
Gemini 3.5 Flash vs 3.1 Flash-Lite|総コストを最適化する使い分け
 AIエージェントナビ編集部
AIエージェントナビ編集部
多くのビジネスリーダーが、AI導入の際に「API単価」の安さだけでモデルを選んでいませんか。しかし、安価なモデルで処理が完結せず、人間による手戻りや再指示が繰り返されるたびに、現場には見えない「修正コスト」が積み上がっています。
本記事では、最新のGemini 3.5 Flashと3.1 Flash-Liteの特性を比較し、コストだけでなく「タスク完了までの総コスト」を最適化する運用戦略を解説します。
この記事に対する編集部の見解
- 3.1 Flash-Liteで十分なケースが多い。3.5 Flashが必要な場面を見極めることがコスト最適化の鍵
- 判断軸は「ミスが連鎖するか否か」——コード・契約書レビューは3.5一択
- 大量の定型処理は3.1で十分。3.5は修正コストが高い作業にだけ使う
目次
Gemini 3.5 vs 3.1:性能と経済性の違い
AIモデルの選定には、単なるスペック比較ではなく、ビジネスの現場でどのような成果をもたらすかという視点が不可欠です。
3.5のDynamic Thinkingの利益
Gemini 3.5 Flashに搭載された「Dynamic Thinking(動的思考プロセス)」は、複雑なタスクにおいてAIが自律的に思考の深さを調整する機能です。これは単なる技術的な進化ではありません。かつては人間が細かく指示を出さなければ解けなかった難題を、モデル自身が推論の道筋を立てることで、人間による「再指示」や「修正作業」を大幅に減らすことができます。つまり、AIが賢く動くことで、現場の貴重な労働時間を削減できるのです。
3.1の大量処理特化の理由
一方で、Gemini 3.1 Flash-Liteは「大量データの処理」に特化した経済的なモデルです。高いスループット(処理能力)を維持しつつ、コストを極限まで抑える設計になっています。定型的な業務においては、AIに高度な熟考を求めるよりも、一定の品質でいかに素早く大量のデータをこなすかが重視されます。このモデルは、まさに高効率が求められる現場のエンジンとして機能します。
コスト15倍の壁の捉え方
以下の比較表をご覧ください。3.5 Flashは3.1 Flash-Liteと比較して入力コストが約15倍(出力は約22倍)ですが、この差をどう評価すべきでしょうか。
| モデル名 | 入力料金(1Mトークン) | 出力料金(1Mトークン) | 特徴 |
|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | 高い推論力(Dynamic Thinking) |
| Gemini 3.1 Flash-Lite | $0.1 | $0.4 | 圧倒的なコスト効率 |
関連記事:【徹底比較】Gemini 3.5 Flash vs Claude|APIコストを3分の1にする最適解

ケース別:適したモデルの選び方
モデルの特性を理解したところで、自社の業務をどのように振り分けるべきかを見ていきましょう。
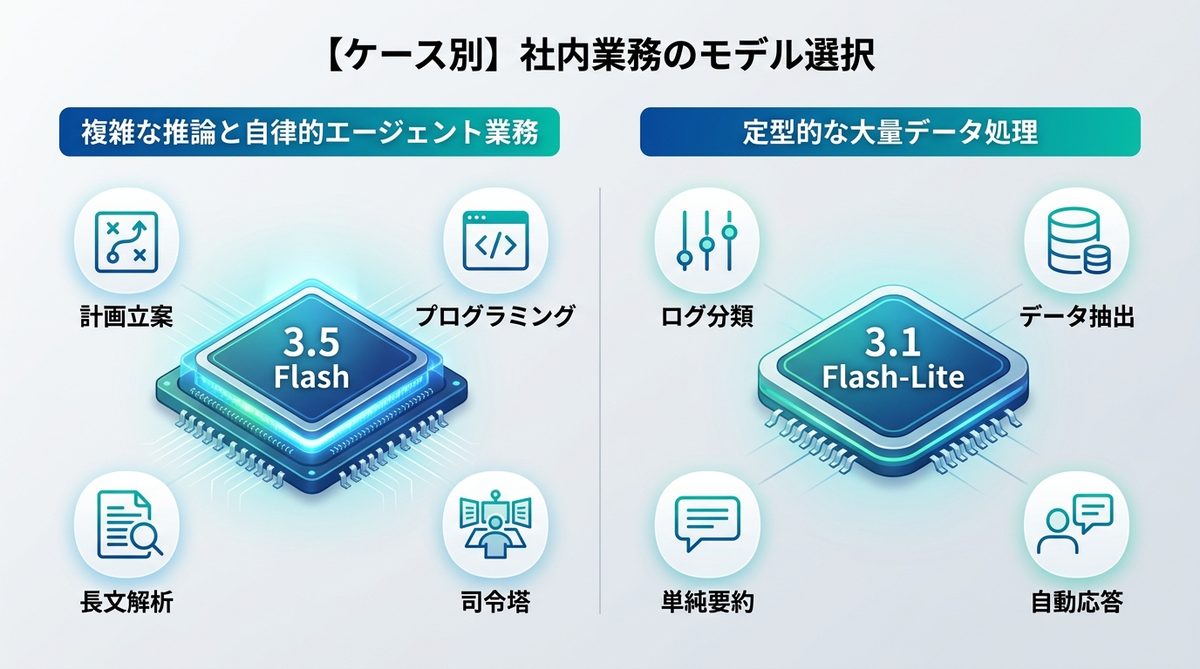
推論・エージェントは3.5
以下のような、高い判断能力が求められる業務には3.5 Flashを推奨します。
- 複数のドキュメントを照らし合わせた計画立案
- プログラミング(コード生成・デバッグ)
- 文脈の深い理解が必要な長文の解析・要約
- エージェント型のワークフローにおける司令塔役
これらは、AIが間違えると人間の修正工数が大きく膨らむタスクです。ここではモデル単価よりも精度を優先し、ヒューマンエラーを防ぐことが経営上の正解となります。
定型データ処理は3.1
一方で、以下のような定型業務は3.1 Flash-Liteに任せるべきです。
- ログデータの分類・仕分け
- 大規模なデータベースからの特定の抽出作業
- 単純な形式でのテキスト要約
- ユーザーからの定型的な問い合わせに対する自動応答
これらのタスクでは、高い精度よりも大量のインプットを安価に処理する能力が求められます。ここで3.5 Flashを使うことは、過剰投資(オーバークオリティ)にあたります。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説
コスト最適化:ハイブリッド運用
ビジネスにおけるAI活用は、「どのモデルを使うか」から「どう組み合わせるか」というフェーズへ移行しています。
最高性能にしない理由
すべてのタスクを高性能モデルで行うことは、非効率の極みです。経営陣として注力すべきは、個々のタスクに合わせた「モデルの適材適所」です。最高性能のモデルを使い分けるアーキテクチャこそが、持続可能なAI運用の要となります。
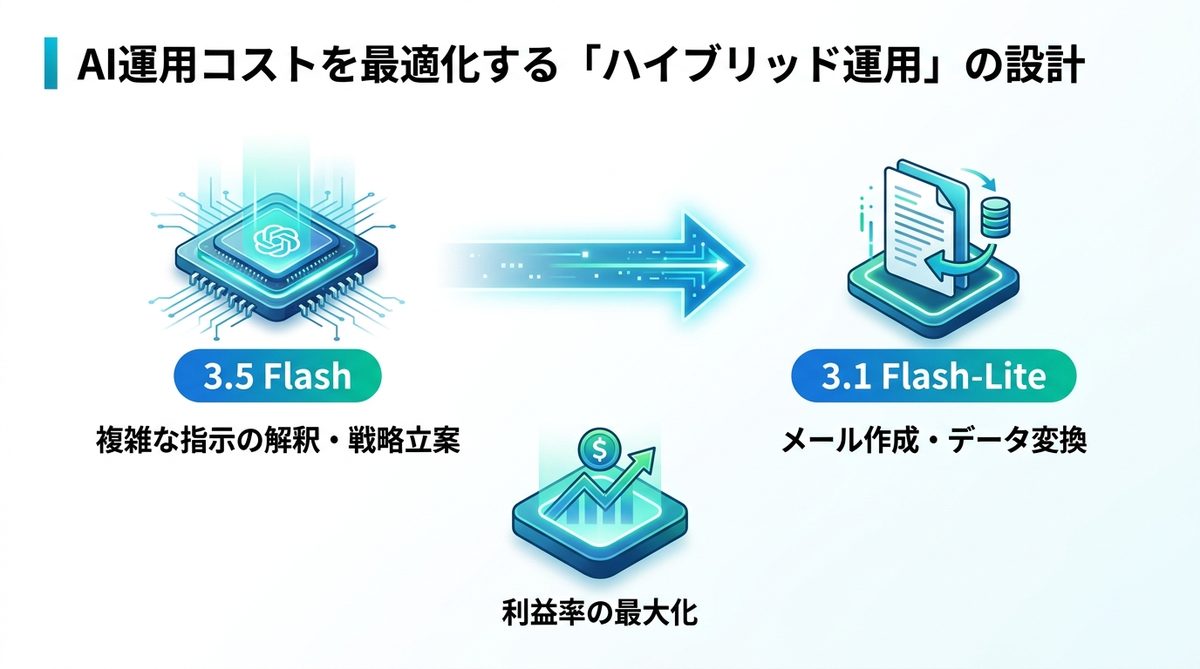
API使い分けのコストダウン
現実的な解決策は「ハイブリッド運用」です。例えば、一つのワークフローの中で以下のようにモデルを切り替えます。
1. 複雑な指示の解釈や戦略立案 → 3.5 Flash
2. 抽出された情報を元にしたメール本文の作成やデータ変換 → 3.1 Flash-Lite
このようにプロセスを分割することで、必要な箇所にだけ予算を投じ、全体的な利益率を最大化することが可能です。
関連記事:【徹底比較】Qwen3.6 vs Claude Opus 4.7|APIコストを激減させる業務活用ポートフォリオの作り方
3.5 Proを待つべきか?今すぐ最適化すべき理由
「次の高性能モデルが出るまで待とう」という考えは、競合との差を開く要因になります。
安定的な運用のすすめ
6月に控える「3.5 Pro」を待つのも一つの手ですが、今のAIエージェント業務に必要なのは「即戦力」です。現行のFlash系モデルでプロンプトやワークフローの型を構築しておけば、将来的に新しいモデルへ移行する際にもスムーズに対応できます。先行して試行錯誤を重ねた知見こそが、企業の競争優位性になります。
スモールスタートの手順
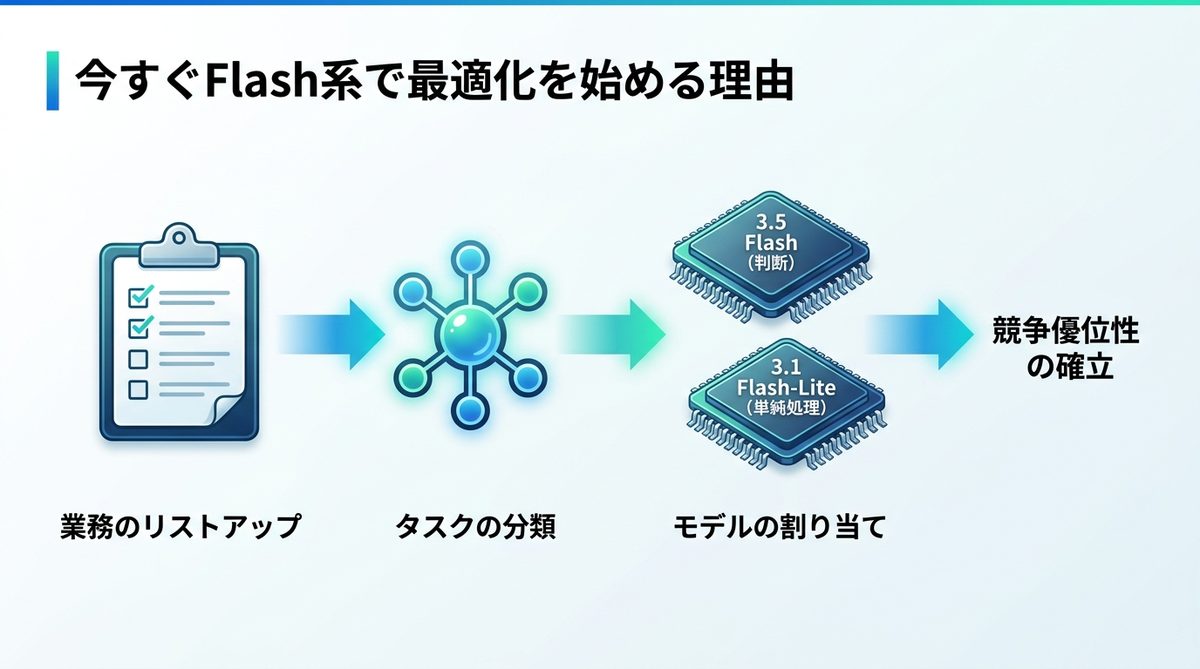
以下の3ステップで、まずは小さな改善から始めましょう。
1. 現在AIで処理している全業務をリストアップする。
2. 各タスクを「判断力が必要」か「単純な量が必要」かで分類する。
3. 「判断」タスクを3.5 Flashに、「単純処理」タスクを3.1 Flash-Liteに割り当て、費用対効果を測定する。
関連記事:【2026年最新】生成AI料金比較!目的別おすすめツールとROIを最大化する選び方
まとめ
本記事では、Gemini 3.5 Flashと3.1 Flash-Liteの比較を通じ、AI運用の利益を最大化する考え方を解説しました。
- 3.5 Flash:高い判断能力が求められる業務に割り当て、手戻り工数を削減する。
- 3.1 Flash-Lite:大量かつ定型的な業務に割り当て、処理コストを最小化する。
- ハイブリッド運用:タスクの特性に合わせてモデルを組み合わせ、ROIを最大化する。
AIを単なるツールとしてではなく、賢いチームメンバーとして使いこなすために、今すぐ貴社のAI運用体制を見直してみましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- 3.1 Flash-Liteで十分なケースが多い。3.5 Flashが必要な場面を見極めることがコスト最適化の鍵
- 判断軸は「ミスが連鎖するか否か」——コード・契約書レビューは3.5一択
- 大量の定型処理は3.1で十分。3.5は修正コストが高い作業にだけ使う
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


