
DiffusionGemmaとGemma 4の違いは?速度と品質で比較
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIモデルの選定において、「速度」を優先すべきか、「品質」を優先すべきか迷うことはありませんか?特にローカル環境でモデルを動かす場合、生成の速さは作業効率やユーザー体験に直結します。本記事では、Googleから発表された高速モデル「DiffusionGemma」と、多機能な標準モデル「Gemma 4」の根本的な違いを解説し、どちらを選ぶべきかの判断基準を提示します。
この記事に対する編集部の見解
- 同じGemmaでもDiffusionGemmaは高速特化、Gemma 4は品質重視の別物
- ローカルで動かす開発者向けで、ChatGPTのような一般的な使い方とは土俵が違う
- 速度重視ならDiffusionGemma、品質重視ならGemma 4と目的で選ぶのが正解
目次
DiffusionGemmaとGemma 4の違い
DiffusionGemmaは「速さに特化した実験的モデル」であり、Gemma 4は「品質を重視した多機能な定番モデル」です。DiffusionGemmaは従来のLLM(大規模言語モデル)の常識を覆す生成方式を採用しており、特定のユースケースで圧倒的なパフォーマンスを発揮します。
まずは両者の主要な違いを以下の比較表でスキャンしてください。
| 項目 | DiffusionGemma | Gemma 4 |
|---|---|---|
| 方式 | 拡散型(並列生成) | 自己回帰型(逐次生成) |
| 速度 | 極めて速い(最大4倍速) | 公式サイトでご確認ください |
| 品質 | 実験的・限定的 | 高品質(標準) |
| 主な用途 | 高速な試作・非線形な編集 | 本番運用・精密な長文作成 |

そもそもDiffusionGemmaとは?
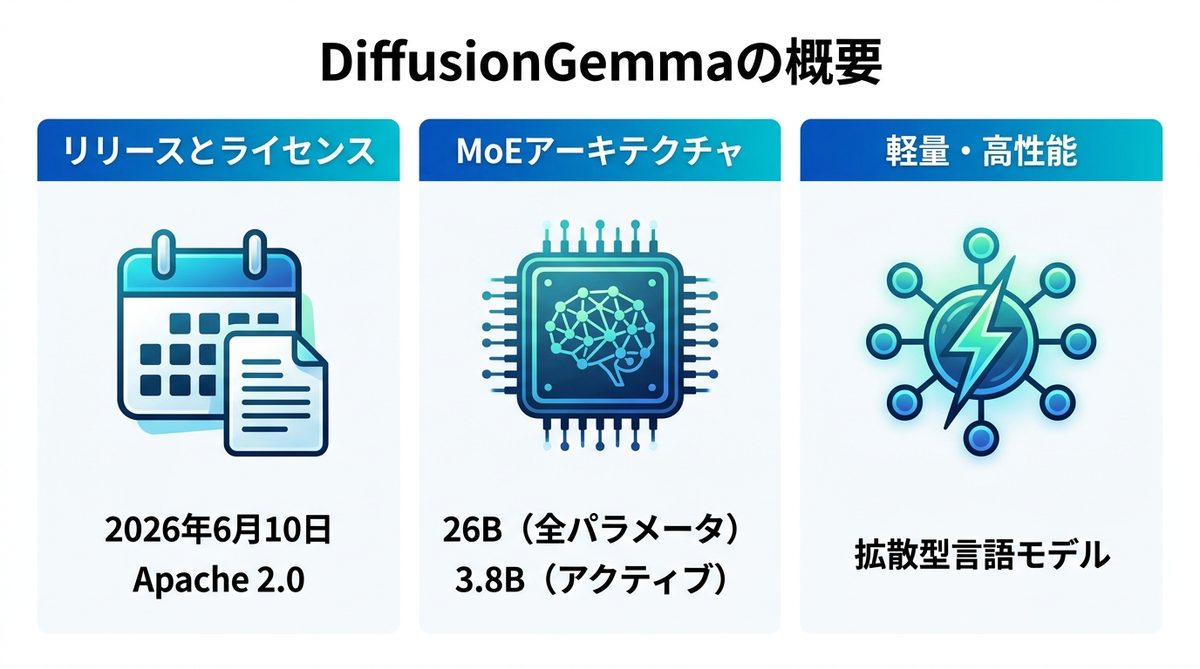
DiffusionGemmaは、2026年6月10日にリリースされたオープンな「拡散型」言語モデルです。Google AI for Developersなどで詳細が公開されており、ライセンスは商用利用も可能なApache 2.0が採用されています。
最大の特徴は、モデルのサイズです。総パラメータ数は26B(260億)のMoE(Mixture of Experts)構成ですが、推論時に実際に稼働するアクティブパラメータ数は約3.8Bに抑えられています。これにより、高い表現力を維持しつつ、軽量な動作を実現しています。
根本的な違いは「文章の作り方」
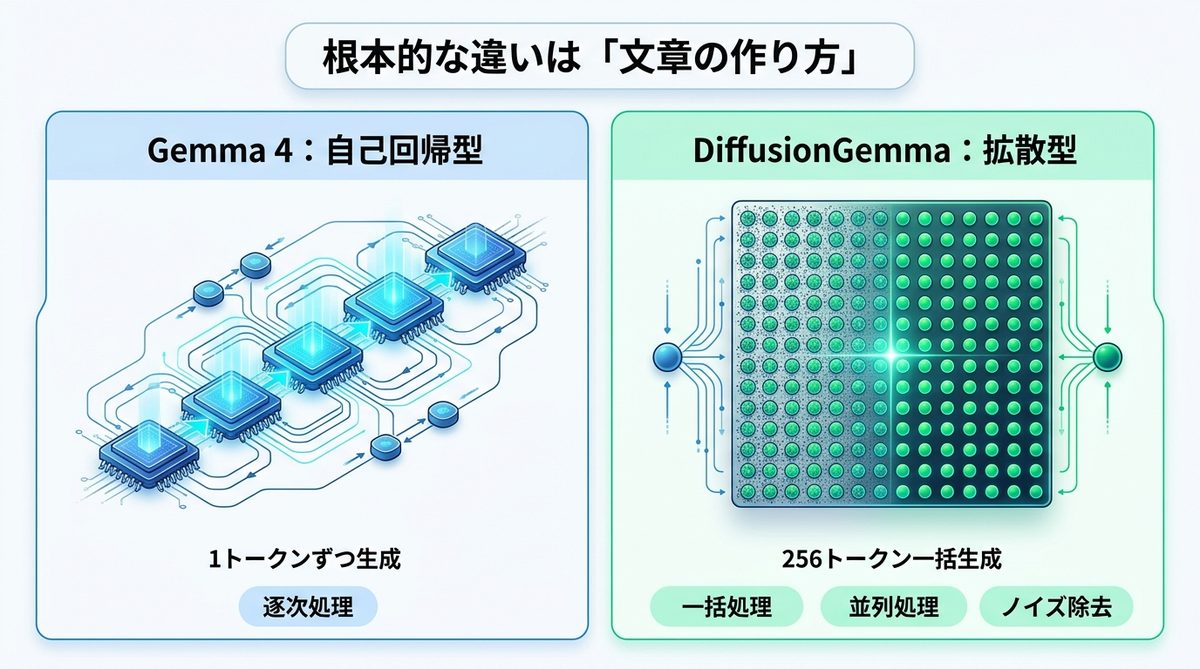
DiffusionGemmaとGemma 4の最大の違いは、内部的な「文章の組み立て方(デコードアルゴリズム)」にあります。
Gemma 4:自己回帰型
Gemma 4を含む一般的なLLMは「自己回帰型(Autoregressive)」と呼ばれます。これは、過去の単語から「次に来る最も確率の高い1トークン」を順番に予測していく方式です。左から右へ1文字ずつ丁寧に書き進めるため、一貫性と論理性に優れた文章を生成できるのが強みですが、前の単語が決まるまで次の単語を生成できないという「順番待ち」が速度のボトルネックとなります。
DiffusionGemma:拡散型
一方、DiffusionGemmaは画像生成AI(Stable Diffusionなど)で使われる「拡散型(Diffusion)」の仕組みをテキスト生成に応用した「discrete diffusion」を採用しています。
この方式では、まず256トークン分の「ノイズ(砂嵐のような状態)」の下書きを一度に用意します。そこから何度もノイズを取り除くプロセス(ステップ)を繰り返すことで、256トークンのブロックを並列で同時に整えていきます。また、文脈を捉える際も「双方向注意(Bidirectional Attention)」を用いるため、従来のLLMよりもBERTなどのエンコーダーに近い、文脈全体を俯瞰して整合性を取るアプローチとなっています。
速度:DiffusionGemmaは最大4倍速
DiffusionGemmaを導入する最大のメリットは、その圧倒的な生成速度です。従来の自己回帰型モデルと比較して、最大で4倍もの高速化を実現しています。
ブロック並列生成の仕組み
前述の通り、1トークンずつ順番に待つのではなく、256トークンという大きなブロック単位で一気に並列生成を行うため、待機時間が劇的に短縮されます。これにより、GPUの計算リソースを極めて効率的に活用でき、瞬時に大量のテキストを出力することが可能になりました。
実際の生成速度
具体的なベンチマーク数値を見ると、その差は歴然です。
- H100(データセンター向けGPU):1,000+ tok/s(1秒間に1,000トークン以上)
- RTX 5090(ハイエンド民生GPU):700+ tok/s
この速度は、人間が読むスピードを遥かに超えており、リアルタイム性が極めて重要なアプリケーションにおいて強力な武器となります。

品質:本番運用ならGemma 4
速度面で圧倒的な優位性を持つDiffusionGemmaですが、トレードオフとして「品質」には注意が必要です。
Gemma 4より品質は低い
Googleの公式ドキュメントでは、DiffusionGemmaの生成品質がGemma 4に及ばないことが明言されています。あくまで「速度と実験的な生成手法」にフォーカスしたモデルであり、現時点での「知能の高さ」や「指示遵守能力」の標準は依然としてGemma 4にあります。
速度とのトレードオフ
拡散型モデルは、限られた反復回数(ステップ数)でブロック全体を無理やり整えるため、自己回帰型のように1トークンずつ緻密に論理を積み上げるプロセスに比べると、細部の整合性が甘くなる傾向があります。特に、複雑な推論を必要とする回答や、非常に長い文脈の維持においては、Gemma 4の方が安定した結果を出力します。
スペック・対応入力の比較
ここでは、より詳細な技術スペックを比較します。特に対応入力と出力形式の違いに注目してください。
| 仕様 | DiffusionGemma | Gemma 4 |
|---|---|---|
| パラメータ数 | 26B MoE (Active 3.8B) | 公式サイトでご確認ください |
| 生成方式 | 拡散型 (Discrete Diffusion) | 自己回帰型 |
| 速度 | 最大4倍速 | 公式サイトでご確認ください |
| 品質 | 実験的・限定的 | 高品質(標準) |
| 入力対応 | テキスト / 画像 / 動画 | テキスト / 画像 / 動画 / 音声 |
| 出力形式 | テキストのみ | 公式サイトでご確認ください |
| ライセンス | Apache 2.0 | Apache 2.0 |
DiffusionGemmaは音声入力には対応しておらず、出力もテキストのみに限定されています。音声入力を含むマルチモーダルな対応を求める場合は、Gemma 4の最新仕様を公式サイトでご確認ください。
ハードウェア要件の違い
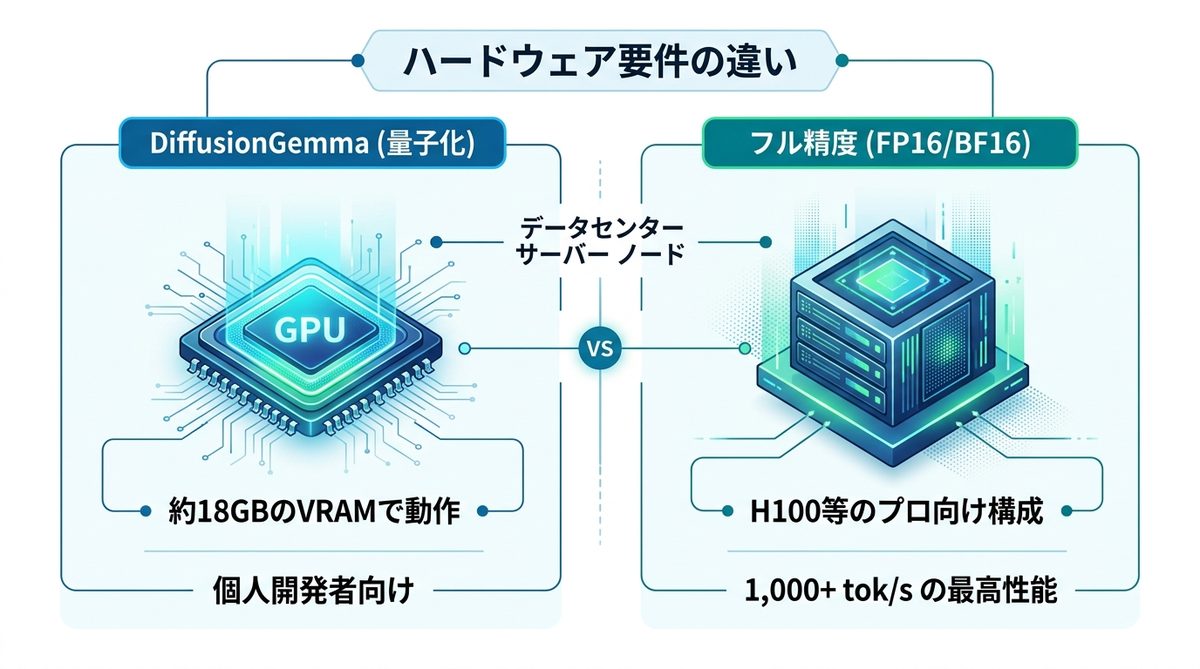
ローカル環境でこれらのモデルを運用する場合、ビデオメモリ(VRAM)の容量が重要なハードルとなります。
量子化:18GBの民生GPU
DiffusionGemmaは、量子化(4-bitや8-bitへの圧縮)を施すことで、VRAM容量が約18GB程度の環境でも動作可能です。これは、NVIDIA GeForce RTX 5090といったハイエンドな民生用GPUであれば十分に手が届く範囲です。個人の開発者や研究者がローカルで試作を行うには、非常にバランスの良いサイズ感と言えるでしょう。
もし、ご自身の環境で設定中にエラーが出るなど、DiffusionGemmaがローカルで動かない時は、ドライバのバージョンやランタイムの設定を確認してみてください。
フル精度:H100級が必要
一方で、モデル本来の最高性能(1,000+ tok/s)をフル精度(FP16/BF16)で引き出すためには、H100などのデータセンター向けGPUが推奨されます。エンタープライズ用途で大規模なリクエストを捌く場合は、こうしたプロフェッショナル向け構成が標準となります。
どちらを選ぶ?用途別の使い分け
最後に、あなたの用途に合わせてどちらを選ぶべきかまとめます。
DiffusionGemmaの適性
- ローカルでの対話ワークフロー:低遅延が求められるチャットUIなど。
- インライン編集:文章の一部を高速で書き換えたり、修正案を即座に提示したりする作業。
- 高速反復・試作:プロンプトの調整を何度も繰り返し、短時間で多くのバリエーションを確認したい場合。
- 非線形なテキスト生成:文章の途中を埋めたり、全体を並列で書き換えたりする、拡散型ならではの柔軟な生成プロセス。
Gemma 4の適性
- ビジネスの本番運用:高い信頼性と論理的な文章出力が必要なカスタマーサポートなど。
- 高品質が要る文章:レポート作成、創作活動、精密な翻訳作業。
- 音声入力が必要な場面:音声での対話や、マルチモーダルな入力を含む複雑なレスポンスが必要な場合。

まとめ
DiffusionGemmaとGemma 4は、「どちらかが優れている」という関係ではなく、利用シーンに応じて使い分けるべき補完的な存在です。
「速い=正解」ではありません。圧倒的な速度が体験価値を生むローカルでの対話や試作フェーズでは DiffusionGemmaが輝きますが、出力の正確性や音声入力といった品質面や多機能さを重視するなら、Gemma 4が依然として王道です。
まずはDiffusionGemmaの「爆速」をローカル環境で体感し、その特性を理解した上で、ご自身のプロジェクトに最適なモデルを選択してください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- 同じGemmaでもDiffusionGemmaは高速特化、Gemma 4は品質重視の別物
- ローカルで動かす開発者向けで、ChatGPTのような一般的な使い方とは土俵が違う
- 速度重視ならDiffusionGemma、品質重視ならGemma 4と目的で選ぶのが正解
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


