
【比較検証】Claude Opus 4.7「xhigh」とは?コストと精度の最適解を徹底比較
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの導入により、業務の自動化が加速する一方で、モデルの選定や詳細設定による「コストと精度のバランス」が経営上の課題となっています。2026年4月にリリースされた「Claude Opus 4.7」と、新設定「xhigh」を使いこなすことは、組織の生産性を左右する重要な分岐点です。本記事では、なぜ「xhigh」がビジネス現場における最適解なのか、コストと性能のバランスから徹底解説します。
目次
Claude Opus 4.7「xhigh」とは?推論能力が飛躍的に向上した背景
AIエージェントがPCの中で優秀なアシスタントとして機能するためには、モデルの推論能力が極めて重要です。ここではOpus 4.7の立ち位置と、新設定「xhigh(エックスハイ)」の役割について解説します。
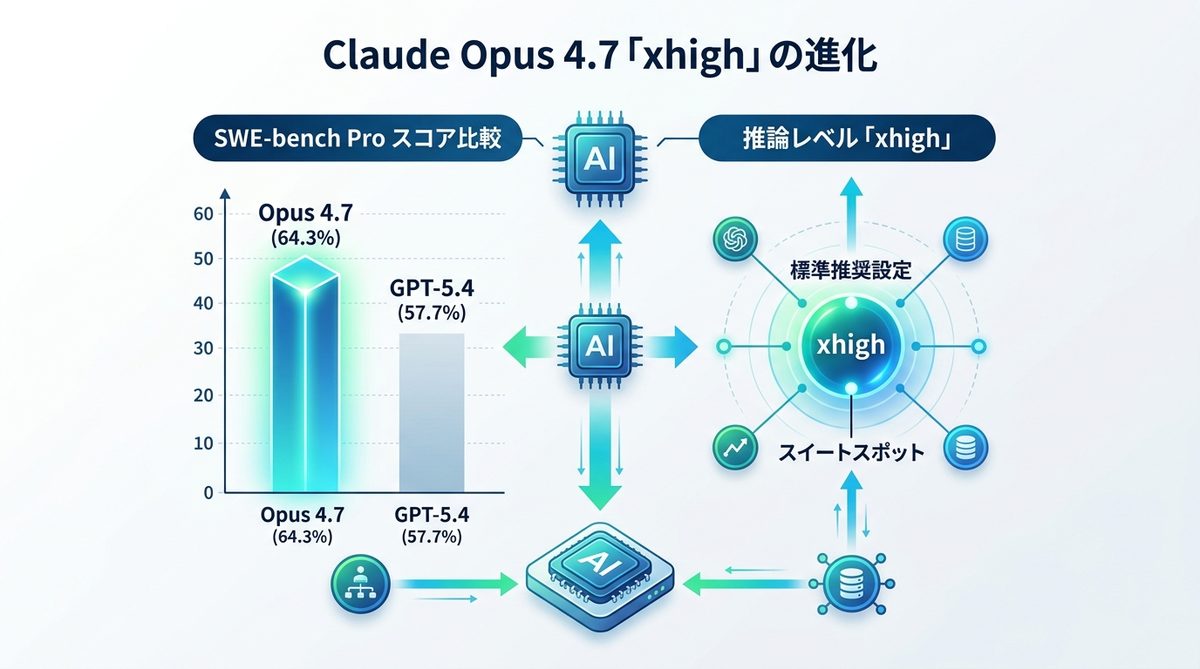
なぜ今、Opus 4.7なのか?SWE-bench ProでGPT-5.4を超えた実力(2026年4月リリース時点)
Claude Opus 4.7は、ソフトウェアエンジニアリング能力を測定するベンチマーク「SWE-bench Pro」において、64.3%という圧倒的なスコアを記録しました。これは2026年4月のリリース当時最新だったGPT-5.4(スコア57.7%)を上回る結果でした。なお、その後Opus 4.7の後継モデル「Opus 4.8」(SWE-bench Pro 69.2%)が2026年5月に公開されており、比較対象のGPTシリーズもGPT-5.6へと更新が進んでいます。いずれにせよAIエージェントは実務の現場で「指示を待つ存在」から「自律的にタスクを完遂する存在」へと進化を続けています。
「xhigh」が定義する新しい推論レベルと推奨される使いどころ
「xhigh」とは、Opus 4.7で新設された「努力レベル(Effort Level)」の指標です。従来の「high」と、最高精度の「max」の中間に位置する設定であり、Anthropicはコーディングや長時間の自律的なエージェントタスクにおいてはxhighを推奨する一方、それ以外の高度な推論タスクでは標準設定の「high」を推奨しています(Effortのデフォルト値は現在も「high」であり、xhighが全用途向けの公式標準というわけではありません)。なぜこの設定が重要かというと、過度な推論リソースを消費せずに、実務レベルで求められる高い精度を最も効率よく引き出せる「スイートスポット」だからです。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
【費用対効果を検証】「xhigh」と「max」の決定的な違いとROI
「最高の設定を使えばいい」という考え方は、ビジネスにおいては必ずしも正解ではありません。コストとのバランスを整理します。
成功率差わずか2.9%?「xhigh」が選ばれる理由
xhighとmaxの性能差は、SWE-bench Proの検証データに基づくと、わずか2.9%という結果が出ています。一方で、max設定を選択した際のコストは、xhighと比較して大幅に跳ね上がります。
| 設定項目 | 成功率(SWE-bench Pro) | コスト感(相対値) |
|---|---|---|
| xhigh | 64.3% | 1.0 (基準) |
| max | 67.2% | 2.0 (2倍) |
コスト2倍のリスクを回避し、効率的に成果を出すためのスイートスポット
わずか3%未満の成功率向上に対してコストが2倍になる設定は、ROI(投資対効果)の観点から見れば過剰投資です。ビジネスパーソンが追求すべきは、全タスクでmaxを使うことではなく、標準的なタスクはxhighで回し、どうしても突破できない困難なタスクのみをmaxに切り替える運用戦略です。
関連記事:Claude Opus 4.8の料金と実質コストを徹底分析|移行で知るべき3つの注意点

無視できない運用コストの罠:新トークナイザーによる「実質35%増」の正体
Claude Opus 4.7への移行に際して、必ず把握しておくべきがトークナイザー(文章をAIが理解できる最小単位に分解する処理)の変化です。
なぜ同じ文章量でもコストが増加するのか?新トークナイザーの仕組み
4.7から採用された新トークナイザーは、より緻密に言語を処理するため、従来のモデルと比較してトークン消費量が増える傾向にあります。これにより、同じプロンプトを入力しても、実質的に約35%のコスト増が発生します。
経営層が押さえておくべきAI運用コストの全体最適化
この35%のコスト増は「値上げ」と捉えるのではなく、「精度向上に対する適正な対価」と捉えるべきです。経営層は以下の3点を意識し、コストを管理してください。
- プロンプトの圧縮: 不要な修飾語を削り、AIの理解度を下げずにトークン数を減らす。
- キャッシュ活用: 頻繁に使用する定型文はシステムプロンプトに組み込む。
- タスクの振り分け: 重要度の低い定型処理には、より軽量なClaude Haikuモデルを併用する。
関連記事:【2026年最新】生成AI API導入の実戦ガイド|コスト・リスク・運用を最適化する実装戦略

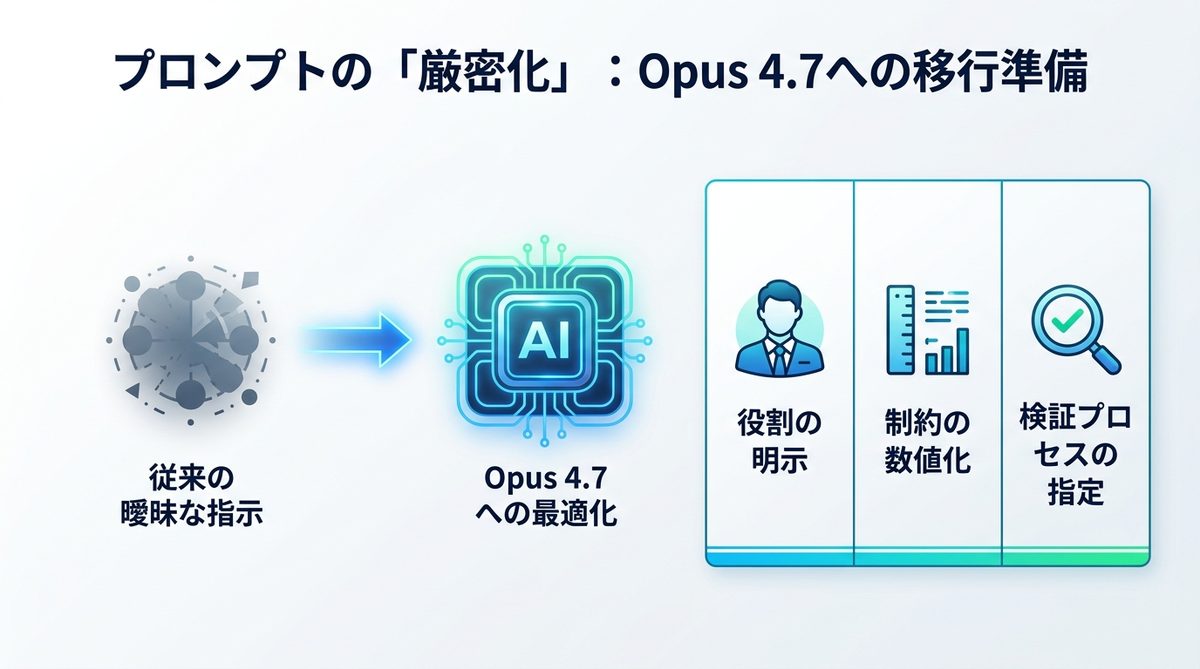
失敗しないための移行準備:プロンプトの「厳密化」を今すぐ進めるべき理由
Opus 4.7は賢くなった分、指示に対する「厳密性」を強く求めるようになりました。従来の「なんとなくの指示」では、性能を発揮できません。
指示追従性の強化がもたらす「以前のプロンプトが機能しない」リスク
4.7は推論能力が高いため、曖昧な指示を自分なりに解釈して実行しようとします。これが結果的に「こちらの意図とは違う成果物」を生成する要因となります。以前のモデルよりも、出力の形式や制約条件を明文化する必要があります。
AIエージェントの自律性を高めるための「指示の具体化」テンプレート例
指示の具体化を行う際は、以下の構成案を取り入れてください。
- 役割の明示: 「あなたは熟練のプロジェクトマネージャーです」
- 制約の数値化: 「回答は300文字以内、箇条書きで5点にまとめる」
- 検証プロセスの指定: 「出力前に自己検証を行い、矛盾がないか確認せよ」
関連記事:【2026年最新】ChatGPT 5.4の実力は?自律エージェントを「チームの一員」としてマネジメントする業務再構築戦略
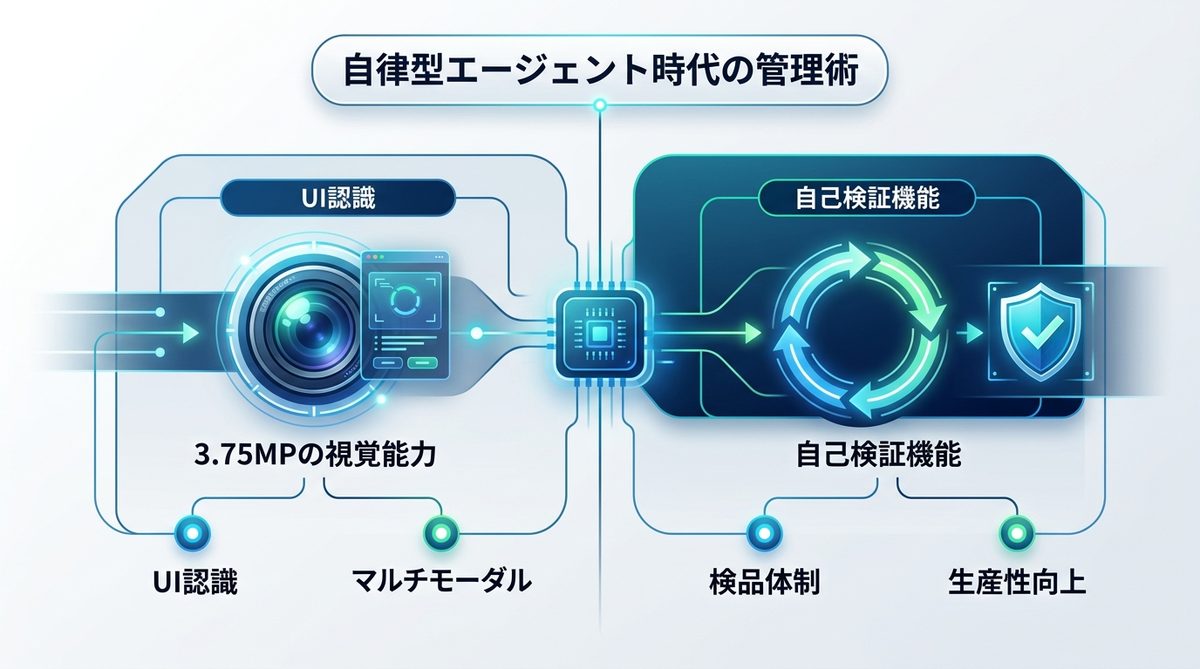
自律型エージェント時代の管理術:3.75MPの視覚能力と自己検証の力
Opus 4.7はマルチモーダル能力が大幅に進化しました。PC内のUIを認識する3.75MP(375万画素相当)の視覚処理能力は、業務を劇的に変えます。
視覚情報(3.75MP)を活用したマルチモーダル業務効率化の最前線
ブラウザ上の複雑な管理画面や、グラフの読み取り、手書きのメモ書きのデータ化など、テキストデータ化されていない情報を直接扱えるようになりました。これにより、スクリーンショットを介した指示が極めて正確になっています。
AIが自らミスを修正する「自己検証機能」をチーム生産性にどう組み込むか
Opus 4.7の強力な武器が「自己検証(Self-Correction)」です。作業を完了する前にAI自身がコードや内容をレビューさせるプロセスをプロンプトに組み込むことで、人間がチェックする時間を大幅に削減できます。これは、チーム全体の生産性を底上げする「AIによる検品体制」の構築を意味します。
関連記事:【2026年最新版】Claude for Excelの活用術|財務モデリング・デバッグをAIで超効率化する方法
まとめ
Claude Opus 4.7と「xhigh」設定への移行は、AIエージェントをビジネスの主戦力にするための重要な一歩です。最後に、今回の重要ポイントをまとめます。
- xhighは「最適解」: 性能とコストのバランスが最も優れており、まずはここを標準設定にする。
- ROIの管理: max設定は全自動化ではなく、難易度の高い限定的なタスクにのみ適用する。
- コスト構造の理解: 新トークナイザーによる35%のコスト増を許容し、プロンプトの効率化で相殺する。
- プロンプトの更新: 曖昧さを排除し、役割・制約・検証プロセスを定義した厳密な指示に書き換える。
- 視覚能力の活用: 3.75MPの視覚情報を利用し、テキスト入力以外の業務も自動化対象にする。
まずは、現在運用中のプロンプトを見直し、モデルをOpus 4.7の「xhigh」に切り替えて、その推論精度の向上を体感してみてください。今すぐAIエージェントチームの戦力化に着手しましょう。


