
【検証】V-JEPA 2は製造・物流を変えるか?世界モデルAIがもたらす「物理的自動化」の現在地
 AIエージェントナビ編集部
AIエージェントナビ編集部
ビジネスの現場において、ChatGPTをはじめとする大規模言語モデル(LLM)の導入が加速しています。しかし、どれほど高度な対話が可能なAIであっても、工場のラインや物流倉庫といった「物理的で不確実な世界」では、驚くほど無力であることに多くの経営者が気づき始めています。
本記事では、Metaが提唱する次世代AI「V-JEPA 2」が、なぜ物理世界の自動化においてゲームチェンジャーとなり得るのか、従来の生成AIとの決定的な違いと、ビジネス現場での活用シナリオを解説します。
目次
V-JEPA 2とは?物理法則を「学習」する世界モデルAIの核心
V-JEPA 2は、単なる文章作成や画像生成のためのAIではありません。現実世界の物理的な挙動を自ら学習し、次の瞬間何が起こるかを予測する「世界モデル」として設計されています。
従来の生成AIと何が違うのか?「描画」ではなく「理解」の仕組み
生成AI(ChatGPTやSoraなど)は、学習したデータをもとに「確率的に最もらしい出力」を生成することに長けています。一方で、V-JEPA 2の核心であるJEPA(Joint-Embedding Predictive Architecture:自己教師あり学習の予測アーキテクチャ)は、物理的な因果関係を抽象的な概念として捉えます。
例えるなら、生成AIが「映画の脚本を完璧に書く作家」だとしたら、V-JEPA 2は「重力や摩擦を理解し、コップが落ちた時にどう割れるかを正確に予測できる物理学者」です。表面的な画風を再現するのではなく、背景にある「物理的なルール」を理解しようとします。
なぜMetaが開発したのか?Yann LeCun氏が目指す「物理世界の自動化」
MetaのAI研究トップであるYann LeCun(ヤン・ルカン)氏が提唱するように、AIが人間に近い知能を持つためには、膨大なテキストデータよりも「物理世界での経験」が不可欠です。V-JEPA 2は、動画データから重力、慣性、衝突といった物理法則を自己学習します。これにより、AIが「PCの中の知識人」から「物理空間を理解するパートナー」へと進化することを目指しています。
なぜChatGPTでは物理現場を制御できないのか?3つの決定的な限界
テキストベースのAIは優秀ですが、現実の現場業務を任せるには、致命的な「盲点」が存在します。
物理的因果の欠如:重力や摩擦を「計算」で理解できない
LLMは「重力がある」という文章は知っていますが、目の前で運搬中の荷物が少し傾いたとき、次にどの方向に、どれくらいの速度で落下するかをリアルタイムに計算することはできません。言葉による論理推論と、物理的な空間認識は全く別の能力だからです。
動画生成AIとの混同を解く:映像を作ることと、物理を予測することの違い
現在話題の「動画生成AI」と、V-JEPA 2のような「世界モデルAI」には明確な役割の違いがあります。以下の比較表をご覧ください。
| 特徴 | 動画生成AI (Sora等) | 世界モデルAI (V-JEPA 2) |
|---|---|---|
| 主な目的 | 視覚的な美しさと一貫性 | 物理的因果の解釈と予測 |
| 得意なこと | クリエイティブな映像作成 | 異常の予兆検知・挙動予測 |
| 物理への態度 | 見た目上の整合性(誤魔化し可) | 物理法則への準拠(厳密な評価) |
| ビジネス用途 | マーケティング・広告 | 監視・安全管理・ロボット制御 |
V-JEPA 2は、あくまで「物理世界で次に何が起きるか」を予測するシミュレーターとしての性格が強く、美しい動画を作ることが目的ではないのです。
関連記事:【生成速度が最大10倍】「Nano Banana 2」徹底解説|“高速性と“高品質"を両立した次世代画像生成AI
ビジネス現場をどう変える?V-JEPA 2の実践的活用シナリオ
V-JEPA 2が現場に導入されたとき、どのような変革が起きるのでしょうか。
工場の監視カメラに「物理的予兆検知」を組み込む
「もし、あなたの工場の監視カメラにV-JEPA 2が統合されたら?」
これまでのように事故が起きてからアラートを鳴らすのではなく、ロボットアームの微細な振動や、ベルトコンベア上の荷物のバランスの崩れをV-JEPA 2が「物理的に不自然な挙動」として検知します。事故が起こる数秒前に、人間が介入する余地を作れるようになるのです。
次世代ロボット制御:複雑な環境下での動作最適化
未知の物体を扱う物流ロボットにとって、最大の敵は「想定外」です。V-JEPA 2を搭載したロボットは、対象物の形状や重さを映像から直感的に「予測」し、掴む際の力加減や角度を自律的に微調整できます。これにより、これまで熟練工の勘に頼っていた微細な作業の自動化が可能になります。
実装の現在地と今後のロードマップ:経営層が押さえるべきマイルストーン
技術は非常に有望ですが、導入にあたっては冷静な視点が必要です。
今は「環境認識」の段階:過度な期待をせず検証から始める
現在は「物理環境を正確に解釈・シミュレーションする」という基礎研究のフェーズです。汎用ロボットに即座に組み込んで「全自動で何でもできる」状態ではありません。まずは、現場の映像データをV-JEPA 2に学習させ、「異常検知の精度」を検証する段階から開始するのが現実的です。
自社データ×V-JEPA 2:現場の熟練工の勘をモデル化する
V-JEPA 2の強みは、特定の環境に特化させる「ファインチューニング(微調整)」が可能な点です。現場で長年培われてきた「熟練工が危険を察知する瞬間」の映像データをAIに学習させることで、その会社独自の「物理的な勘」をデジタル資産として保存できる可能性があります。
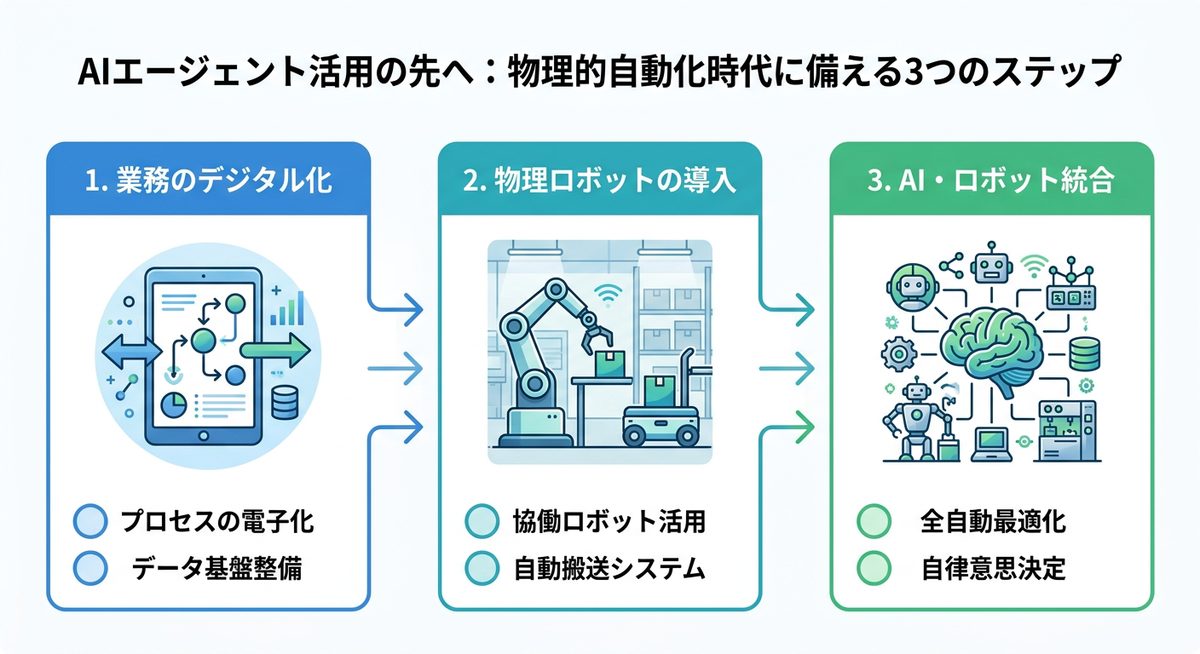
AIエージェント活用の先へ:物理的自動化時代に備える3つのステップ
物理世界を認識するAIは、AIエージェントの可能性を大きく広げます。
- 現場の「物理データ」を蓄積する: AIが理解するための教師データが必要です。定点カメラやロボットの動作ログなどの映像データを整理しましょう。
- 「世界モデル」の動向を注視する: V-JEPA 2のような物理理解型AIの進化は、AIエージェントの「物理的な目」となります。
- 継続的なトレンド把握: 物理認識能力の向上が、AIエージェントをPC内から物理世界へ解き放つ鍵となります。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
まとめ
V-JEPA 2は、ChatGPTのような「論理」の世界と、私たちが暮らす「物理」の世界を繋ぐ重要な架け橋です。本記事の要点は以下の通りです。
- 世界モデルの重要性: V-JEPA 2は、動画を通じて物理法則を自ら学ぶことで、現実世界の事象を予測・解釈する能力を持つ。
- 生成AIとの明確な違い: 「綺麗な映像を作る」ことではなく「物理的な因果関係を予測する」ことが目的であり、異常検知やロボット制御に特化した実用ツールである。
- 段階的な導入の必要性: 現時点では物理的な環境認識能力の高度化に注力し、自社の現場データを用いた検証から始めることが、将来の自動化戦略において優位に立つ。
物理世界の自動化は、これからの企業競争力を大きく左右します。この新たな波に乗り遅れないよう、最新のAIエージェントトレンドをメルマガ等で継続的にキャッチアップしていきましょう。



