
【AI責任者必見】Nemotron 3 Superを選ぶべきケースとは?エージェントAI構築のコスト最適化戦略
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの構築において、すべての判断を万能モデル(汎用LLM)に任せると、運用コストの高騰と応答速度の低下という「2つの壁」に直面します。本記事では、2026年3月にリリースされた「Nemotron 3 Super」を軸に、既存モデルと比較しながら、自社のAIエージェント環境を最適化し、スケーラブルな運用を実現するための判断基準を解説します。
目次
なぜAIエージェントは「万能モデルだけ」では上手くいかないのか
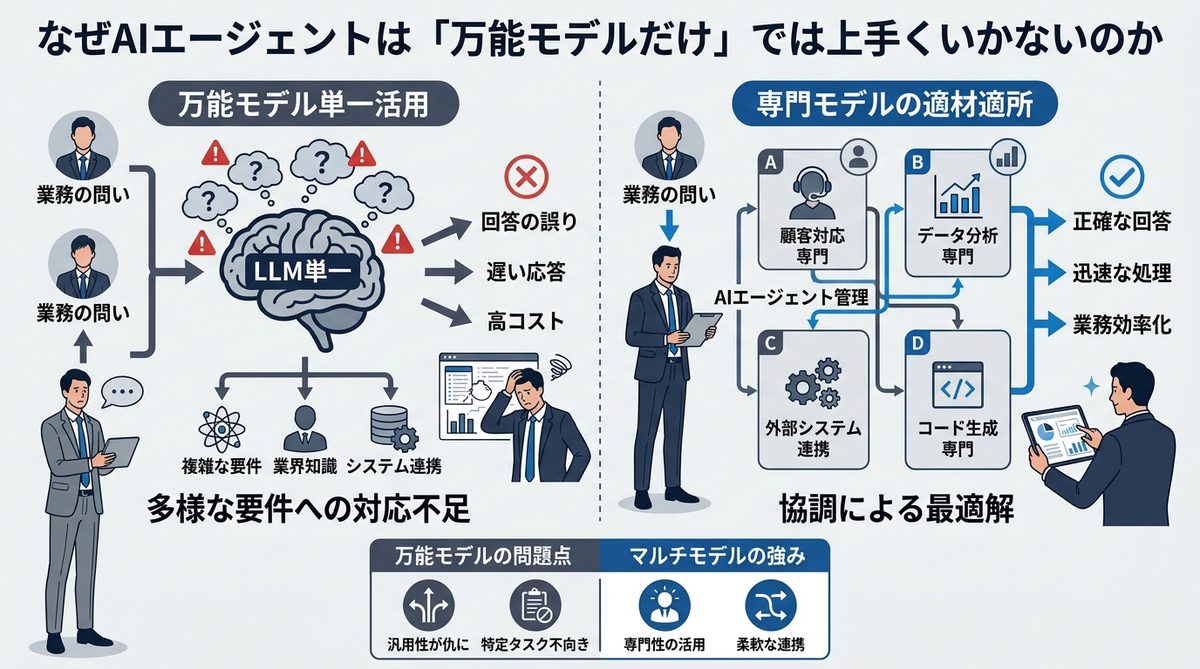
多くの企業が、GPT-4oやClaude 3.5といった万能モデルをエージェントの中核に据えていますが、この戦略には限界が近づいています。
推論コストと応答速度が招く「エージェントの限界」とは
万能モデルは「賢さ」という点で優れていますが、その分、1トークンあたりの処理コストが極めて高額です。特にAIエージェントが自律的に推論を繰り返す場合、バックグラウンドで数万トークンが消費されるのは日常茶飯事であり、これが経営層を悩ませる「予期せぬクラウド利用料」に直結します。また、パラメータ数の多いモデルは「考える時間」も長く、エンドユーザーに対する応答速度の遅延がUX(ユーザー体験)を大きく損なう要因となります。
マルチステップ・タスクで発生する「通信オーバーヘッド」の正体
AIエージェントが複雑な業務をこなす際、モデルは「思考→ツール検索→出力」という工程を何度も繰り返します。これは例えるなら、「熟練の専門家が、いちいち本社に戻って指示を仰いでいる状態」です。処理の複雑化に伴い、この通信と待機時間が積み重なり、まるで重たいファイルを転送しているかのようにエージェント全体の動きが鈍化してしまうのです。
関連記事:【2026年版・診断チャート付】目的別AIエージェントおすすめ10選|課題解決のための選び方と導入ステップを完全網羅
Nemotron 3 Superの登場:エージェントAIの常識を覆す技術力
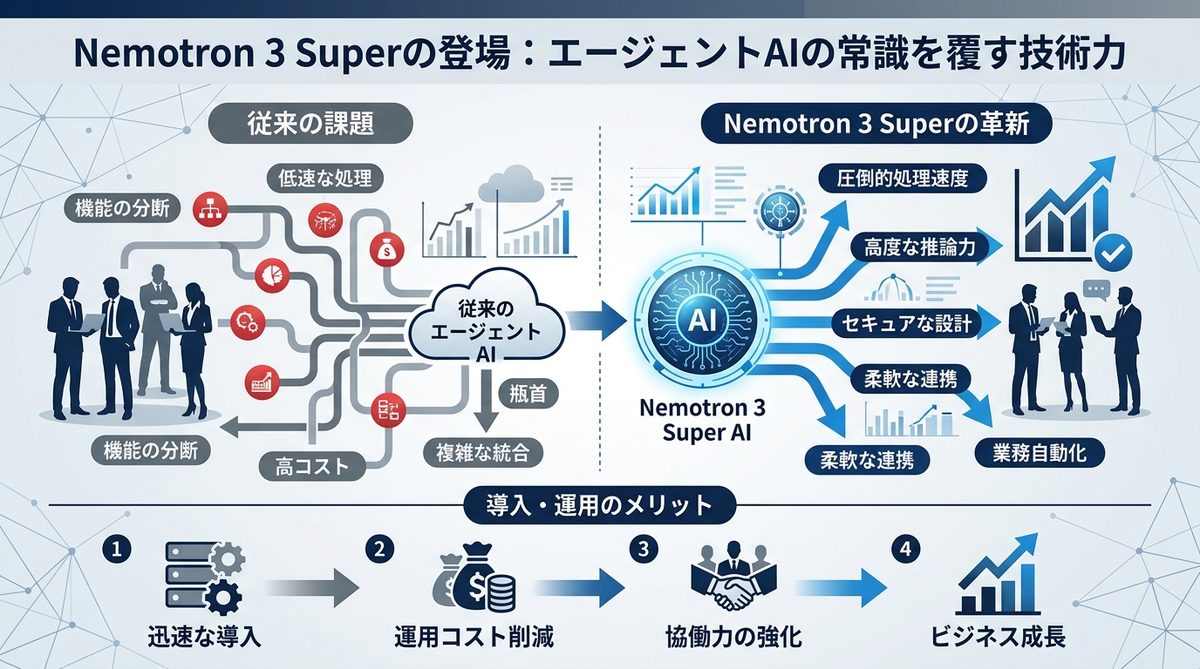
NVIDIAが提供を開始した「Nemotron 3 Super」は、AIエージェント特化型のオープンウェイトモデルとして、コスト効率と処理速度の最適解を提示しました。
Nemotron 3 Superが「エージェント特化」と呼ばれる理由
本モデルは、単なる知識量ではなく「実行力」に重きを置いて設計されています。120B(1200億パラメータ)のモデルでありながら、推論の精度と速度のバランスを極限までチューニングしており、エージェントが自律的にタスクを完遂するための文脈理解能力に特化しています。
なぜ前世代比「5倍のスループット」を実現できたのか
Nemotron 3 Superは、Latent MoE(潜在的な混合専門家モデル)とMTP(Multi-Token Prediction:複数トークン同時予測)を統合することで、劇的な高速化を達成しました。
- Latent MoE: 必要な知識だけを瞬時に呼び出すことで、処理負荷を大幅に削減。
- MTP: 次の1語だけでなく、先の展開を予測して文章を生成することで、計算効率を向上。
これにより、前世代モデルと比較して5倍のスループット(処理効率)と2倍の精度を実現。これは、今までエージェントが数分かかっていたデータ分析を、数秒で完了させる可能性を秘めています。
100万トークンのコンテキストが実現する「途切れない思考」
100万トークンという巨大なコンテキストウィンドウ(記憶容量)により、プロジェクトの全仕様書や過去のチャット履歴を丸ごと読み込ませた状態での運用が可能です。これはエージェントが途中で内容を忘れ、再学習や再プロンプトを必要としない「長期的な自律ワークフロー」を実現するために不可欠な機能です。
関連記事:【図解で解説】Claude Codeとは?Claude Coworkとの違いと活用事例
【徹底比較】万能モデル vs Nemotron 3 Superの判断基準
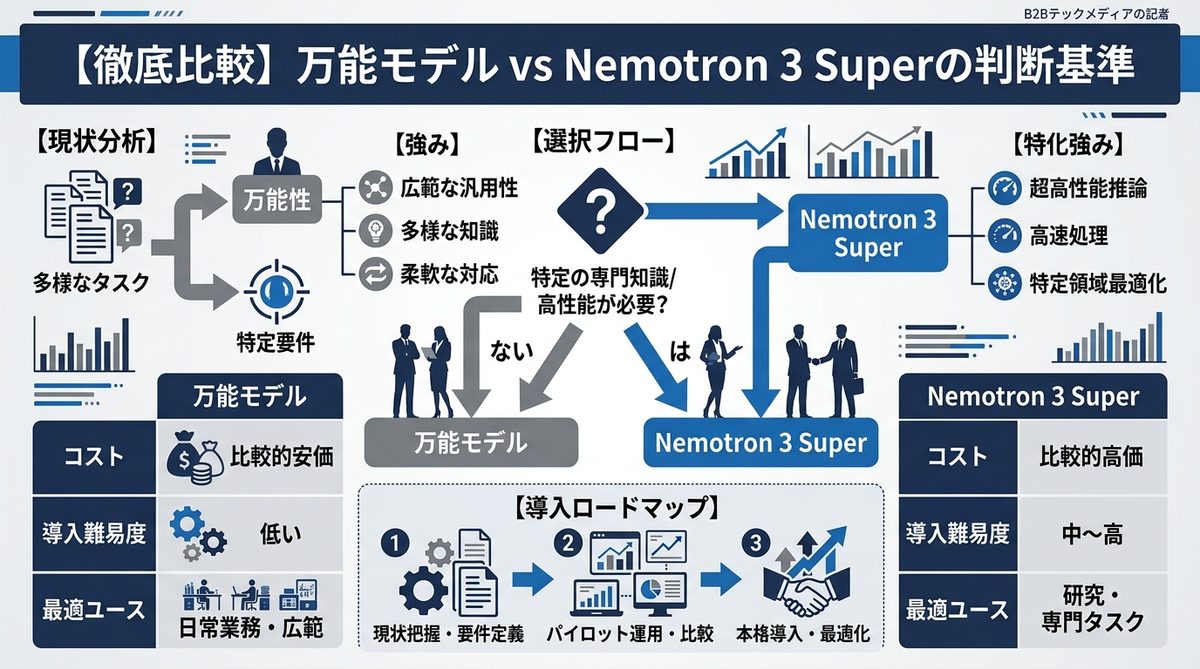
万能モデルとNemotron 3 Superは、適材適所で使い分けるのが正解です。
精度とコストのバランス:どちらを優先すべきか
| 比較項目 | 万能モデル (GPT-4o等) | Nemotron 3 Super |
|---|---|---|
| 推論単価 | 高い | 安価(最適化可能) |
| 応答速度 | 比較的遅い | 極めて速い |
| 専門的タスク | 非常に得意 | 非常に得意 |
| 大規模ワークフロー | コスト懸念あり | 非常に効率的 |
コーディングからトリアージまで:得意領域の切り分け方
- 万能モデルを使うべき領域: 抽象的な戦略立案、高度な推論、未知の課題に対する柔軟な対応。
- Nemotron 3 Superを使うべき領域: 定型的なデータ処理、大量のドキュメントのトリアージ(仕分け)、反復的なコーディングタスク、カスタマーサポートの自動応答。
エコシステムの違い:NVIDIA NIMがもたらす「導入負荷ゼロ」のメリット
NVIDIA NIM(NVIDIA Inference Microservices)を利用することで、インフラ構築の知識がない担当者でも、コンテナ形式でモデルを即座に導入可能です。セルフホスティング(自社環境での運用)ができるため、機密情報を社外に出さずに「高速かつ安価なAI」を自社内に住み着かせることができます。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説
Blackwellで加速する「エージェントのオフロード戦略」
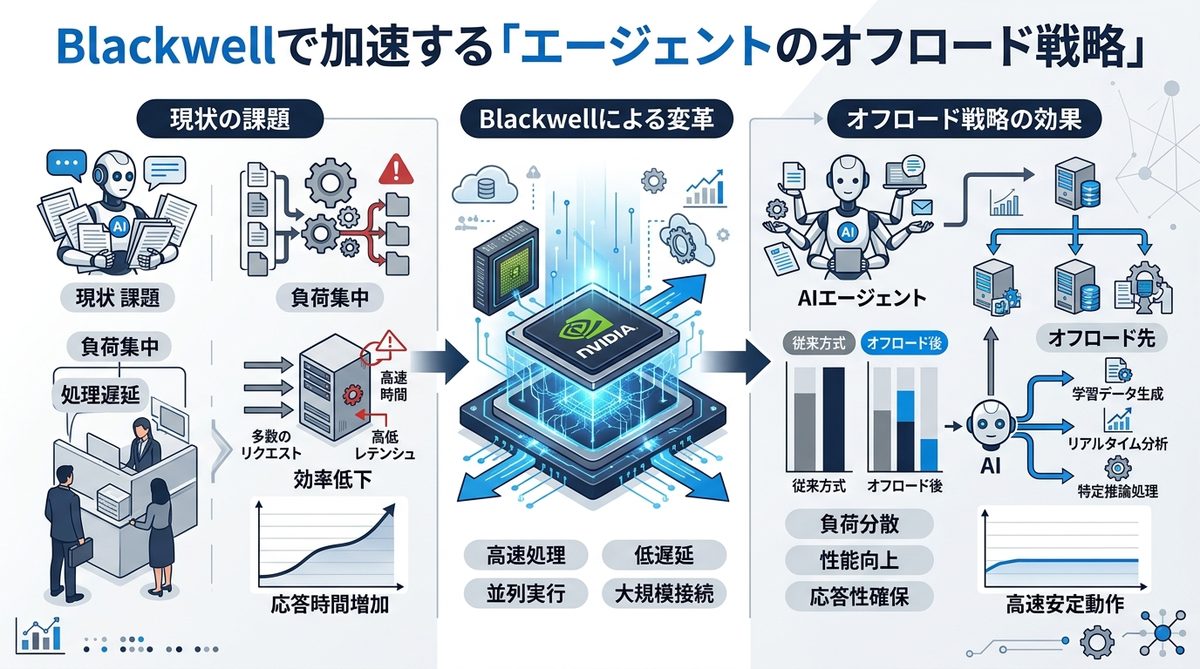
最新のAIインフラであるBlackwellアーキテクチャと組み合わせることで、パフォーマンスはさらに最大化されます。
万能モデルを「司令塔」に、Nemotron 3 Superを「実行部隊」に
これが、コスト最適化のゴールです。万能モデルに「何をすべきか」という戦略を立てさせ、実際に手を動かす「データの処理」や「コーディング」をNemotron 3 Superに割り当てる(オフロードする)ことで、全体の処理コストを大幅に抑制しながら、エージェントの実行速度を維持できます。
NVIDIAエコシステムへのネイティブ対応がもたらす「圧倒的な処理効率」
Blackwell対応のGPU環境で動かすことで、ハードウェアレベルで最適化された計算が可能です。これにより、モデルはハードウェアの性能を限界まで引き出し、これまで以上に高密度なタスク処理を低電力・低レイテンシで行えます。
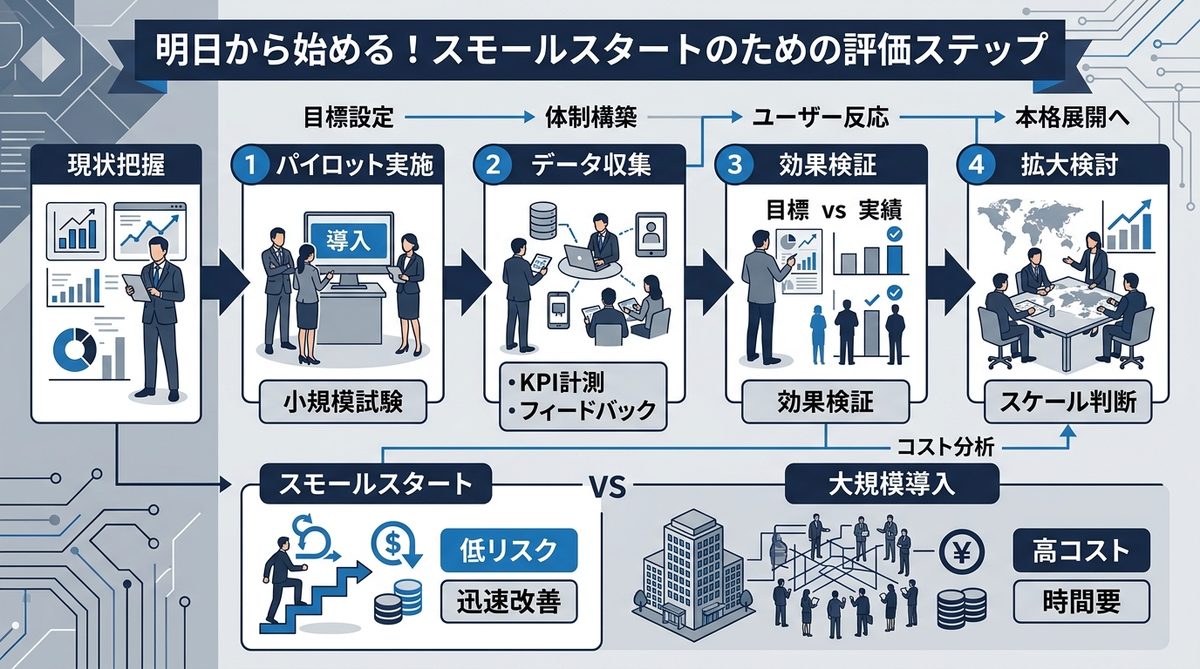
明日から始める!スモールスタートのための評価ステップ
いきなり全体を移行するのではなく、まずは一部のタスクから検証しましょう。
まずはここから:build.nvidia.comでクイックテストを行う方法
まずは build.nvidia.com にアクセスし、Nemotron 3 Superの性能を体感してください。手持ちのプロンプトを投げ、既存モデルと比較してどの程度の速度・精度で回答が出るかを検証します。
自社のエージェントで「精度」と「コスト」を検証する3つの指標
- タスク完了時間: 業務プロセス全体での短縮率は何%か。
- API推論コスト: 既存モデル比でコストを何%削減できたか。
- タスク精度(正答率): 業務上許容できるレベルに達しているか。
まとめ
Nemotron 3 Superは、AIエージェントの運用を「高コストな実験」から「効率的なビジネスインフラ」へと転換させるためのキーパーツです。
- 万能モデルの使い分け: 司令塔には万能モデル、実行部隊にはNemotron 3 Superを配置してコストを最適化する。
- 圧倒的な効率: Latent MoEとMTPにより、エージェントの処理速度を最大5倍に向上させる。
- 容易な導入: NVIDIA NIMを活用し、インフラ構築負荷を抑えてスモールスタートする。
まずはbuild.nvidia.comで自社の業務プロンプトをテストし、コスト削減の可能性を確認してみてください。今すぐAIエージェント運用の最適化を始めましょう。



