
【比較検証】AIの「PDF読み取りミス」を防ぐには?MinerUと既存ツールを比較してわかった構造化の重要性
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントに社内ドキュメントを読み込ませた際、回答が的外れになったり、重要な数値が無視されたりした経験はありませんか。その原因の多くは、読み込ませたPDFデータの「構造情報」が正しく抽出できていないことにあります。
本記事では、AIエージェントのパフォーマンスを劇的に改善するPDF解析ツール「MinerU」の強みと、既存ツールとの比較を通じて、目的に合わせた最適なツールの選び方を解説します。
目次
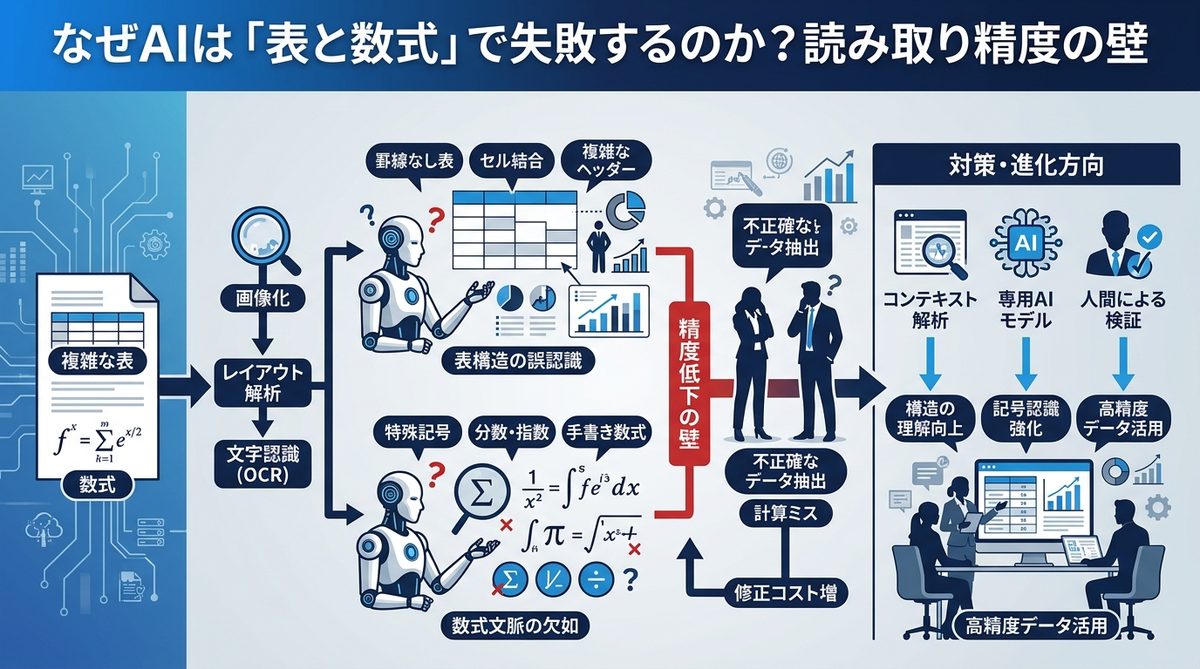
なぜAIは「表と数式」で失敗するのか?読み取り精度の壁
AIにとってPDFは単なる文字の羅列ではありません。レイアウトや表組みを理解させるには、高度な構造解析が必要です。
単純なテキスト抽出では見落とされる「構造情報」とは
AIエージェントが正確に回答するためには、単に文字を拾い上げるだけでなく、その情報の「役割」を理解する必要があります。これを「構造情報」と呼びます。具体的には以下のような要素です。
- 見出しと階層構造: どの項目が親で、どの項目が子であるかという親子関係
- 表の論理構造: 行と列の交差によるデータの意味(どの値がどのカテゴリに属するか)
- 数式の数学的構造: 分数やべき乗がどの数字にかかっているかという演算上のつながり
これらが欠落したデータは、AIにとって「バラバラになったジグソーパズルのピース」のようなものです。ピースの絵柄はわかっても、全体像が描けないため、AIは「なんとなく」で回答せざるを得ません。
OCR(光学文字認識)の限界と「構造解析」へのパラダウムシフト
従来のOCR(光学文字認識)は、「画像の中の文字をテキストデータに変換する」ことだけを目的としていました。これに対して「文書レイアウト解析」は、文書の構成要素を丸ごと理解します。
人間が本を読むとき、目次があることで内容を即座に把握できるように、AIにも「どこが見出しで、どこが注釈か」というタグ付け(メタデータの付与)が必要です。この構造解析への意識転換こそが、AIエージェントの回答精度を向上させるための第一歩なのです。
関連記事:【GoogleのAI】NotebookLMとは?GeminiやAIブラウザとの違いを解説
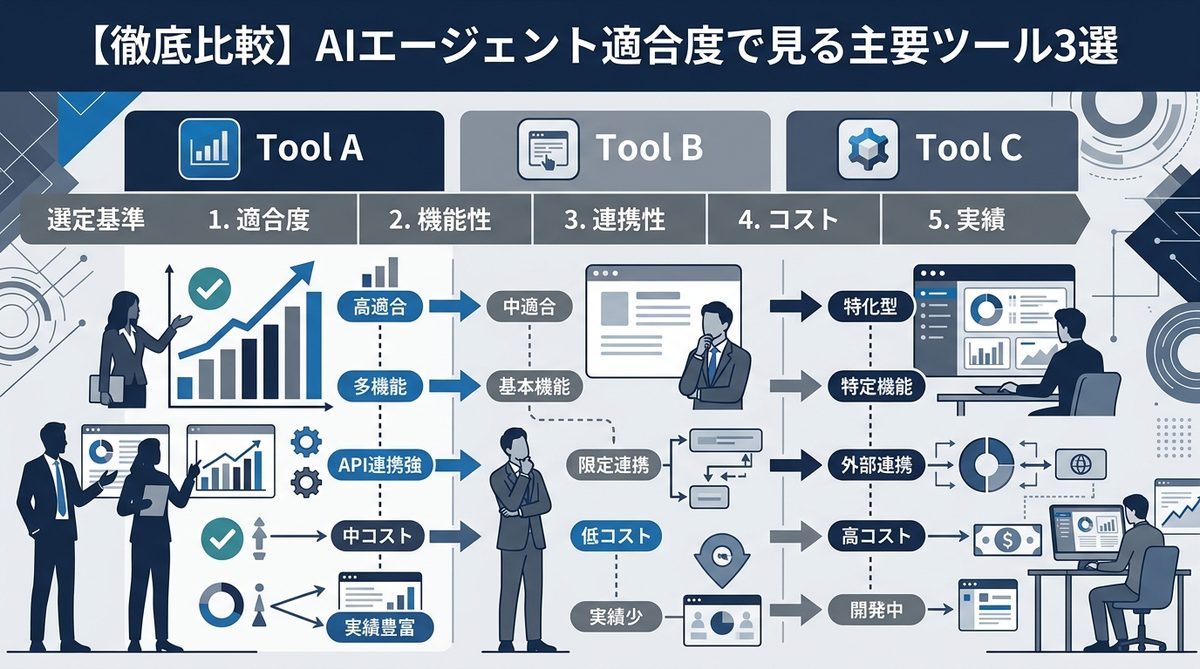
【徹底比較】AIエージェント適合度で見る主要ツール3選
PDFをAIに最適化するための主要なツールを、AIエージェントとの相性という視点で比較しました。
AIエージェント適合度 比較表
| ツール名 | 構造解析精度 | 処理速度 | 特徴 |
|---|---|---|---|
| MinerU | 極めて高い | 普通 | 数式・表のマークダウン化に特化 |
| Marker | 高い | 速い | バランスが良く汎用性が高い |
| PyMuPDF | 低い | 非常に速い | 構造解析不要なテキスト抽出向け |
高精度・高機能な「MinerU」―複雑な技術資料の解析に最適
MinerUは、OpenDataLabが開発したオープンソースの文書解析ツールです。最大の特徴は、PDFをAIが最も得意とする「Markdown(マークダウン:軽量マークアップ言語)」形式に変換する能力です。特に、複雑な表のセル結合や、LaTeX形式での数式出力において圧倒的な精度を誇ります。研究論文や仕様書など、正確性が求められるドキュメントの処理には欠かせません。
処理速度と手軽さの「Marker」―汎用的な文書処理におけるバランス
Markerは、高速かつ高精度な変換が可能なツールです。MinerUほど複雑なレイアウト解析に特化しているわけではありませんが、一般的なビジネス文書であれば十分に高い精度でMarkdown化できます。「大量の社内規定を一括でAIに取り込みたい」といった、スピードと精度の両立が求められる現場に適しています。
圧倒的スピードの「PyMuPDF」―単純なテキスト抽出の選択肢
PyMuPDFは、構造解析よりも「テキストの抽出」に特化したライブラリです。レイアウトが単純な報告書や、数式が含まれない長文テキストであれば、これだけで十分なケースがほとんどです。解析に時間をかけず、大量の文書をさばく場合に適しています。
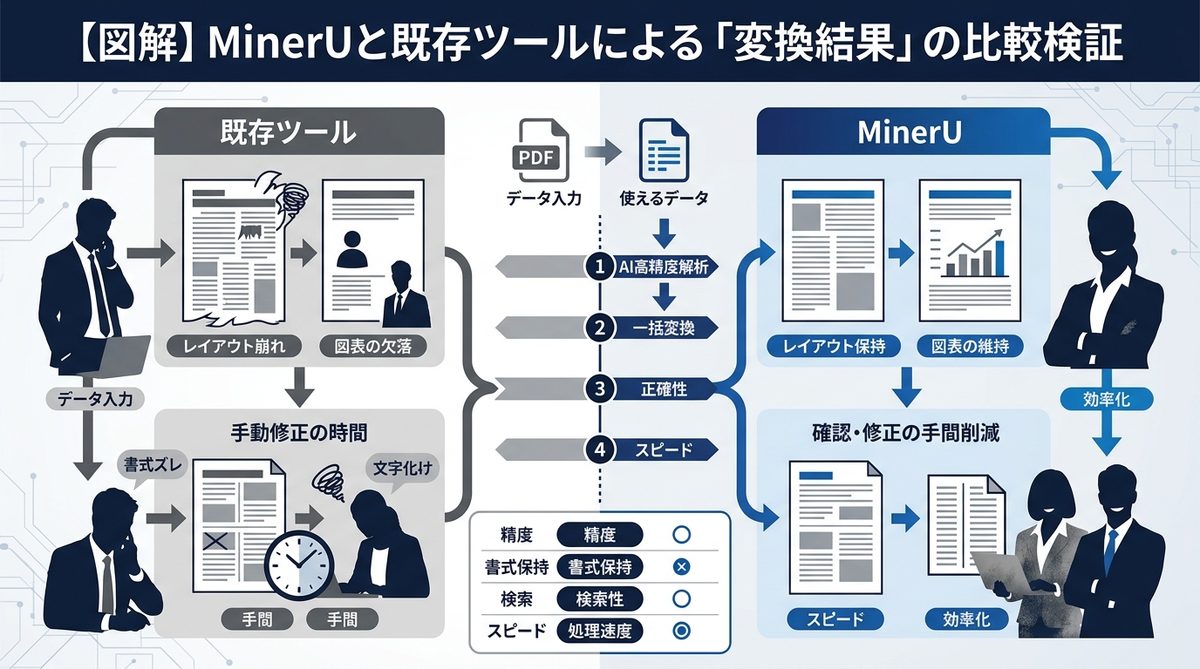
【図解】MinerUと既存ツールによる「変換結果」の比較検証
ここでは、PDF解析の質がどれほどAIの出力に影響するかを視覚的に解説します。
Before/Afterで見る「表形式」のAI理解度の差
- 従来(OCR)の結果: 表の中身がスペースや改行でバラバラになり、「行」と「列」の意味が消失。「値」と「項目」の結びつきがAIには判別不能になります。
- MinerUの結果: 表がMarkdownのテーブル形式(
| 項目 | 値 |)で綺麗に整形されます。これにより、AIは「どの値がどのカテゴリのものか」を即座に認識し、正確な集計や比較が可能になります。
数式や図解の認識がAIエージェントの回答精度に与える影響
例えば、PDF内の数式が誤変換されると、AIは計算式を読み違え、誤った回答を提示します。MinerUは数式をLaTeX(ラテックス:数式記述用言語)として抽出できるため、AIエージェントの推論エンジン(計算能力)と直接連携させることが可能です。この「構造の正しさ」が、AIのハルシネーション(もっともらしい嘘)を減らす鍵となります。
関連記事:【2026年最新】ChatGPT 5.4の実力は?自律エージェントを「チームの一員」としてマネジメントする業務再構築戦略
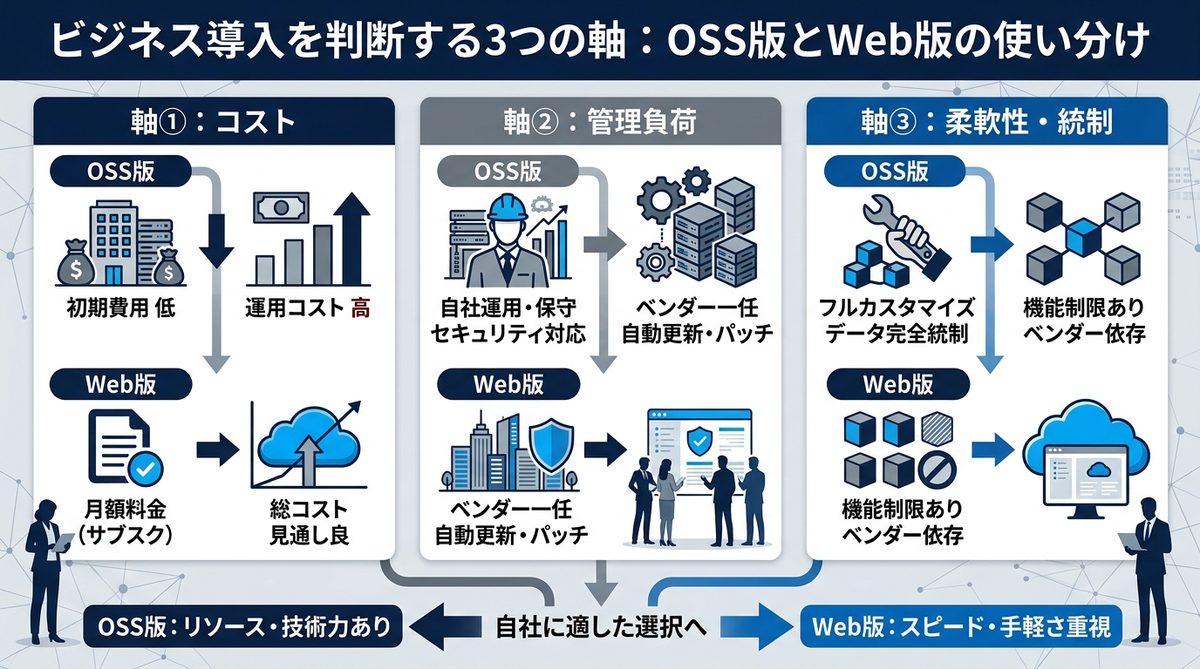
ビジネス導入を判断する3つの軸:OSS版とWeb版の使い分け
MinerUを導入する際は、自社のセキュリティ要件やコスト感に応じた判断が必要です。
セキュリティ基準で選ぶ:社内機密と汎用データの境界線
- 社内機密情報: 外部にデータを出せない契約書や未公開の製品資料は、OSS(オープンソースソフトウェア)版をローカル環境にインストールして使用してください。データが外部サーバーに送信されることはありません。
- 汎用的な公開資料: 機密性の低いレポートや公開論文などは、MinerUが提供するWebサービス版(mineru.net)を活用することで、環境構築の手間を省き、すぐに変換を開始できます。
コスト対効果:社内エンジニアのリソース vs 利用料金
OSS版はライセンス費用が無料ですが、環境構築やGPU(画像処理装置)の確保にエンジニアのリソースが必要です。一方で、Web版は利用量に応じた従量課金となるため、初期投資を抑えたい場合や、社内エンジニアが不足している場合にはWeb版から試すのが合理的です。
AIエージェントの構築環境に合わせた統合のヒント
変換後のMarkdownファイルは、Claude CodeやCursorといった開発支援AIの「コンテキスト(記憶容量)」に直接流し込むのが最も効率的です。RAG(検索拡張生成)システムを構築する場合は、このMarkdownファイルをベクターデータベース(ベクトル形式のデータ保存先)に格納することで、検索精度が飛躍的に向上します。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
まとめ
AIエージェントの性能を最大化するためには、PDFの「見た目」ではなく「構造」をAIに渡すことが不可欠です。本記事の要点は以下の通りです。
- PDFの構造解析は必須: 表や数式を正しく認識させないと、AIの回答精度は向上しない。
- 適材適所のツール選択: 高精度な解析には「MinerU」、バランス重視には「Marker」、単純抽出には「PyMuPDF」を選ぶ。
- セキュリティとコスト: 社内機密ならローカル完結のOSS版、手軽さ優先ならWeb版を活用する。
まずは貴社の資料の中で、特にAIが読み間違えやすい「表を含むPDF」を1つ選び、MinerUで変換結果を試してみてください。精度の違いを実感したその瞬間から、AIエージェントとの協力体制は次のフェーズへ進みます。今すぐ適したツールを導入し、PDF活用を自動化しましょう。


