
AIエージェント開発のGPU・PCスペック選定
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの自律的な動作を支えるには、単なるGPUの性能以上にシステム全体のリソース設計が不可欠です。本記事では、モデル規模ごとの推奨スペックから、ローカル環境とクラウド利用の判断基準まで、2026年最新の視点で解説します。
この記事に対する編集部の見解
- AIエージェントはGPUだけでなくメモリ32GB以上・高速SSDも要件、PC全体のスペックが鍵
- PC価格相場はエントリー20〜25万・ミドル35〜60万・ハイエンド100〜150万円
- 月1万リクエスト超でクラウドは割高、機密データや24時間稼働ならローカル一択
目次
AIエージェント時代、GPU選びの前提
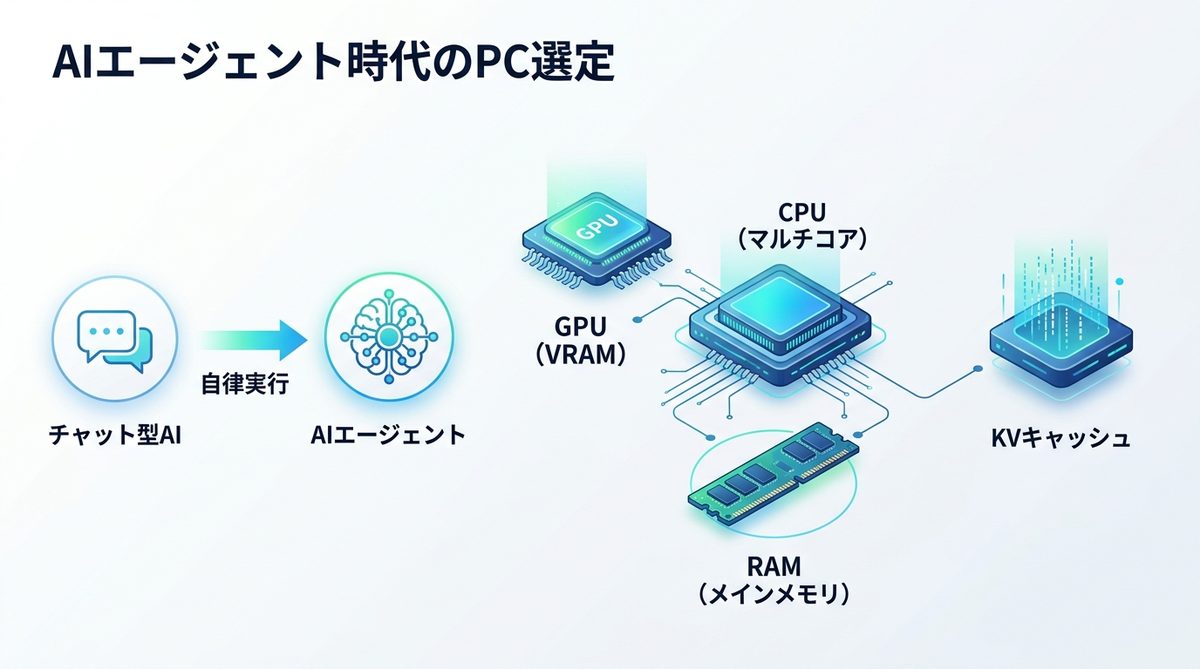
PCの中に優秀なアシスタントを住まわせるようなAIエージェント開発において、ハードウェア選定はプロジェクトの成否を分ける重要事項です。
リソースの変化
従来の「チャット型AI」は、一度の推論が完了すればタスクは終了でした。しかし、AIエージェントはツール使用、Webブラウジング、思考プロセス、エラー再試行といった「継続的な自律実行」を行います。これに伴い、GPUの演算能力だけでなく、オーケストレーション(実行管理)を支えるシステム全体のリソースが重要になっています。
PC全体のボトルネック
多くの開発者が陥る罠が「GPUのVRAM(ビデオメモリ)さえあれば良い」という考え方です。AIエージェントが複数のエージェントと連携したり、複雑なタスクをこなしたりする場合、CPUのマルチコア性能と、広大なメインメモリ(RAM)が必須となります。特にエージェントが過去の文脈を保持するためのKVキャッシュ(キー・バリュー・キャッシュ:推論過程で生成される一時記憶データ)は、システムメモリを急速に消費します。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
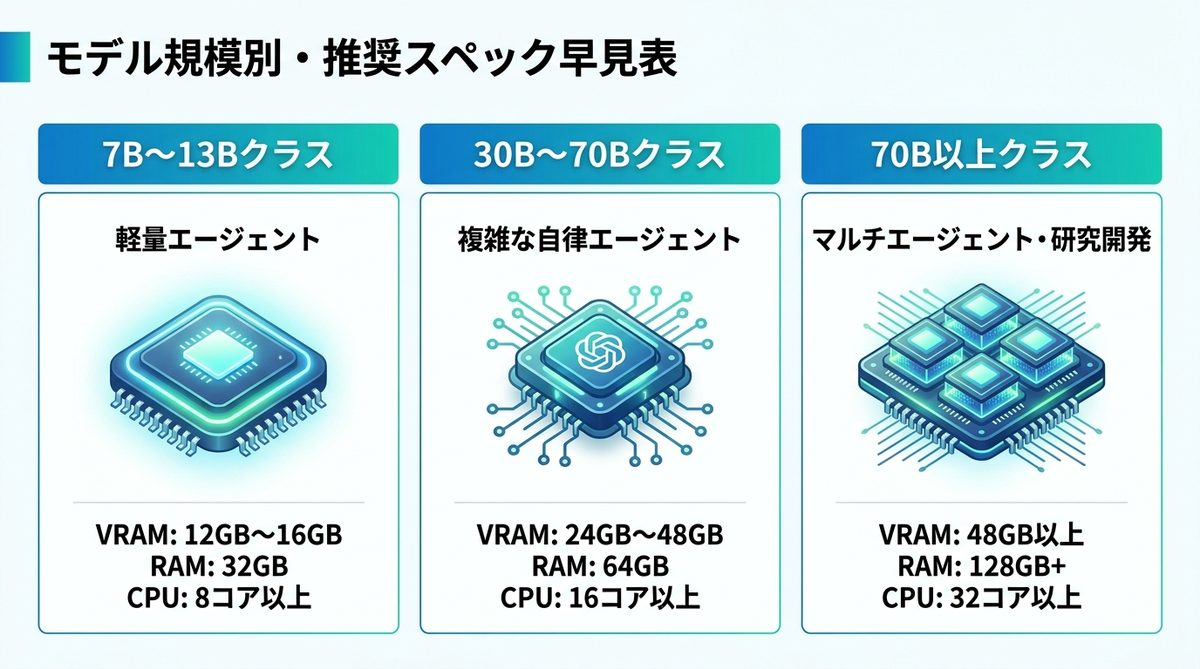
モデル規模別・推奨スペック(7B〜70B以上)
開発するエージェントが扱うモデル規模によって、必要なリソースは大きく異なります。以下の表を基準に構築を検討してください。
| モデル規模 | 推奨VRAM | 推奨RAM | 推奨CPU | 用途 |
|---|---|---|---|---|
| 7B~13B | 12GB〜16GB | 32GB | 8コア以上 | 軽量エージェント、単一タスク |
| 30B~70B | 24GB〜48GB | 64GB | 16コア以上 | 複雑な自律エージェント |
| 70B以上 | 48GB以上 | 128GB+ | 32コア以上 | マルチエージェント・研究開発 |
7B〜13Bの運用基準
個人や小規模チームがタスクを自動化する場合の基本構成です。12GB〜16GBのVRAMがあれば、最新の量子化(モデルの圧縮技術)モデルを高速に動作させることが可能です。
70B以上の環境構築
大規模モデルをローカルで動かす場合、VRAM不足は致命的です。RTX 5090などのハイエンドGPUを複数枚搭載するか、後述するユニファイドメモリ環境が必須となります。
RAMの推奨容量
エージェントが長時間のタスクを実行すると、KVキャッシュの肥大化でシステムメモリが枯渇します。最低でも32GB、可能であれば64GB以上を確保することで、長時間稼働でも安定した推論速度を維持できます。
関連記事:【2026年最新】ローカルAIエージェントの作り方|Ollama×Open WebUIで完全オフライン構築
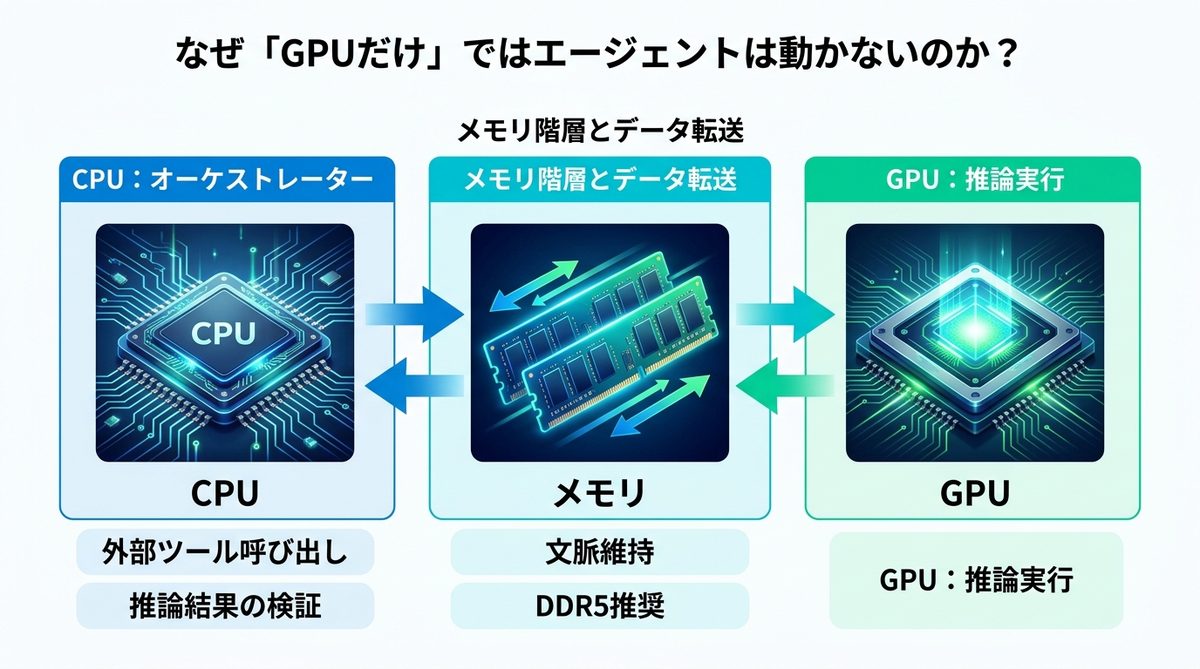
なぜGPUだけでは動かないのか
AIエージェントの裏側では、目に見えないところで膨大な処理が走っています。
CPUの役割
エージェントは外部ツール(検索APIやファイル操作)の呼び出し、推論結果の検証、無限ループの監視を行っています。これらはCPUの「オーケストレーション(実行管理)」負荷となります。CPU性能が低いと、AIが次の思考を開始するまでの待機時間が長くなり、開発体験が著しく低下します。
メモリ階層と転送速度
推論モデルはGPUメモリ上に展開されますが、エージェントの「記憶」や「タスクリスト」はシステムメモリ上にあります。これらが行き来する際のデータ転送速度が遅いと、エージェントは「動作が重い」状態になります。最新のDDR5メモリの導入を推奨します。
関連記事:【モデル規模別】AIエージェント開発に必要なPCスペック
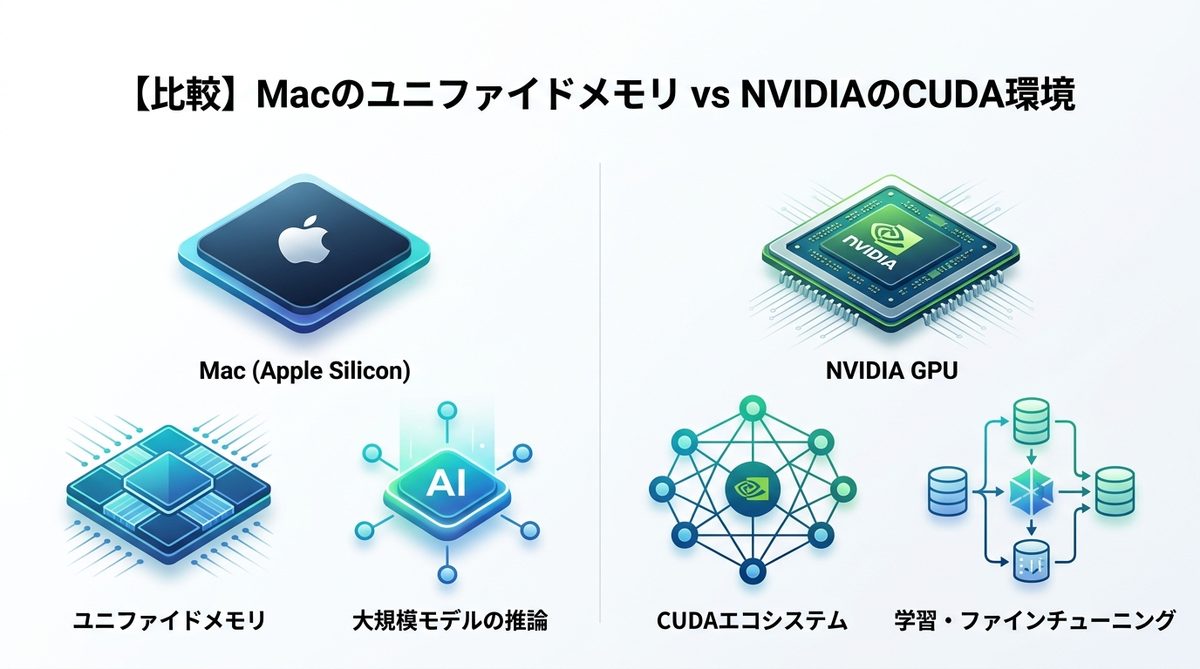
Macのユニファイドメモリ vs NVIDIA
開発目的によって、選ぶべきプラットフォームが明確に異なります。
Macの利点
Apple Silicon搭載Macは、CPUとGPUがメモリを共有する「ユニファイドメモリ」構造です。これにより、最大192GBといった大容量メモリをそのまま推論に利用できます。超大規模モデルをローカルで試したいエンジニアにとって、最高の開発環境です。
NVIDIAのCUDA環境
一方で、モデルの学習やファインチューニング(微調整)を行うならNVIDIA一択です。機械学習の標準ライブラリであるCUDA(クダ:NVIDIA専用の計算環境)のエコシステムは圧倒的で、開発効率と互換性が段違いです。
目的別の選定基準
- 快適な開発と大規模モデル推論なら:Mac(Apple Silicon)
- 高度な学習・ファインチューニングなら:NVIDIA GPU(Windows/Linux)
関連記事:【実践ガイド】AIエージェント最適化のためのファインチューニング手法
ローカル vs クラウド:判断とコスト
全てをローカルに置くことが正解とは限りません。
自前とAPIの境界線
ローカル環境は初期投資がかかりますが、一度構築すれば推論コストは電気代のみです。一方、クラウド(API利用)は、従量課金制のため規模が大きくなると高額になる傾向があります。
- ローカル構築向き:機密情報を扱う場合、24時間常時稼働させる場合、実験回数が多い場合
- API利用向き:ピーク時のみ稼働する場合、モデルを頻繁に切り替える場合、開発期間が限定的な場合
リスク回避のチェックリスト
自律エージェントは無限ループに陥り、APIコストを浪費するリスクがあります。ローカル環境なら電気代以外の追加コストは発生しませんが、クラウドなら予算上限設定が必須です。
関連記事:【2026年最新】Claude Codeを無料で使う全手順|API予算設定でリスクをゼロにする方法
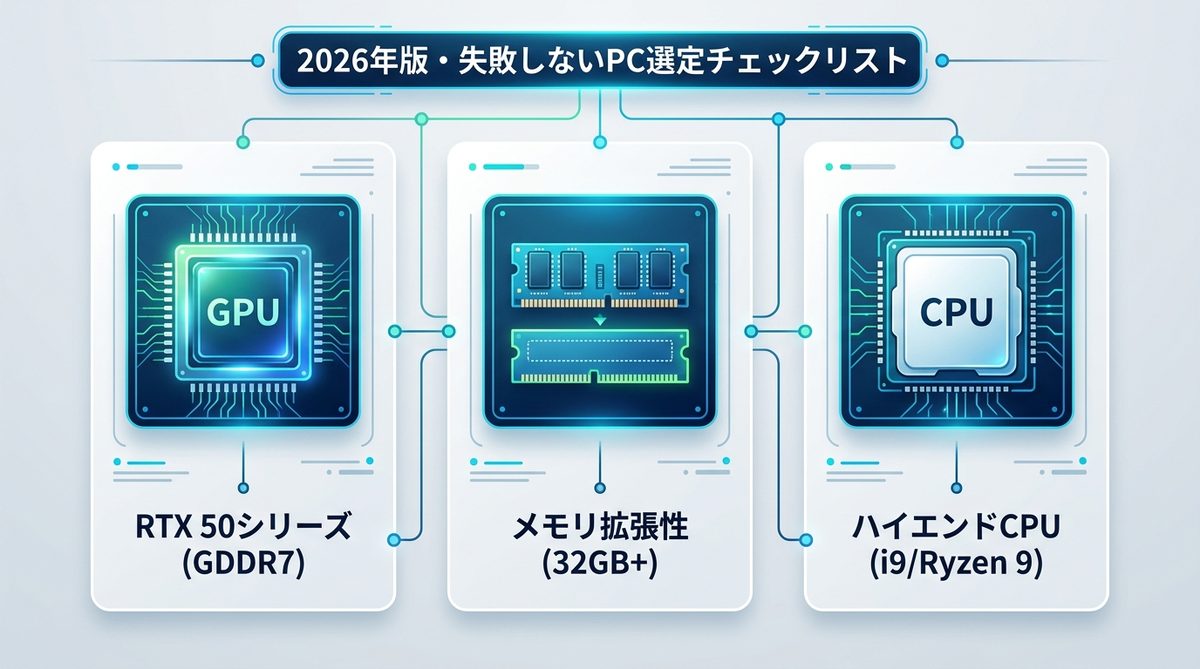
2026年版・PC選定チェックリスト
2026年現在、AI開発において選ぶべきハードウェアのポイントを3つに絞りました。
- GPUはGDDR7対応のRTX 50シリーズを狙う
RTX 50シリーズが採用するGDDR7メモリは、推論速度を大幅に向上させます。エージェントのレスポンス向上に直結します。 - メモリは将来を見越して拡張性を確保する
現時点で32GBであっても、将来的な大規模化を想定して空きスロットがある構成を選びましょう。 - CPUは多コア・高クロックを優先する
Intel Core i9やAMD Ryzen 9といったハイエンドクラスのCPUが、エージェントの思考速度を担保します。
関連記事:【2026年最新】Claude Codeの始め方|開発を自動化する初期設定と運用Tips
まとめ:最適な構成
AIエージェント開発を成功させるには、プロジェクト規模に応じた適切なハードウェア選定が不可欠です。最後に要点をまとめます。
- 7Bクラスなら: RTX 5060以上のGPUと32GBメモリで十分。
- 大規模モデル開発なら: 128GBのRAMとCUDA環境(NVIDIA)を構築する。
- 推論メイン・快適さ優先なら: 大容量ユニファイドメモリを備えたMacを導入する。
- コスト判断: 24時間稼働の自律エージェントならローカル構築が経済的だが、開発開始時はAPIで先行検証する。
まずは現在想定しているエージェントが「どのモデルサイズで動作するか」を特定し、最適な環境を整えて開発を始めましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- AIエージェントはGPUだけでなくメモリ32GB以上・高速SSDも要件、PC全体のスペックが鍵
- PC価格相場はエントリー20〜25万・ミドル35〜60万・ハイエンド100〜150万円
- 月1万リクエスト超でクラウドは割高、機密データや24時間稼働ならローカル一択
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


