
【比較】DeepSeek V4 Pro vs Flash|コスト12倍の差をビジネスで使い分ける検証
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの運用コストが高騰し、GPT-5.5やClaude 4.7の利用料に頭を悩ませていませんか?2026年4月24日にリリースされた「DeepSeek V4」は、圧倒的な低コストでビジネスの常識を覆そうとしています。
本記事では、高性能な「Pro」と超高速・低コストな「Flash」のスペック差を徹底比較し、7月24日に迫るAPI廃止期限までに取り組むべき「コスト最適化の戦略」を解説します。
目次
DeepSeek V4 ProとFlash|スペックとコストの決定的な違い
DeepSeek V4シリーズは、用途に応じて2つのモデルを使い分けることで、パフォーマンスを維持しながらコストを最小化できる設計になっています。
ProとFlashの主要スペック比較と「12倍のコスト差」の正体
両モデルの最大の違いは、内部の知能(パラメータ)と、それに伴うコスト構造にあります。まずは以下の比較表をご覧ください。
| 項目 | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| パラメータ規模 | 1.6兆(アクティブ49B) | 284B(アクティブ13B) |
| 推論性能 | 業界最高水準(GPT-5.4級) | 高速・軽量 |
| 入力コスト/1Mトークン | $1.74 | $0.14 |
| 出力コスト/1Mトークン | $3.48 | $0.28 |
| 最適な用途 | 複雑な推論・開発 | 大量処理・要約 |
見ての通り、FlashはProに比べてコストが約12.4倍も安く設定されています。「アクティブ・パラメータ(実際に稼働する脳の大きさ)」が少ないFlashは、その分、反応速度が極めて速いのが特徴です。
なぜ「100万トークン」のコンテキストウィンドウがビジネスを変えるのか
DeepSeek V4は両モデル共通で「100万トークン」のコンテキストウィンドウ(記憶容量)を備えています。これは、従来のAIのように「長い資料を分割して読み込ませる」手間が不要になることを意味します。
比喩的に言えば、これまでAIに「本を数ページずつ破って読ませていた」状態から、一度の命令で「本1冊を丸ごと机に広げて答えさせる」状態に進化しました。これにより、ドキュメントの文脈を失うことなく、長大な契約書やマニュアル全体の整合性を保った分析が可能になります。
競合モデルとの単価比較グラフ
競合の最新フラッグシップモデルと100万トークンあたりの単価を比較すると、DeepSeek V4のコスト優位性が明確になります。
- GPT-5.4 / Claude 4.7: $10〜$20前後(高コストだが最高精度)
- DeepSeek-V4-Pro: $5.22(最高性能を維持しつつ低コスト)
- DeepSeek-V4-Flash: $0.42(圧倒的なコスト破壊)
この価格差は、特にエージェントを大量に走らせるビジネス現場において、月間のAPI予算を数分の1にするインパクトを持っています。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説

【業務別】DeepSeek V4 Pro vs Flashの「使い分け」正解リスト
コストを抑えつつ品質を維持するためには、業務の難易度に応じたモデルの「仕分け」が不可欠です。以下に3つの基準を示します。
1. Proを採用すべき「高難度・高機密業務」一覧
推論能力が求められる作業には、迷わずProを選択してください。
- 複雑なプログラミング(コーディング): 複数のファイルを跨ぐリファクタリングなど。
- 法的リスクのある文書チェック: 契約書の条項分析や、コンプライアンス監査。
- 戦略的な意思決定支援: 経営会議の議事録からの論点抽出や、市場予測モデルの構築。
2. Flashで十分!コストを極限まで下げる「定型・大量処理業務」一覧
繰り返し発生するルーチンワークは、Flashで処理するのが賢明です。
- 大量データの要約: 社内SNSやメールログのサマリー作成。
- RAG(検索拡張生成)の一次選別: 数千件の文書から、回答に必要な関連文書を絞り込む作業。
- 定型フォーマットのメール返信: 問い合わせ内容に基づいた一次回答の自動生成。
3. Web版UIでの切り替え方
DeepSeekのWebサイトでは、モデルの切り替えが非常に直感的です。
- Expert Mode(Pro): 画面上部のスイッチで選択。思考プロセスが深い「じっくり型」です。
- Instant Mode(Flash): 速度重視の場合に選択。即座にテキストが出力される「高速型」です。
関連記事:【検証】DeepSeek V4 vs GPT-5.5|APIコストを抑えて業務を自動化する「ハイブリッド戦略」とは?

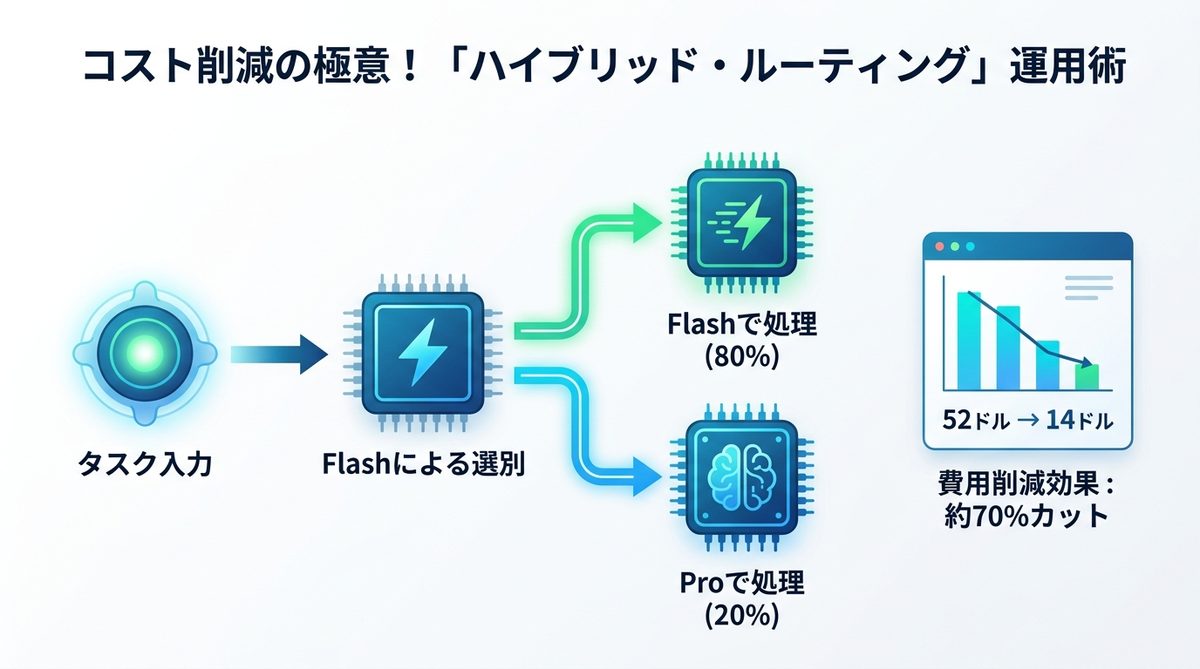
コスト削減の極意!「ハイブリッド・ルーティング」運用術
単一のモデルを使うのではなく、二つを組み合わせることでコストパフォーマンスを最大化できます。
品質とコストを両立する「AIエージェントの動的ルーティング」とは
「Flashで選別→Proで回答」というワークフローを構築してください。まずFlashに「このタスクは複雑か?」と判断させ、YesならProへ、NoならそのままFlashで処理させる手法です。これにより、全業務をProで行うよりもAPI費用を劇的に抑制できます。
ハイブリッド構成によるコストシミュレーション
例えば、月間1,000万トークンを処理する業務において、すべてProで行うと約52ドルかかります。これをFlashとのハイブリッド(8割をFlashへ移行)にすると、費用は約14ドルまで削減可能です。約70%以上のコストカットが実現できます。
関連記事:【徹底比較】Qwen3.6 vs Claude Opus 4.7|APIコストを激減させる業務活用ポートフォリオの作り方
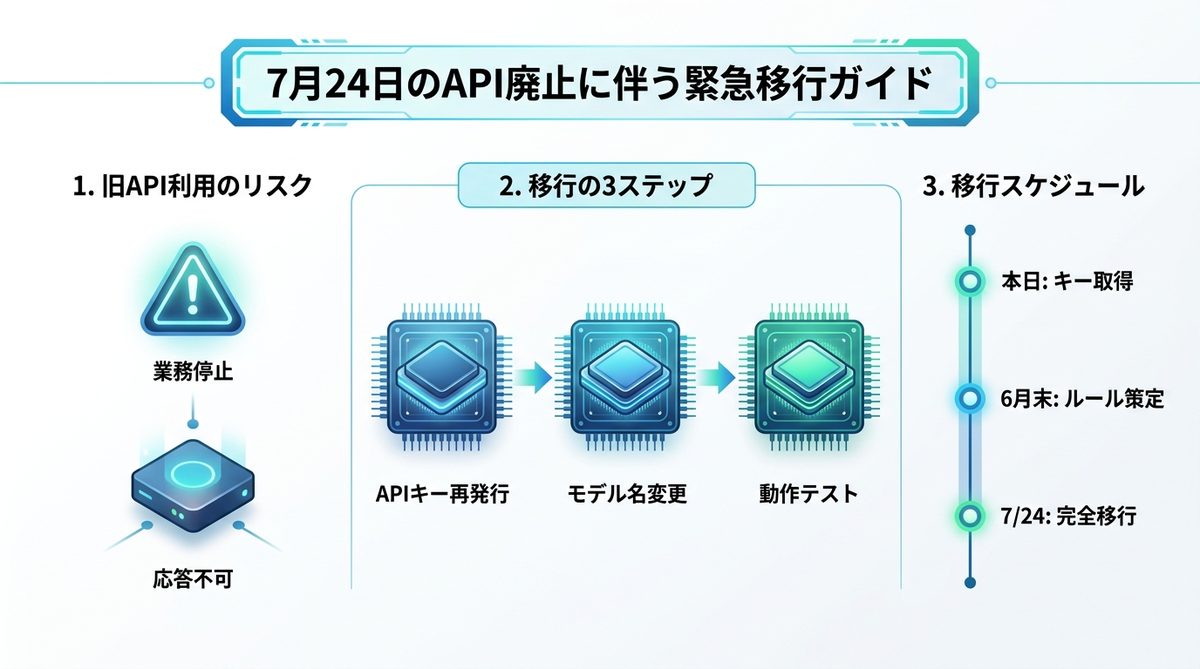
【重要】7月24日のAPI廃止に伴う緊急移行ガイド
既存のAPIを利用している場合、7月24日にはシステムが停止するリスクがあります。以下の手順で今すぐ対応しましょう。
1. 旧APIを使い続けるリスク
現在はFlashへ自動転送されていますが、これは一時的な措置です。7月24日以降は完全に廃止されるため、放置するとAIエージェントが突然応答しなくなり、業務が完全にストップします。
2. 今日からできるAPI移行ステップ
- APIキーの再発行: DeepSeek開発者コンソールで最新のV4用キーを取得します。
- ID書き換え: アプリケーションやエージェントの設定ファイルでモデル名を
deepseek-v4-proまたはdeepseek-v4-flashに変更します。 - テスト実施: 既存のプロンプトを流し、出力品質が変わらないか確認します。
3. システム担当者・経営者が押さえておくべき移行カレンダー
- 本日: APIキーの取得と、主要なエージェントのモデル変更テスト。
- 6月末まで: 業務ごとのPro/Flash振り分けルールの策定。
- 7月24日: 旧API廃止。完全移行の完了。
関連記事:【2026年最新】生成AI料金比較!目的別おすすめツールとROIを最大化する選び方
まとめ
DeepSeek V4の導入は、AI運用のコスト構造を劇的に改善する転換点です。ProとFlashを賢く使い分けることで、ビジネスの競争力を高めつつ、支出を最小限に抑えることができます。
- Pro: 複雑な推論・高機密業務に使用する。
- Flash: 大量データの要約やRAGの選別など、高速処理に使用する。
- 7月24日までに: 旧APIから新モデルへ必ず書き換える。
今すぐAPIの設定画面を開き、モデルの切り替えとテストに着手しましょう。運用の最適化が、貴社のDXを加速させます。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


