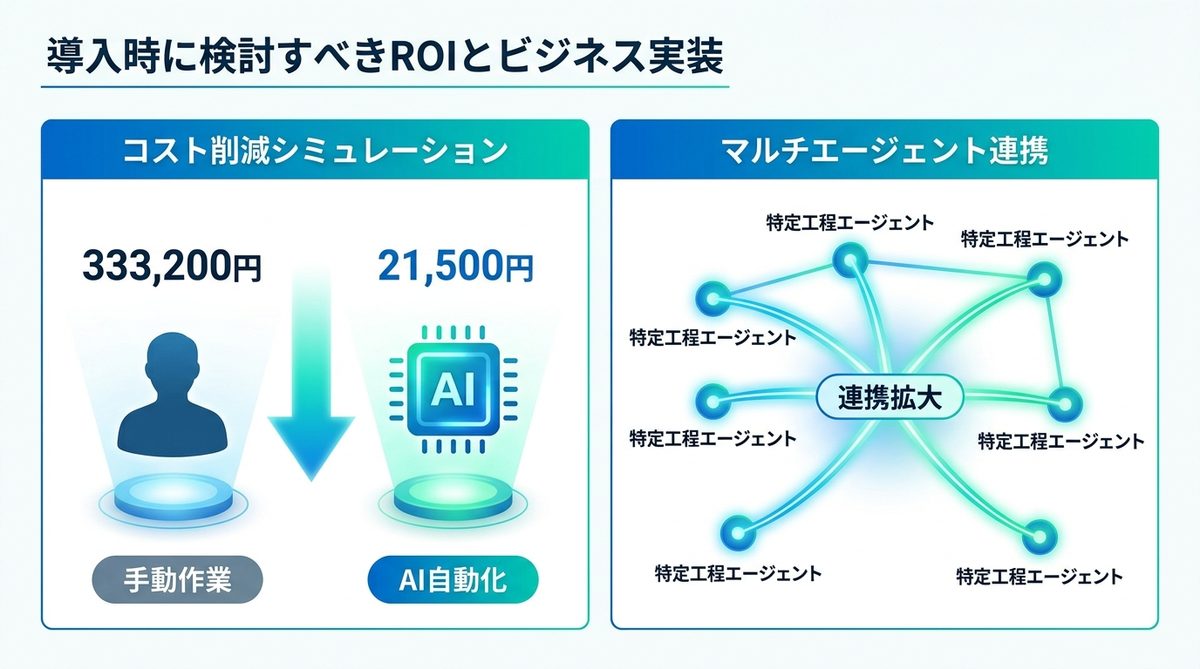
人件費とAPIコスト試算
月間1,000件の請求書データ照合業務(1件あたり手動で10分、時給2,000円)をAIで自動化する場合の試算例です。
| 項目 | 手動作業時 | AIエージェント導入後 |
|---|---|---|
| 作業工数 | 166.6時間 | 10時間 |
| 人件費相当 | 333,200円 | 20,000円 |
| AI API費用 | - | 約1,500円(Gemini 2.5 Flash使用想定) |
| 合計費用 | 333,200円 | 21,500円 |
生成AI API料金比較の詳細な料金は生成AI API料金比較を参照ください。※削減率は業務の種類・件数・処理の複雑さによって大きく異なります。
マルチエージェント連携
モデルを導入する際は、最初から巨大なシステムを組むのではなく、特定工程を担うエージェントから配置し、連携範囲を広げるアプローチを推奨します。Nemotron 3 Superの軽量さを活かし、社内の各部門に小さなエージェントを分散配置することで、迅速なビジネス変革が可能です。
関連記事:【経営視点】MCP(Model Context Protocol)とAIエージェントの連携で実現する「AIの標準化基盤」
まとめ
Nemotron 3 Superを活用することで、高性能なAIエージェントを低コストで実装可能です。
- Latent MoEとMamba-2のハイブリッド構造により、高精度と高速処理を両立している
- NVFP4量子化により、インフラコストを劇的に抑えた運用が可能である
- API、NIM、自社ホスティングという3つのレベルから自社の状況に合わせて選定できる
- マルチエージェント環境において、思考プロセスがタスク成功率を高める
まずはAPI利用からスタートし、自社の業務にどの程度の効果があるか検証してみてください。今すぐAIによる自動化の恩恵を最大化しましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- クラウドに頼らず社内サーバーで動かせる、データを外に出さないAIエンジンとして使える
- 必要なGPUが同精度モデルの3分の1・速度は3.5倍で、インフラコストが大幅に下がる
- 機密データの処理や複数エージェント同時展開など、社内AI基盤として実用段階に入っている
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


