
【導入戦略】Qwen3.5-Omniとは?AIエージェントの処理遅延を解決する「ネイティブ」の衝撃
 AIエージェントナビ編集部
AIエージェントナビ編集部
動画解析や音声対話において、AIの回答待ち時間にイライラしたり、微妙なニュアンスが伝わらずにやり直しになったりした経験はありませんか?既存のAI環境では、各プロセスを個別に処理する「継ぎ接ぎ」の連携が原因で、多くのロスが発生しています。
2026年3月にリリースされた「Qwen3.5-Omni」は、その現状を根底から覆す「ネイティブ・オムニモーダル」技術を搭載しています。本記事では、Qwen3.5-Omniの技術的優位性と、既存業務エージェントへの導入戦略を解説します。
目次
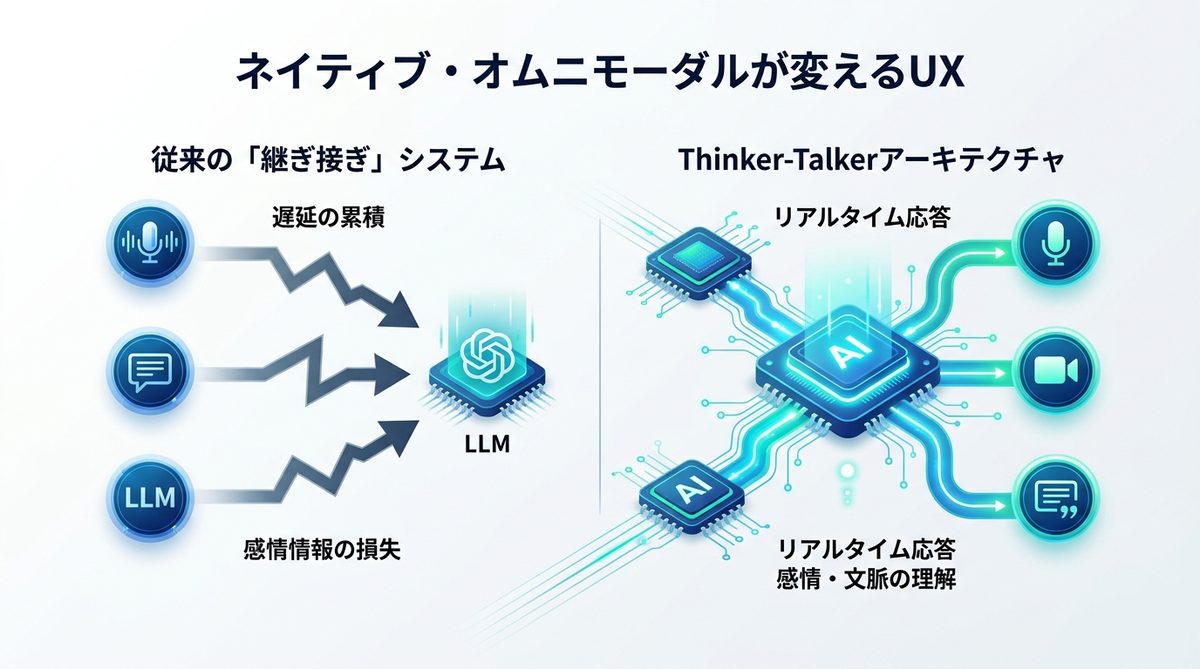
なぜ「継ぎ接ぎ」は限界なのか?ネイティブ・オムニモーダルが変えるUX
AIに音声や動画を扱わせる際、従来は「音声→テキスト」「映像→静止画分割」といった変換作業が不可欠でした。これがビジネス現場における最大のボトルネックなのです。
変換プロセスが引き起こす「思考の断絶」とは
従来のシステムは、いわば「翻訳機をいくつも経由する伝言ゲーム」のような状態でした。音声入力からテキスト変換し、それをLLM(大規模言語モデル)に投げて回答を得る。このプロセスには以下の欠点があります。
- 遅延の累積: 各変換工程でコンマ数秒のタイムラグが積み重なり、人間との会話において致命的な「間」が生じる。
- 感情情報の損失: テキスト化される過程で、声のトーン、話者の表情、背景の騒音といった文脈情報が削ぎ落とされる。
「人間らしい対話」を支えるThinker-Talkerアーキテクチャ
Qwen3.5-Omniが採用した「ネイティブ・オムニモーダル」は、テキスト、音声、動画を単一のパイプラインで直接処理します。これを「Thinker-Talker(思考しつつ即座に話す)」アーキテクチャと呼びます。
PCの中に「高性能な脳と目と耳を直結させたアシスタント」が住み着いている状態を想像してください。このモデルは、相手が言葉を発している途中で「相槌」を打ち、映像からその人の困惑した表情を読み取って、回答のトーンを瞬時に調整できます。変換プロセスを排除したことで、人間同士の対話に近い、極めてシームレスな体験が可能になりました。
関連記事:【完全ガイド】Qwen 3.5の選び方・動かし方|高性能AIをローカル環境で最大限活用する方法
Qwen3.5-Omniの3つの形態を使いこなす!業務エージェントの最適構成
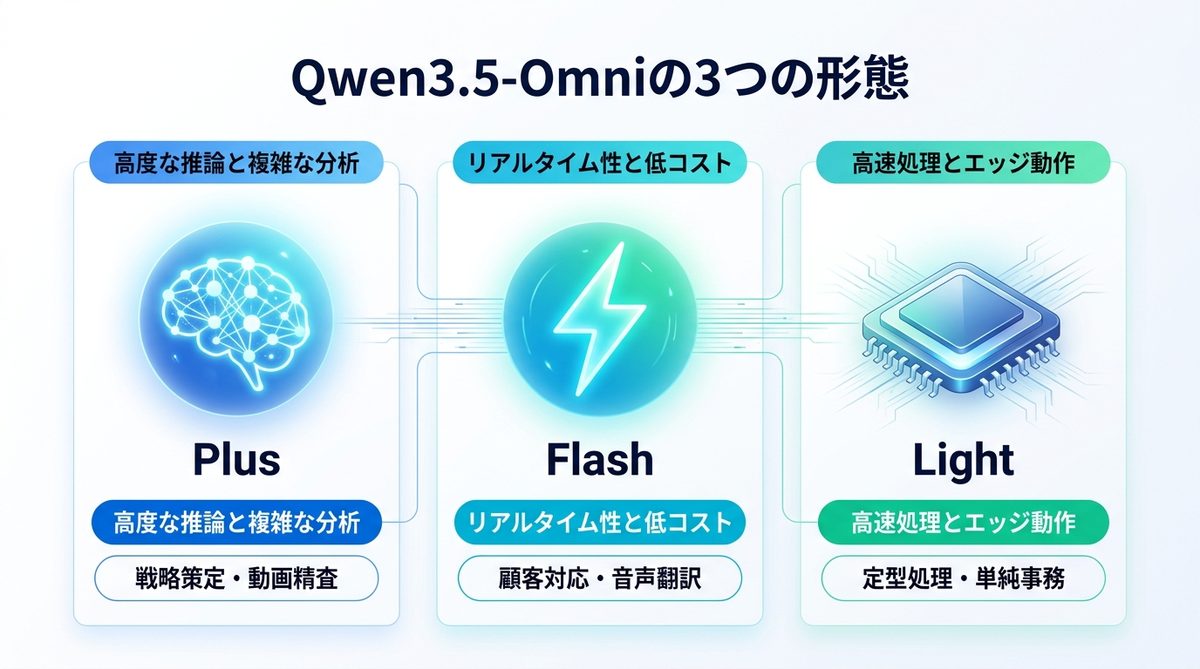
Qwen3.5-Omniは、目的や環境に合わせて使い分けられる3つのモデル形態を展開しています。業務エージェントのチームを編成する際は、この特性を活かした最適配置が成功の鍵です。
| モデル形態 | 得意分野 | 推奨されるビジネス活用例 |
|---|---|---|
| Plus | 高度な推論と複雑な分析 | 戦略策定、長尺動画の議事録精査 |
| Flash | リアルタイム性と低コスト | 顧客対応チャット、ライブ音声翻訳 |
| Light | 高速処理とエッジ動作 | デバイス内での定型処理、単純事務 |
高度分析を担う「Plus」:戦略的判断のための深掘り能力
「Plus」は、フラッグシップモデルとして最高精度の推論能力を誇ります。経営判断に関わる複雑なビジネス課題の整理や、数時間に及ぶ会議動画の解析など、「正確性」と「深い洞察」が求められる業務を任せるのに最適です。
リアルタイム対応の「Flash」:接客・サポートを劇的に速くする選択肢
「Flash」は、低遅延を極めたモデルです。顧客からの問い合わせに対して、待たせることなく即答する音声エージェントの心臓部として適しています。コストパフォーマンスも非常に高く、大量のトラフィックをさばく現場でのメイン活用に向いています。
エッジでの機動力「Light」:特定業務の高速化とコスト最適化
「Light」は、軽量で高速なレスポンスが特徴です。複雑な推論は不要だが、一定のルールに基づいたデータ処理を瞬時に行いたい場合や、セキュリティの観点からローカル環境に近い場所で動作させたい特定の業務に最適です。
関連記事:【2026年最新・総まとめ】AIエージェントとは?仕組み・種類・主要ツール・活用事例を徹底解説
既存のAI環境にQwen3.5-Omniを組み込むメリット
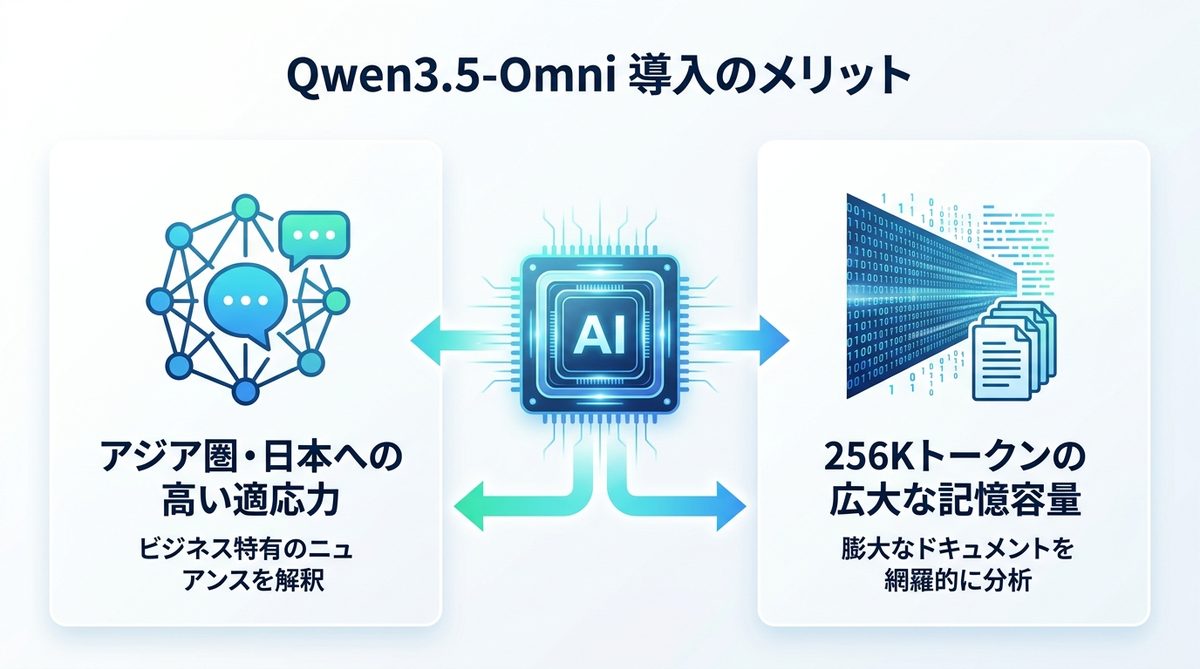
Qwen3.5-Omniは、グローバルなモデルの中でも特に日本を含むアジア圏のビジネス環境に適した強みを持っています。
アジア圏の言語特性に強い「高い適応力」
多くのAIモデルが英語圏の慣習をベースに設計されているのに対し、本モデルはアジア圏の言語特性や、日本のビジネスシーン特有の「行間を読む」文化に対する理解が非常に高精度です。曖昧な指示や敬語のニュアンスも正確に解釈し、業務の修正コストを大幅に削減します。
256Kトークンで実現する「長尺データの網羅的分析」
256Kトークン(記憶容量の目安)という広大なコンテキストウィンドウにより、長時間にわたるオンライン会議の録画や、膨大な社内ドキュメントを一度に丸ごと読み込ませることが可能です。「必要な情報の断片」を探すのではなく、全体像を把握した上での精緻な意思決定を支援します。
関連記事:【2026年最新】SaaSは死なない、進化する。AIエージェント時代に勝つための「次世代SaaS戦略」
AIエージェント運用の刷新:簡素化がもたらすマネジメントの価値
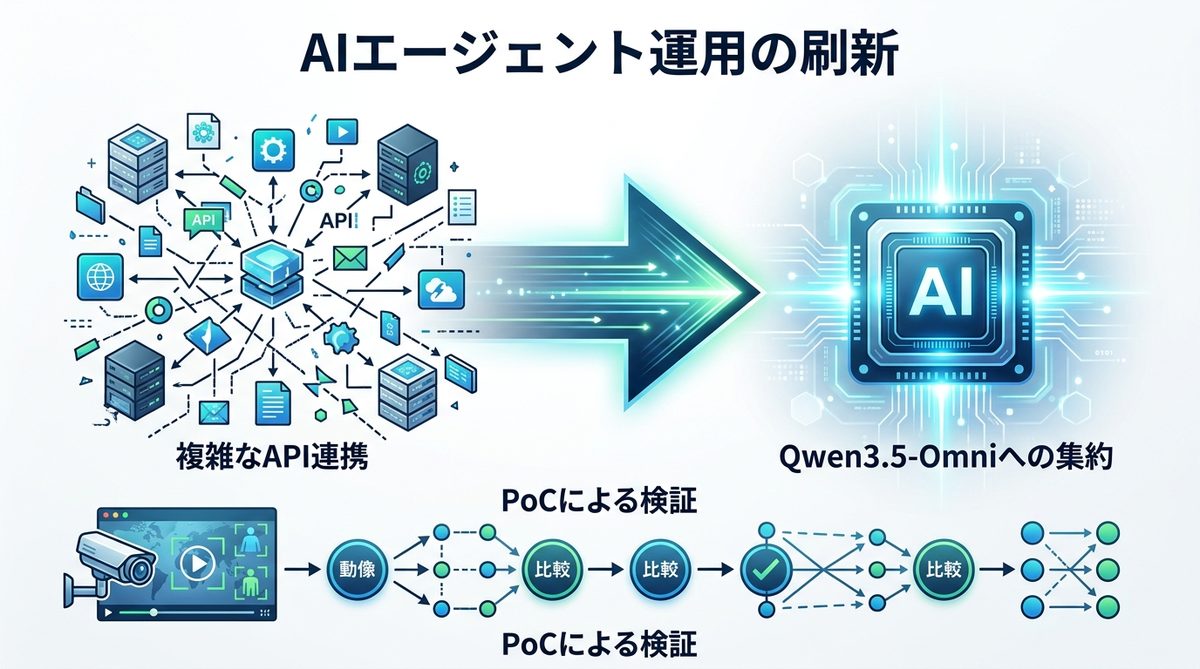
複数のAIツールを継ぎ接ぎして運用する時代は終わりを迎えつつあります。Qwen3.5-Omniへの集約は、運用効率を劇的に改善します。
複数のAPIを繋ぐ「管理コスト」からの解放
個別のAIツールを個別にAPI(プログラム同士を繋ぐ窓口)連携させる複雑な構成は、トラブルの原因となりがちです。単一のネイティブ・オムニモデルへ集約することで、メンテナンス工数を削減し、システム全体の信頼性を向上させることができます。
導入に向けたPoC(概念実証)の進め方
まずは既存のClaudeやGPT環境と併用し、小規模な業務から試してみてください。例えば、「顧客のフィードバック動画を解析する」といった特定のタスクをQwen3.5-Omniに任せ、処理時間や精度の違いを検証します。このステップを踏むことで、自社の業務フローにおける「ネイティブ化」の恩恵を確実に実感できるはずです。
関連記事:【2026年最新】Stable Video Diffusionとは?ビジネス活用とSora2との賢い使い分け
まとめ
Qwen3.5-Omniがもたらすインパクトをまとめます。
- ネイティブ・オムニモーダルの導入: 音声や動画の変換プロセスを排除し、AIの応答速度とニュアンス理解を別次元へ引き上げる。
- 3つのモデル形態の戦略的使い分け: 高度分析の「Plus」、リアルタイム対応の「Flash」、高速軽量の「Light」を業務に応じて最適配置する。
- 長尺処理とアジア圏への適性: 256Kのコンテキストと高い言語理解力により、日本企業の複雑な業務にも即座に貢献する。
既存の継ぎ接ぎ型運用から脱却し、まずはFlashモデルを使って、その圧倒的な即時性を自社の定型業務で体感してみてください。今すぐ試験導入の検討を始めましょう。




