
Gemma 4とは?ビジネス導入ガイド|モデル選定・環境構築の全手順
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIを自社業務に組み込みたいが、顧客の機密データを外部のクラウドAPIに送信することに懸念を感じていませんか。セキュリティを担保しながら、最新の推論能力を社内環境でフル活用したい企業にとって、Googleが提供するオープンモデル「Gemma 4」はまさに待望の選択肢です。
本記事では、Gemma 4の技術的特徴から、自社インフラに合わせた導入手順、他モデルとの性能比較までを詳しく解説します。
この記事に対する編集部の見解
- 一般的な支給PCの内蔵グラフィックスでは実用不可・専用GPUサーバーが業務利用の前提
- 7Bモデルで8〜12GB・31Bモデルで24〜48GBのVRAMが必要なため業務利用はサーバーが前提
- まず試すならGoogle AI Studioでブラウザから無料で動作確認できる
目次
Gemma 4とは?Googleのオープンモデル
Gemma 4は、Googleの最新技術を詰め込んだ軽量かつ高性能なオープンモデルです。PCの中に非常に優秀で思慮深いアシスタントが住み着いた状態を、オフライン環境で実現できます。
MTP技術による推論速度と精度の向上
Gemma 4最大の特徴は、「MTP(Multi-Token Prediction:マルチトークン予測)」技術の採用です。従来のAIが1文字ずつ予測していたのに対し、MTPでは数ステップ先まで同時に予測します。これにより、思考速度が格段に向上し、複雑なビジネス文書の作成や推論においてもミスが劇的に減りました。
ビジネス現場で選ばれる自社資産化の利点
クラウド型のAIサービスは便利ですが、社外にデータを出す必要があります。Gemma 4はモデルそのものを自社サーバーやPC内にダウンロードして動かせるため、外部へ情報が漏洩するリスクをゼロにできます。AIそのものが貴社の「技術資産」として社内に蓄積され、永続的に利用できる点が最大のメリットです。
関連記事:AIエージェントとは?概念から実装フェーズへ移行した2026年
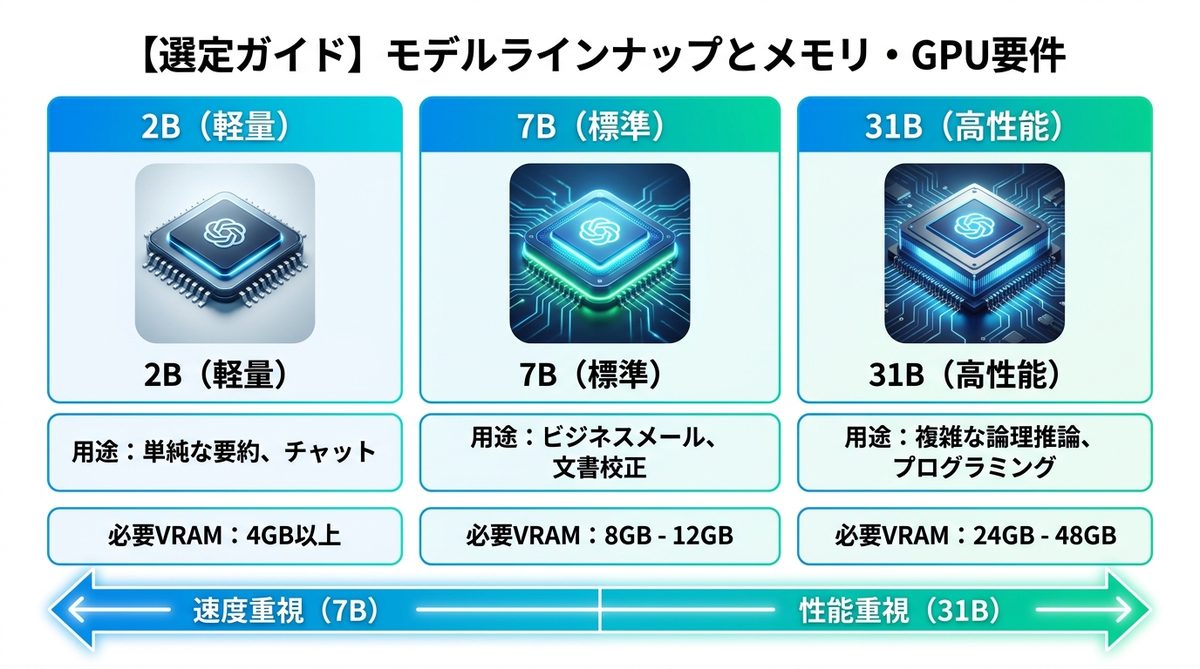
モデルラインナップとメモリ・GPU要件
Gemma 4を導入する際、ハードウェア性能に合わせた適切なモデル選びが成功の鍵となります。
モデル別用途と必要VRAM概算
以下の表は、各モデルを快適に動作させるために必要なビデオメモリ(VRAM)の目安です。
| モデルサイズ | 推奨用途 | 必要VRAM(メモリ) |
|---|---|---|
| 2B(軽量) | 単純な要約、チャット | 4GB以上 |
| 7B(標準) | ビジネスメール、文書校正 | 8GB - 12GB |
| 31B(高性能) | 複雑な論理推論、プログラミング | 24GB - 48GB |
ハードウェア別モデルの選び方
- 性能重視の場合:31Bモデルを選択してください。論理的な複雑さが求められる資料作成に適しています。
- 速度重視の場合:7Bモデルが最適です。一般的な事務作業やメールの返信文作成であれば、7Bモデルで十分な精度が得られます。
関連記事:【完全ガイド】Qwen 3.5の選び方・動かし方|高性能AIをローカル環境で最大限活用する方法
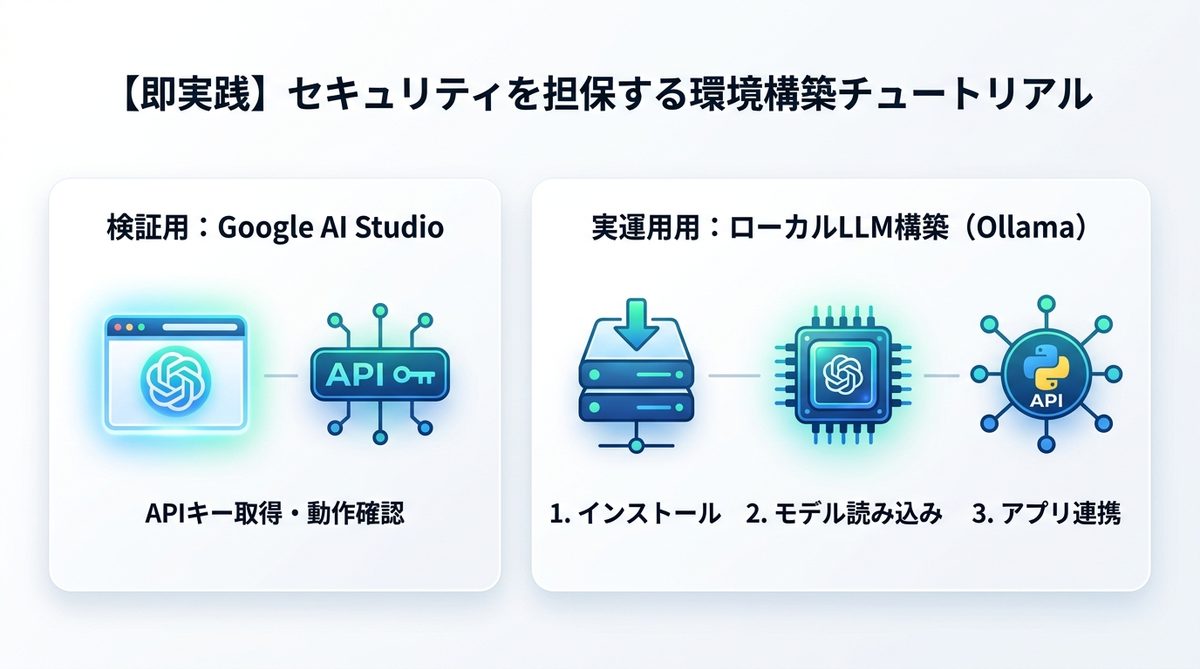
セキュリティを担保する環境構築
実際に手を動かしながら、自社環境でGemma 4を動かすための2つのステップを紹介します。
Google AI Studioでの動作確認
まずは「Google AI Studio」にブラウザでアクセスし、APIキーを取得してGemma 4を試してください。ここではコードを書く必要がなく、プロンプトへの応答速度や精度を直感的に確認できます。
Ollama/vLLMによる構築手順
自社サーバーで運用する際は、「Ollama(オープンソースの実行環境)」を利用するのが最も効率的です。
- インストール:Ollamaの公式サイトから環境に合ったインストーラーをダウンロードします。
- モデル読み込み:コマンドラインで「ollama run gemma4:7b」と入力するだけで、モデルが自動的にダウンロードされ実行環境が整います。
- 連携:PythonなどのアプリケーションからローカルAPIを呼び出すことで、セキュアなAI環境が完成します。
関連記事:【Foundry Localとは】Microsoftが描く「ローカルAIエージェント」の未来。
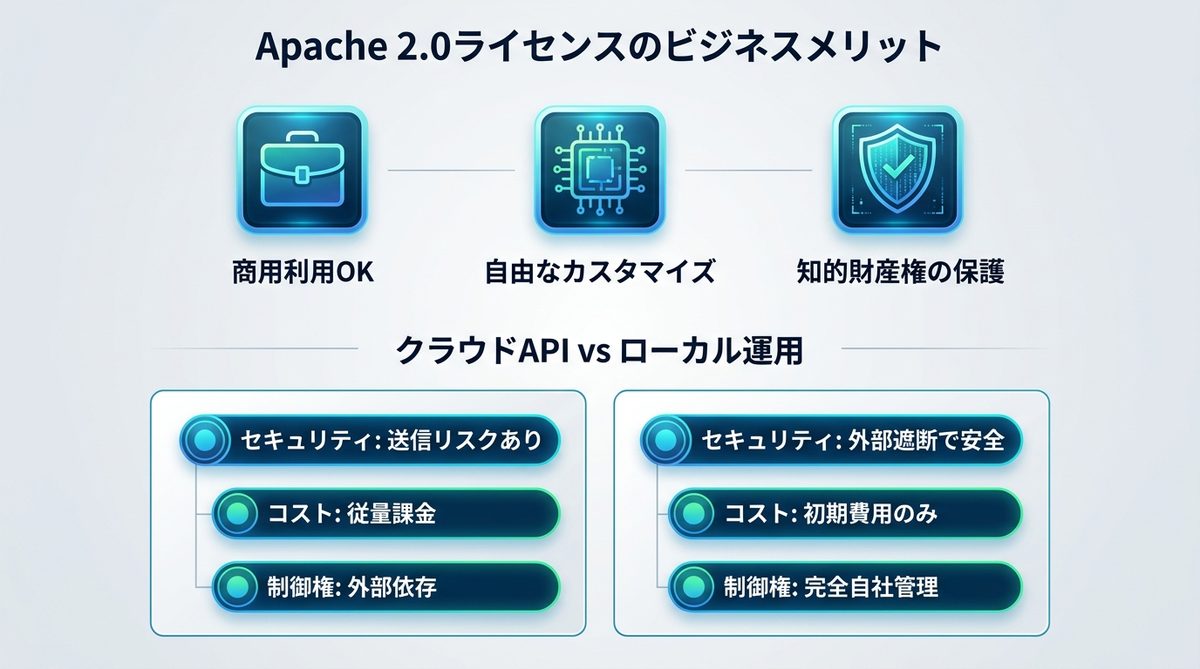
Apache 2.0ライセンスのメリット
Gemma 4は「Apache 2.0ライセンス」を採用しています。これはビジネスにおいて非常に強力なライセンス形態です。
知的財産を守る社内AIカスタマイズ
このライセンスは、モデルの改変や商用利用が認められており、貴社独自のカスタマイズを行っても権利関係が複雑になりません。自社専用のプロンプトやデータを学習させる「ファインチューニング(追加学習)」を自由に行えます。
APIとローカル運用のコスト比較
| 比較軸 | クラウドAPI(Gemini) | ローカル運用(Gemma 4) |
|---|---|---|
| セキュリティ | 送信時リスクあり | 外部遮断で最高レベル |
| コスト | 従量課金制 | ハードウェア初期費用のみ |
| 制御権 | Googleに依存 | 完全な自社管理 |
関連記事:源内(GENAI)とは?ベンダーロックインを回避するAI内製化の道
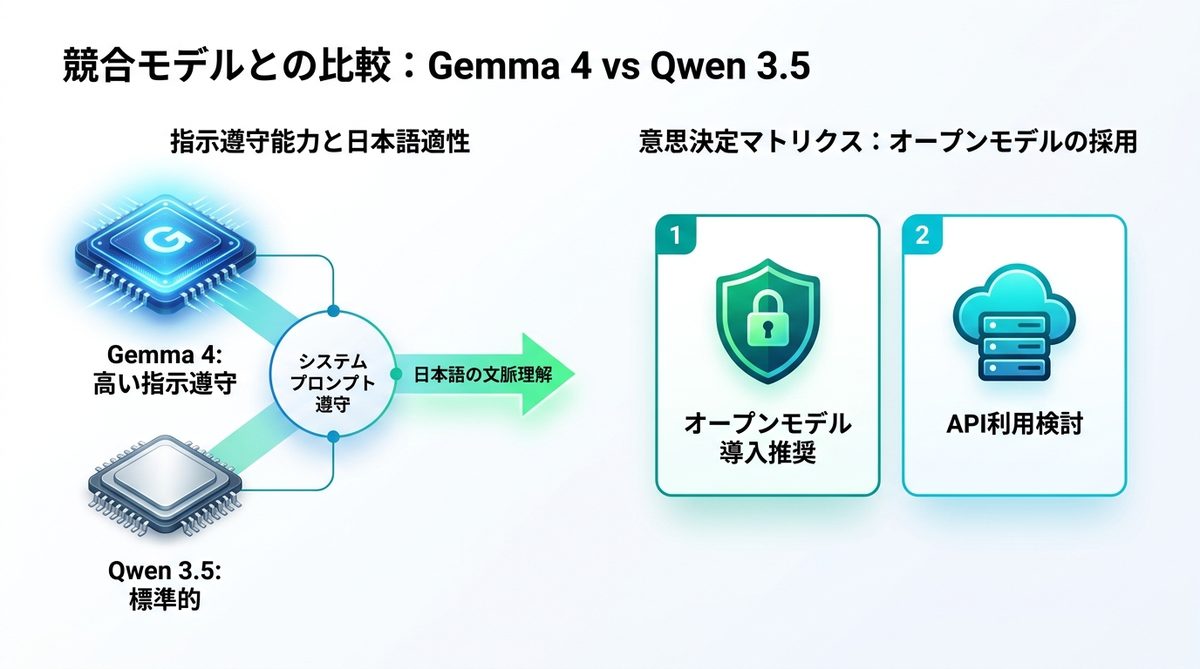
競合比較:Qwen 3.5を上回る性能
他社製モデルと比較した場合、Gemma 4は「指示への忠実さ」で抜きん出ています。
プロンプト理解と文書生成精度の比較
システムプロンプト(AIに振る舞いを指示する命令)に対する遵守性能が非常に高く、例えば「役員向けの簡潔な報告書として出力せよ」といった細かい指示を高い精度で守ります。特に日本語の文脈理解において、Qwen 3.5よりも丁寧な表現が可能です。
オープンモデル採用の判断基準
- 導入推奨:顧客の個人情報や社内規程を扱う業務、またはネットワーク制限がある環境。
- API検討:常に最新モデルを試したい、自社サーバー構築のコストを抑えたい場合。
関連記事:【2026年最新】RAGとは?生成AIをビジネスで安全に活用するための導入ロードマップ
まとめ
Gemma 4は、セキュリティと性能を両立させたいビジネスパーソンにとって、現時点で最も現実的な選択肢の一つです。
- MTPによる超高速推論:思考の速さと正確さが、業務効率を最大化します。
- ローカル環境構築:Ollamaを使えば、数分で自分だけのAI環境が構築可能です。
- Apache 2.0の安心感:法的リスクを抑えながら、自社専用AIへとカスタマイズが可能です。
- コストの固定化:一度環境を作れば、API費用を気にせず使い放題となります。
まずは、現在の社内PCでOllamaをインストールし、小さな業務からPoC(概念実証)を始めてみてください。あなたの会社に「最強のアシスタント」を迎え入れる準備は整っています。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- 一般的な支給PCの内蔵グラフィックスでは実用不可・専用GPUサーバーが業務利用の前提
- 7Bモデルで8〜12GB・31Bモデルで24〜48GBのVRAMが必要なため業務利用はサーバーが前提
- まず試すならGoogle AI Studioでブラウザから無料で動作確認できる
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


