
【機密情報】NotebookLMの学習に使われる?原則非学習だが例外も
 AIエージェントナビ編集部
AIエージェントナビ編集部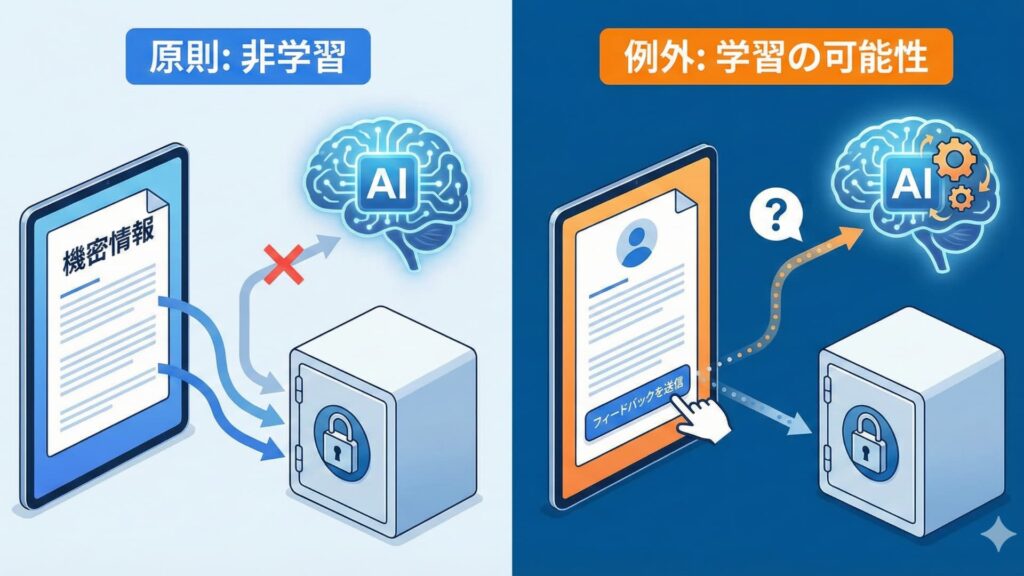
「社外秘の資料をAIに読み込ませたら、勝手に学習されて情報が漏れるのでは?」
2026年現在、Googleの高性能AIアシスタントツール「NotebookLM」の利用が広まる中、多くの企業や個人がこのような不安を抱えています。
結論から言えば、NotebookLMに入力したデータは、原則としてGoogleのAIモデルの再学習には使用されません。
しかし、「原則」という言葉が示す通り、特定の条件下では「例外」も存在します。
本記事では、NotebookLMの学習ポリシーの現状、なぜ学習せずに回答できるのかという仕組み、そして企業が機密データをAIの学習から絶対に守るための具体的な方法を解説します。
目次
1. 「原則として学習には使われない」の真意
NotebookLMの最大の特徴は、あなたがアップロードしたPDF、Googleドキュメント、音声ファイルなどの「特定の資料(ソース)」のみを情報源として回答を生成する点です。
2026年時点のGoogleの公式見解では、ユーザーがNotebookLMに入力したデータ(資料、質問、回答)は、Googleの基盤モデルの改善やトレーニングには使用されないと明言されています。
これは、あなたがNotebookLMに企業の機密データを入力したとしても、その情報が世界中の他のユーザー向けのAI回答に使われることはない、ということを意味します。この「非学習」の原則が、ビジネスシーンでNotebookLMが注目される大きな理由の一つです。
2. なぜ学習せずに回答できるのか?仕組みを解説
そもそも、なぜNotebookLMはデータを「学習」しないのに、その内容を理解して回答できるのでしょうか? その仕組みを理解すると、安全性をより深く納得できます。
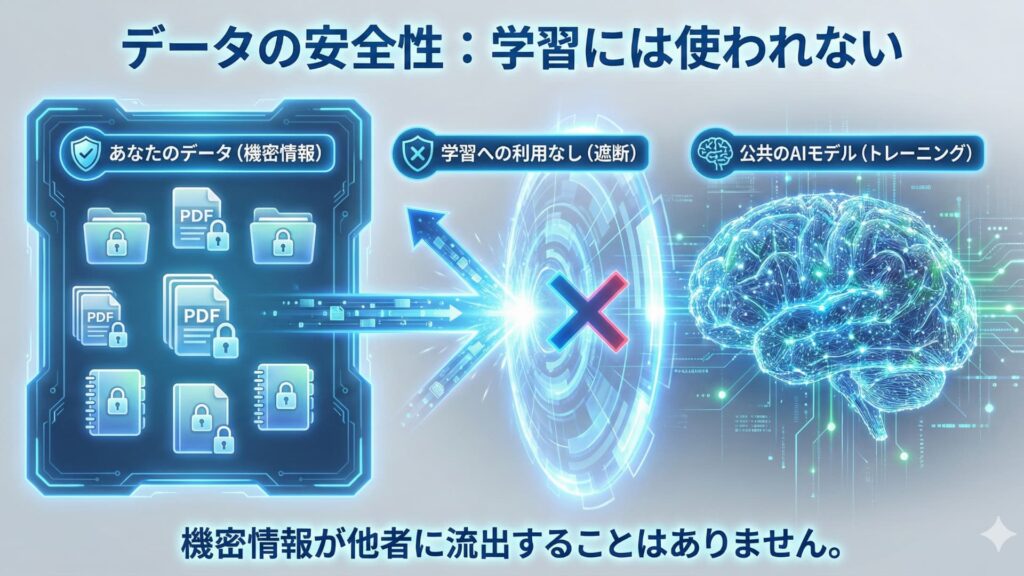
「学習(Training)」と「推論(Inference)」の違い
AIの動作は大きく分けて「学習」と「推論」の2段階があります。
-
学習(Training): 大量のデータを読み込み、知識やパターンを記憶してAIモデルそのものを賢くするプロセスです。人間で言えば、学校で教科書を読んで知識を身につける段階です。
-
推論(Inference): 学習済みのAIモデルが、与えられた質問に対して回答を生成するプロセスです。人間で言えば、テストで問題を解く段階です。
NotebookLMは「カンニングペーパー」を見ているだけ
NotebookLMが回答を生成する際に行っているのは「推論」のみです。
あなたが資料をアップロードすると、NotebookLMはその資料を一時的な「専用の辞書(カンニングペーパー)」として認識します。質問を投げかけると、AIは学習済みの一般的な知識を使わずに、その「専用の辞書」の中から関連する情報を探し出し、それをまとめて回答します。
この技術はRAG(Retrieval-Augmented Generation:検索拡張生成)と呼ばれます。AIは資料の内容を「記憶」しているのではなく、質問されるたびに資料を「参照」しているだけなのです。そのため、元のAIモデル自体があなたのデータで賢くなる(学習する)ことはありません。
関連記事:【GoogleのAI】NotebookLMとは?GeminiやAIブラウザとの違いを解説
3. 「例外」もある? データが確認されるケース
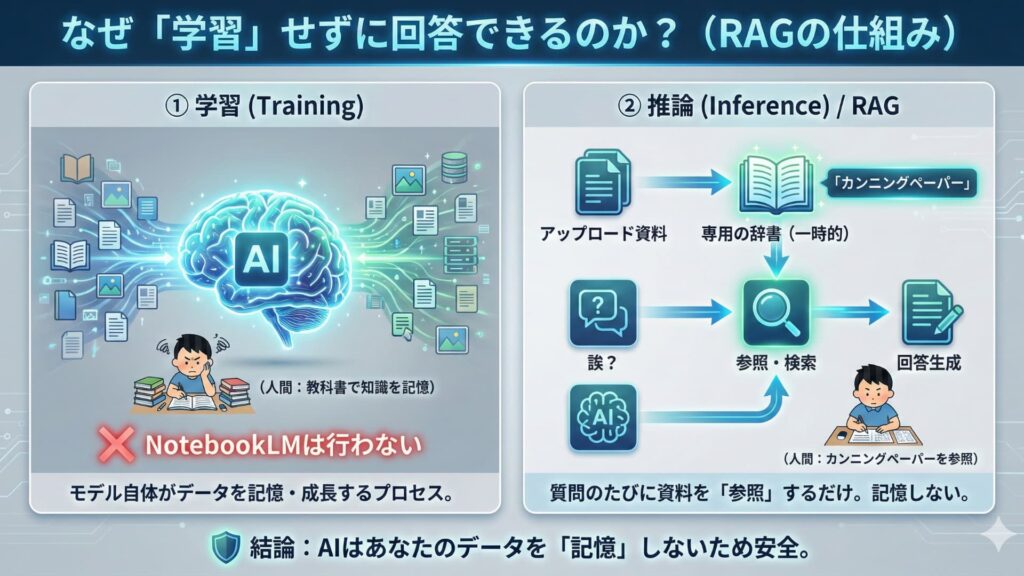
仕組み上は安全ですが、運用上「絶対にデータが外部(Google側)に渡らない」と言い切れない「例外」が存在します。
例外①:フィードバックを送信した場合
AIの回答に対して「グッド(👍)」「バッド(👎)」評価を付けたり、改善のためのコメントを送信したりした場合、そのやり取りの内容が人間のレビュアーによって確認される可能性があります。これはAIの精度向上を目的としたものですが、データが第三者(Googleのスタッフ)に見られるリスクとなります。
例外②:個人のGoogleアカウントを利用している場合
個人の無料アカウント(@gmail.com)を使用している場合、利用規約上、不適切なコンテンツの防止や技術的な問題解決のために、データがシステム的にスキャンされたり、限定的に確認されたりする可能性が完全に排除されているわけではありません。
4. 企業がデータを絶対に学習させない・守る方法
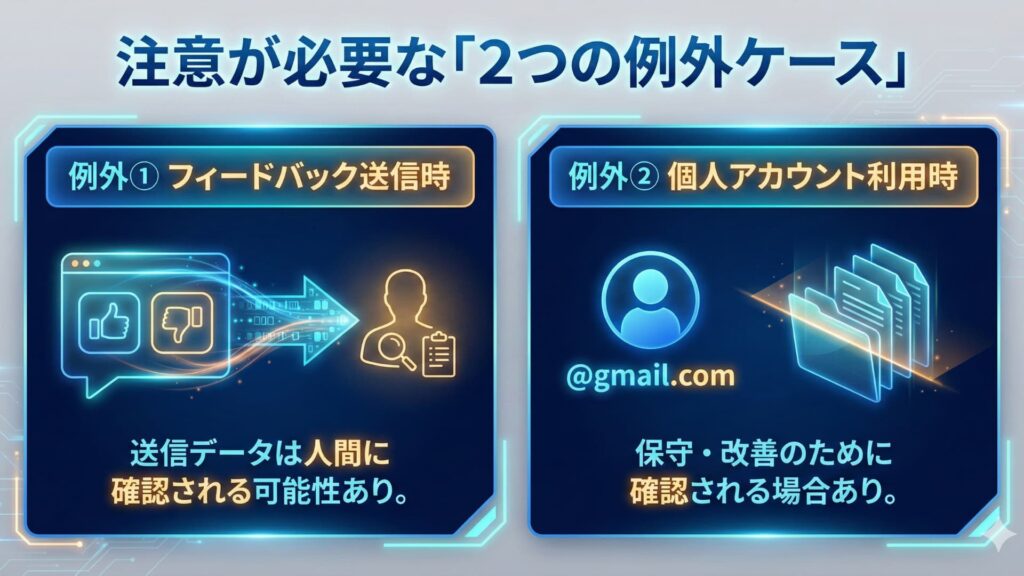
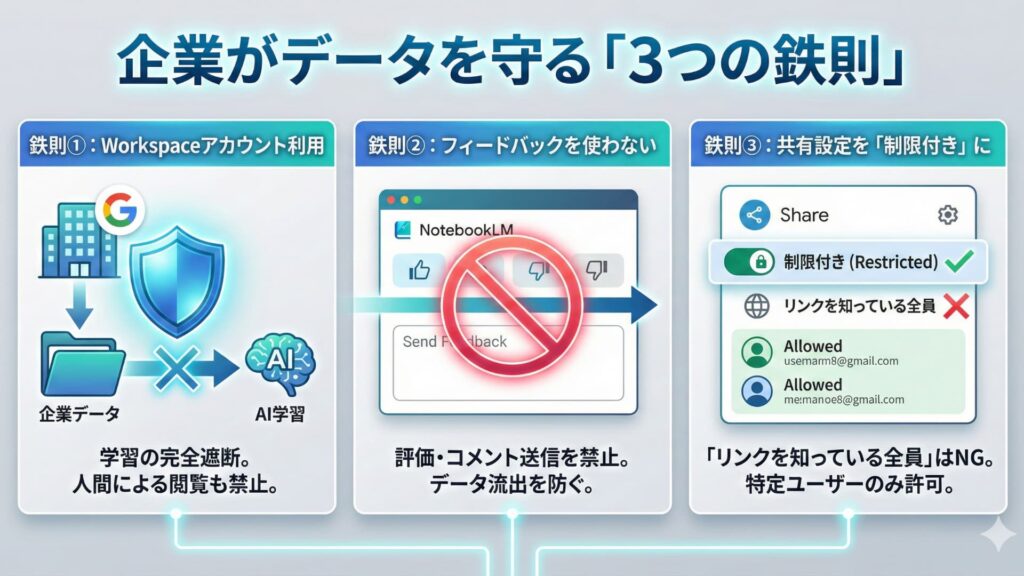
機密情報を扱う企業にとって、わずかな「例外」も許容できません。データをAIの学習から確実に守り、安全にNotebookLMを利用するための鉄則は以下の3点です。
鉄則①:Google Workspace(企業・教育用)アカウントを利用する
これが最も確実で強力な対策です。Google Workspace(Business、Enterprise、Educationなど)のアカウントでログインしてNotebookLMを使用する場合、以下の強力な保護が適用されます。
-
学習の完全遮断: アップロードしたデータや対話内容がAIモデルのトレーニングに使用されることは一切ありません。
-
人間による閲覧の禁止: Googleのスタッフがあなたのデータを閲覧することも禁止されています。
企業で利用する場合は、必ず個人のアカウントではなく、組織の管理下にあるWorkspaceアカウントを使用しましょう。
鉄則②:フィードバック機能を絶対に使わない
アカウントの種類に関わらず、機密データを扱っているノートブックでは、AIの回答に対する評価やコメント送信を一切行わないでください。「送信」ボタンを押した瞬間、そのデータは改善のためにGoogle側へ送られる可能性があります。
鉄則③:共有設定を「制限付き」に固定する
これはAIの学習とは別のリスクですが、人為的な情報漏洩を防ぐために重要です。ノートブックの共有設定で「リンクを知っている全員」に公開する設定は絶対に使用してはいけません。必要な場合は、信頼できる特定のメールアドレスだけにアクセス権を付与してください。
5. 【ケーススタディ】このデータはどのアカウントで扱うべき?
実際にどのようなデータをどのアカウントで扱うべきか、具体的なケーススタディを見てみましょう。迷った場合は、「流出したら困るデータは、必ずWorkspaceアカウントで扱い、フィードバックは送らない」と覚えておけば間違いありません。
| データの種類・具体例 | 推奨アカウントと運用 | 理由 |
|
Webで既に公開されている情報 (自社のプレスリリース、公開された決算短信、ニュース記事など) |
個人アカウントOK | 既に誰でも閲覧できる情報であり、機密性がないため。ただし、著作権には注意。 |
|
社内の一般的な業務マニュアル (経費精算の手順、ツールの使い方など) |
Workspace推奨 (個人も可だが注意) |
極秘情報ではないが、社外に出すべきではない情報が含まれる可能性があるため、組織のアカウントが望ましい。 |
|
機密性の高い社内情報 (未発表の新製品情報、顧客リスト、人事情報、取締役会議事録など) |
絶対にWorkspace +フィードバック禁止 |
万が一にも外部(Google側を含む)に見られてはならない情報。最強のセキュリティ設定が必須。 |

まとめ
NotebookLMは、RAGという技術を用いることで、原則として入力データをAIの学習には利用しない安全な設計になっています。
しかし、企業が機密情報を扱う場合は、「原則」に頼るのではなく、「Google Workspaceアカウントの利用」と「フィードバック送信の禁止」を徹底することで、学習リスクを確実に排除する運用が求められます。正しい知識と適切な設定で、AIの利便性を安全に享受しましょう。



