
コンテキストエンジニアリングとは?AI精度を高める4つの設計指針
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの開発において、「プロンプトをどれだけ工夫しても回答が安定しない」という壁に直面していませんか。実は、その原因は「指示の書き方」ではなく、AIに与えている「認知環境」にあるかもしれません。
本記事では、プロンプトエンジニアリングの次のフェーズとして注目される「コンテキストエンジニアリング(Context Engineering)」の概念と、AIエージェントの精度を飛躍的に高めるための具体的な設計手法を解説します。
この記事に対する編集部の見解
- 「情報を入れ続けるほどAIが賢くなる」は誤解。過剰な情報は矛盾とノイズを生む
- AIへの入力は量より質。必要な情報だけを適切なタイミングで渡す設計が精度を左右する
- プロンプトの工夫より「AIが何を前提に考えるか」という認知環境の設計が本質的な課題
目次
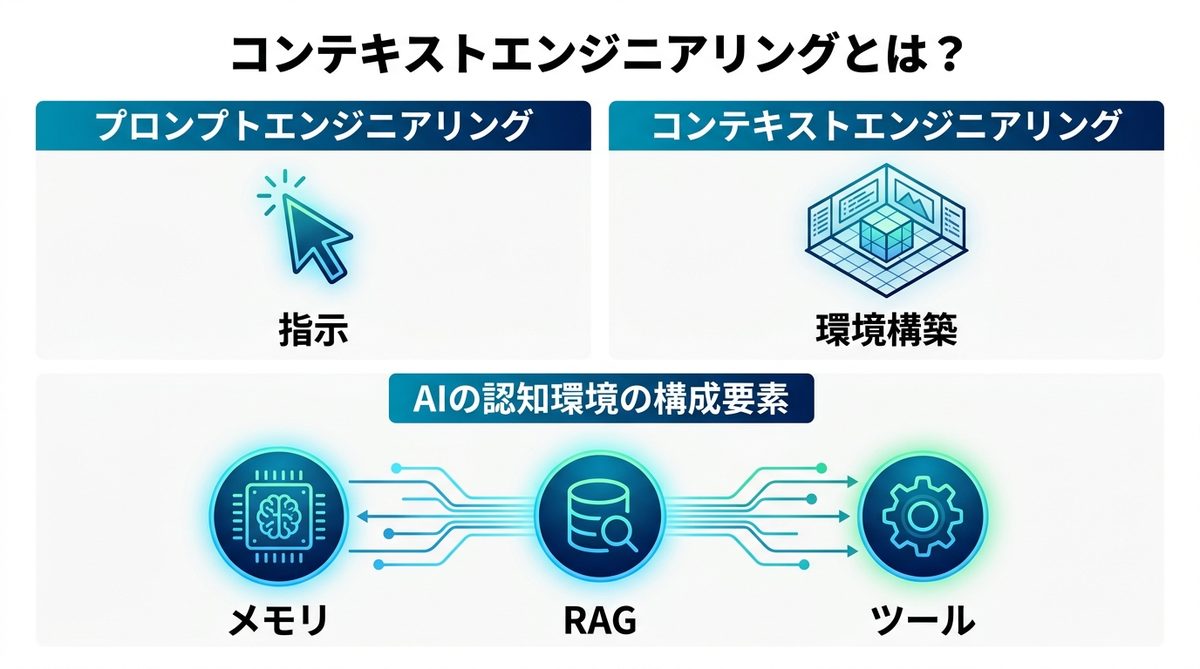
コンテキストエンジニアリングとは
コンテキストエンジニアリングは、AIが情報を正しく理解し、推論するための「環境」を構築する技術体系です。
プロンプトとの違い
プロンプトエンジニアリングが「AIに何をさせるか(指示)」を最適化するのに対し、コンテキストエンジニアリングは「AIが何を前提として考えるか(認知環境)」を設計します。プロンプトが「命令」であれば、コンテキストは「AIが働くためのオフィス環境」と言えるでしょう。
文脈設計の必要性
AIモデルの推論能力が向上した今、モデル自体をいじるよりも、入力されるデータ(文脈)をどのように整えるかで、アウトプットの質が劇的に変わります。曖昧な入力を渡せばAIは迷走し、構造化された文脈を与えればAIは卓越したパフォーマンスを発揮します。
認知環境の全体最適化
コンテキストとは、単なる文字列の羅列ではありません。以下の要素が統合された「AIの脳内メモリ」です。
* メモリ(短期・長期):対話履歴や過去の学習データ
* RAG(検索拡張生成):外部データベースから動的に取得する関連知識
* ツール(Tools):AIが実行可能な関数やAPI操作
関連記事:What is AI Agent?仕組みやチャットボットとの違いを解説
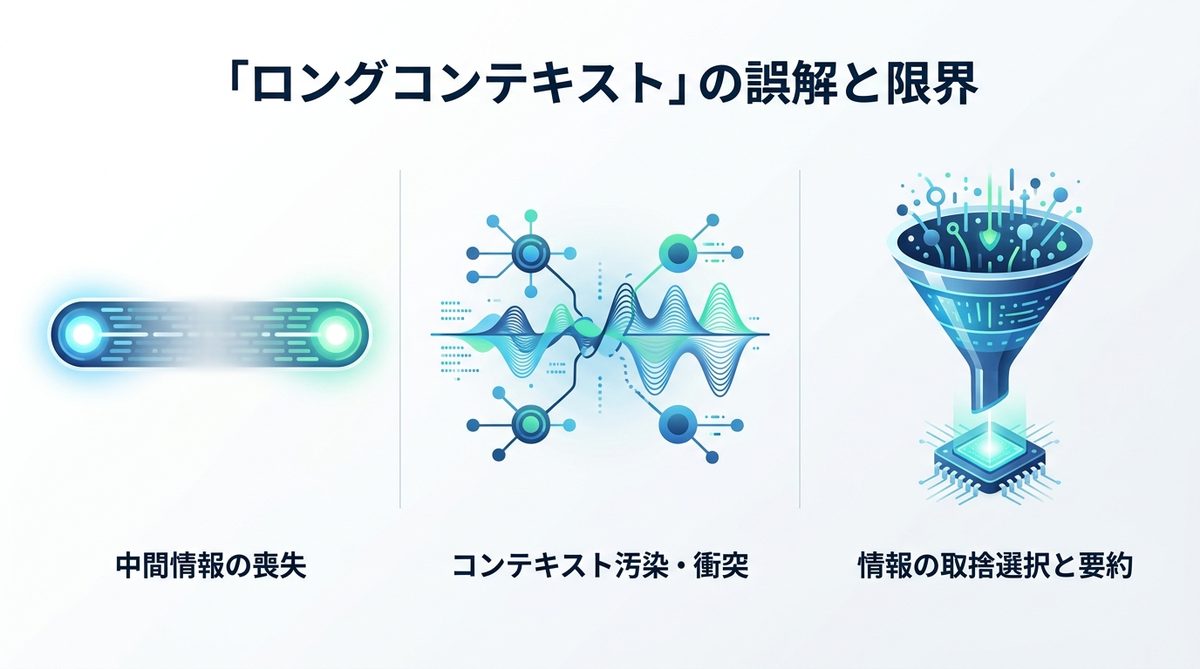
ロングコンテキストの誤解と限界
「コンテキストウィンドウ(記憶容量)が巨大なら、すべて放り込めばいい」というのは大きな間違いです。
中間情報の喪失問題
AIは長大な入力を受け取ると、冒頭と末尾の情報は記憶しやすい一方、中間に含まれる情報を「無視」または「埋没」させる傾向があります。これを「Lost in the Middle(中間情報の喪失)」と呼びます。
汚染・衝突の回避策
不要な情報が混入する「コンテキスト汚染(Context Poisoning)」や、指示同士が矛盾する「コンテキスト衝突(Context Clash)」は、AIエージェントが誤った回答を生成する最大の原因です。必要な情報だけを、適切なタイミングで注入する設計が不可欠です。
2026年の最新手法
現在の主流は、情報を詰め込むことではなく、AIが処理しやすい形に「整える」ことです。具体的なアプローチは後述する4つのステップに集約されます。
関連記事:【保存版】RAGとMCPの違いとは?AIに「考える」と「動く」を両立させる仕組みを解説
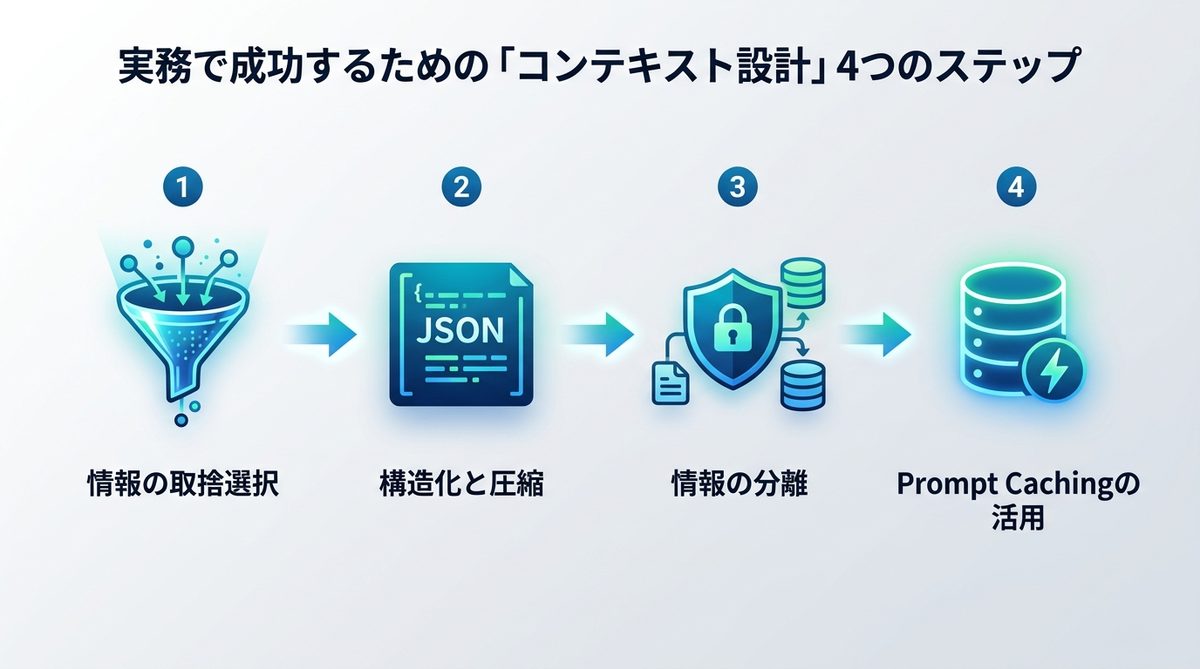
コンテキスト設計の4ステップ
AIエージェントの精度を最大化するための、エンジニアが実践すべき設計手法を紹介します。
1. 情報の取捨選択
データベース全体を検索するのではなく、クエリに対して関連性の高い情報のみをフィルタリングして抽出します。不要なノイズを遮断することで、AIの注意力をメインタスクに集中させます。
2. Write & Compress(構造化と圧縮)
データをJSONスキーマ等で構造化し、さらに重要な情報のみを抽出してトークン(AIが処理する文字単位)を節約します。これにより、推論コストを下げつつ情報の密度を高められます。
3. 情報の分離
「システム指示(System Prompt)」と「ユーザーデータ」を明確に分離します。データを直接指示に混ぜると、間接的注入(Indirect Injection)攻撃などの脆弱性が生まれるため、セキュアな隔離設計が必須です。
4. キャッシュ活用
頻繁に参照するドキュメントやプロンプトの枠組みを「キャッシュ」することで、推論の遅延を抑え、APIコストを大幅に削減します。コンテキストの再利用は、運用コスト最適化の要です。
関連記事:【2026年最新】RAGとは?生成AIをビジネスで安全に活用するための導入ロードマップ
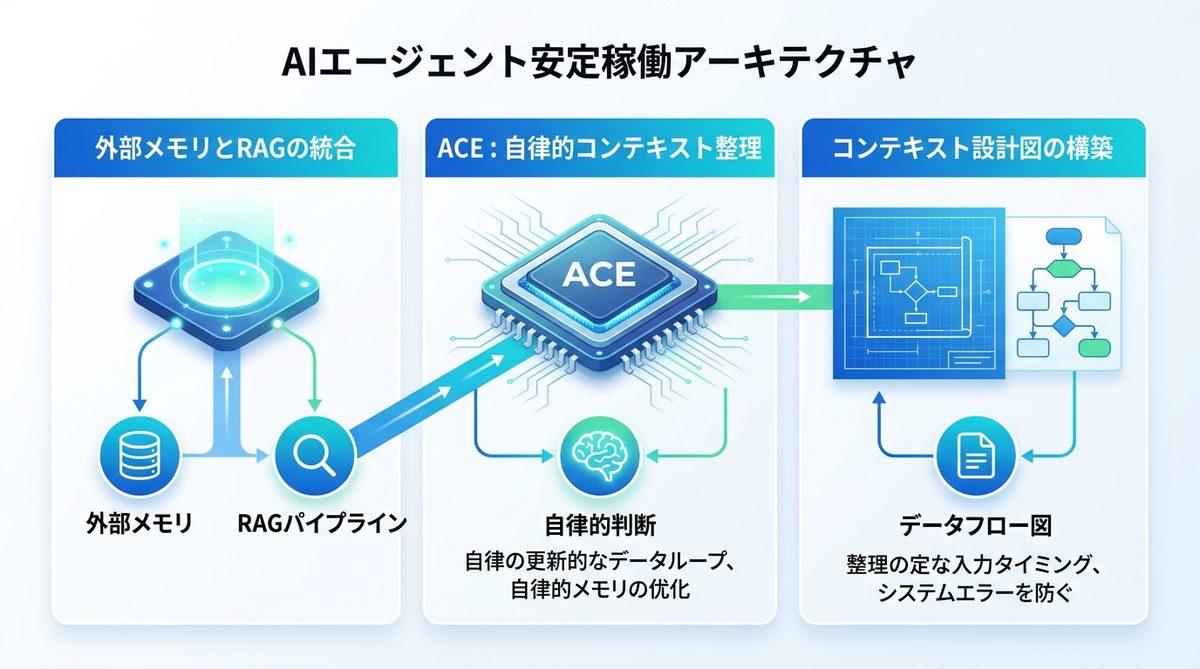
安定稼働するアーキテクチャ
システム全体をどう設計するかという視点が、エンジニアには求められます。
コンテキスト管理の仕組み
RAG(外部メモリ検索)の結果を単に貼り付けるのではなく、一度「コンテキスト管理層」を経由させ、最新の対話状況に合わせて情報の優先順位を書き換えるパイプラインを構築します。
ACEの設計思想
ACEとは、AIエージェントが「今、自分には何が必要か」を判断し、自らメモリを更新したり、不要な情報を削除したりする自律的な文脈設計手法です。
設計図の作り方
どのようなデータソースが、どのタイミングで、どのような形式で注入されるかを可視化した「データフロー図」を作成してください。これがない状態での開発は、地図なしで進む迷路のようなものです。
関連記事:【AIエージェントの協調】オーケストレーションとは?DXを加速させる「AIの組織力」
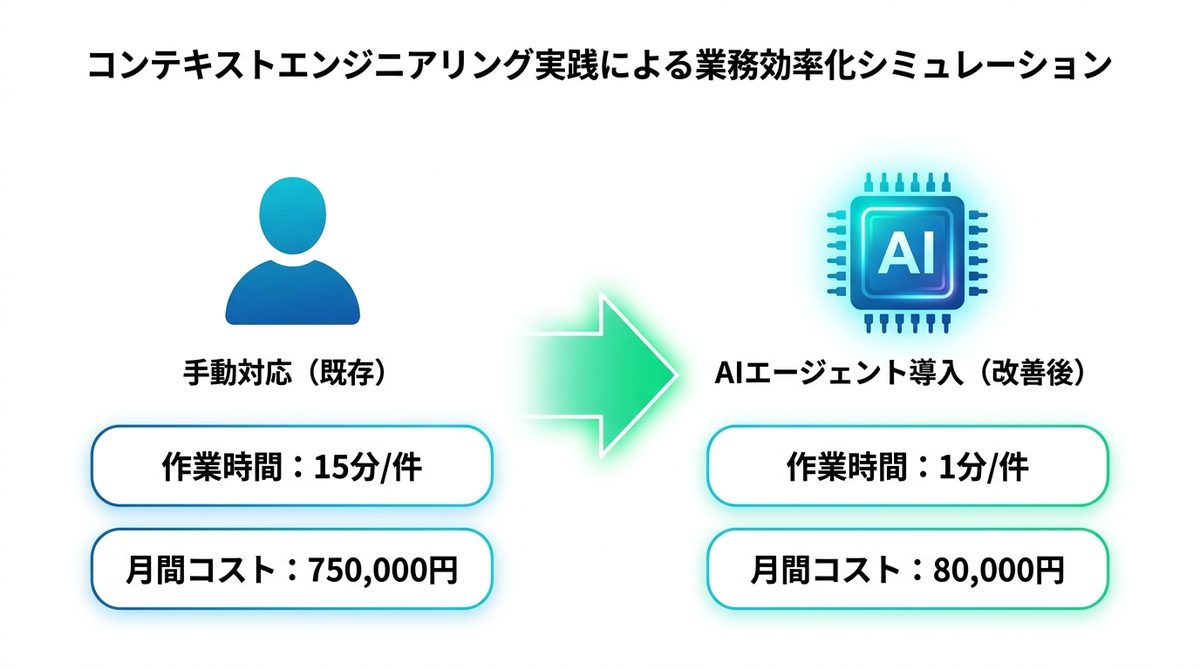
業務効率化シミュレーション
実際にコンテキストエンジニアリングを導入した場合のROI(投資対効果)を試算します。
カスタマー対応の具体例
社内のナレッジベース(ドキュメント)をRAGで検索し、AIが一次回答を生成するケースを想定します。
ROIの試算
| 項目 | 手動対応(既存) | AIエージェント導入(改善後) |
|---|---|---|
| 作業時間/件 | 15分 | 1分(確認作業) |
| 月間人件費(時給3,000円) | 750,000円 | 50,000円 |
| API費用(Claude Sonnet 4.6使用) | 0円 | 30,000円 |
| 合計コスト | 750,000円 | 80,000円 |
※削減率は業務の種類・件数・処理の複雑さによって大きく異なります。
※API料金は入力・出力トークン単価(入力$3.0/出力$15.0)に基づき、1件あたり10万トークンの処理を想定して算出。
関連記事:【トレンド解説】AIエージェントの導入とROIを最大化する3つのステップ
まとめ:2026年以降のスキル
プロンプトの調整だけで満足せず、AIの周辺環境を設計できるエンジニアこそが、次世代のAI開発をリードします。本記事のポイントをまとめます。
- プロンプトは「指示」、コンテキストは「認知環境」と捉える
- ロングコンテキストの過信を捨て、情報の取捨選択(Select/Write/Compress/Isolate)を徹底する
- AIが自律的にコンテキストを管理するACE(Agentic Context Engineering)への移行を検討する
- ROIを可視化し、システム全体のデータフローを設計する
今すぐ現在のプロンプトフローを見直し、AIの「認知環境」を最適化する設計に着手しましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- 「情報を入れ続けるほどAIが賢くなる」は誤解。過剰な情報は矛盾とノイズを生む
- AIへの入力は量より質。必要な情報だけを適切なタイミングで渡す設計が精度を左右する
- プロンプトの工夫より「AIが何を前提に考えるか」という認知環境の設計が本質的な課題
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


