
DeepSeek V4 vs Claude Opus 4.7比較|コスト最大1700倍のハイブリッド運用術
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントによる業務自動化が加速する中、「どのモデルを使えばよいか」という問いは「どう組み合わせるか」という戦略的な課題へと進化しています。開発現場でコストと品質のバランスに悩むリーダーのために、本記事ではClaude Opus 4.7とDeepSeek V4を最適に使い分けるハイブリッド運用術を解説します。
この記事に対する編集部の見解
- DeepSeek V4はコーディング性能でOpusに迫りつつ、API料金は約90分の1という異常なコスパ
- SWE-benchは一指標に過ぎず、長文推論・要件定義・安全判断ではOpusが明確に上
- 「ミスの被害が大きいタスク」はOpus、「量をこなす実行タスク」はDeepSeekの仕分けが鍵
徹底比較|スペック・ベンチ・コスト
モデルの選定には、単なるスペック比較だけでなく、実務における経済性とパフォーマンスの相関関係を理解することが不可欠です。
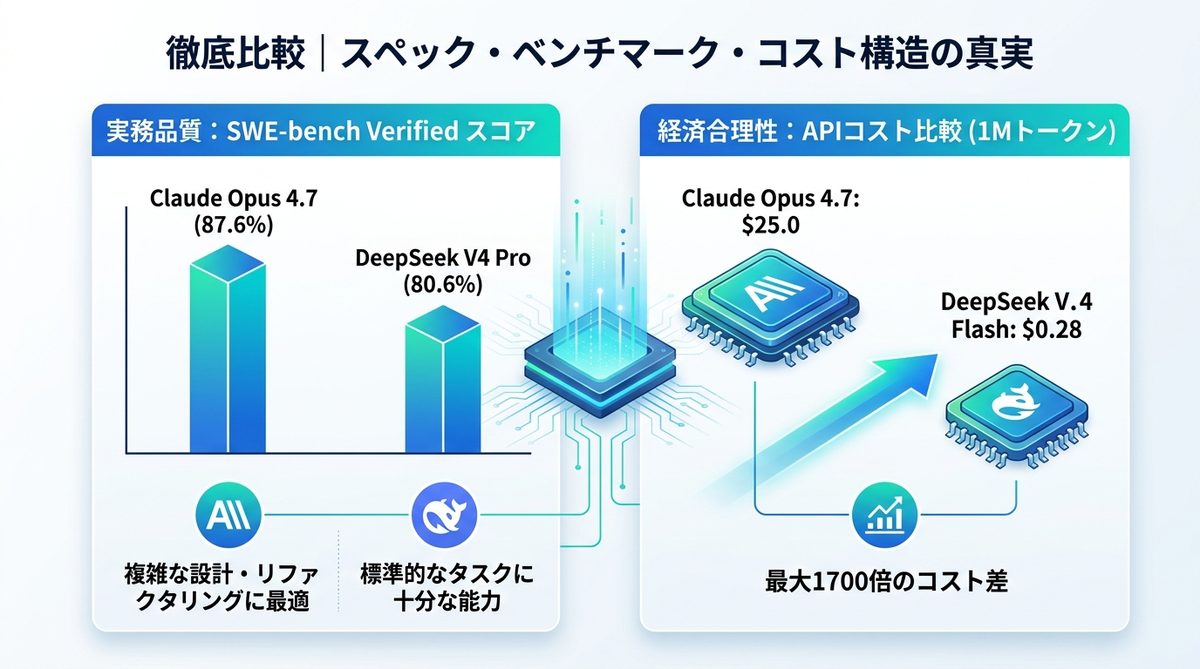
SWE-benchスコア比較
エンジニアリングの能力を測る指標として定評のある「SWE-bench Verified(GitHub上の実課題を解決する能力測定)」に基づくと、両者の特性が浮き彫りになります。
| モデル | SWE-bench Verified スコア |
|---|---|
| Claude Opus 4.7 | 87.6% |
| DeepSeek V4 Pro | 80.6% |
この約7%の差は、複雑なアーキテクチャ設計や、依存関係の深いレガシーコードのリファクタリング(構造改善)において顕著に表れます。Opus 4.7は「難問に対する着実な正解率」に優れ、V4は「標準的なコーディングタスクにおける十分な回答能力」を備えていると解釈してください。
API単価1700倍の経済合理性
API料金の構造を知ることは、AIエージェントチームの予算管理において直結する最重要事項です。
| プロバイダー | モデル | 入力料金(1Mトークン) | 出力料金(1Mトークン) |
|---|---|---|---|
| Anthropic | Claude Opus 4.7 | $5.0 | $25.0 |
| DeepSeek | DeepSeek V4 Flash | $0.14 | $0.28 |
DeepSeek V4 Flashの出力料金と、Claude Opus 4.7の出力料金を比較すると、実に約89倍の差があります。これに計算量やコンテキスト(記憶容量)の消費を含めると、構築するシステムによってはコスト差が最大1700倍に達する場合もあります。このコスト差を無視してすべての処理に高価なOpusを充てるのは、経営視点では非効率と言わざるを得ません。
関連記事:【徹底比較】Qwen3.6 vs Claude Opus 4.7|APIコストを激減させる業務活用ポートフォリオの作り方
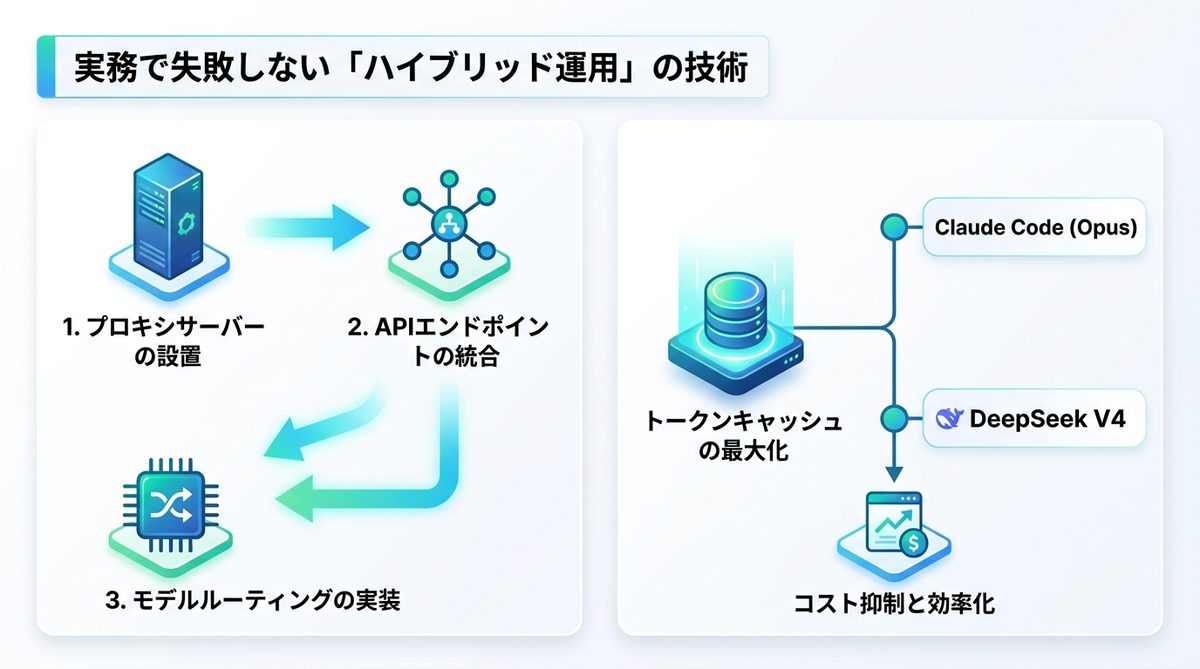
実務で失敗しないハイブリッド運用
両者の強みを引き出すには、ツールを介した自動ルーティング(経路制御)が有効です。
Claude Code連携設定
GitHubで普及している「deepclaude」のようなプロキシ(代理)ツールを活用することで、Claude Codeの利便性を維持しながら、裏側でモデルを切り替えることが可能です。具体的には、以下の3ステップで環境を構築します。
- プロキシサーバーの設置: リクエストのヘッダーを解析し、特定のキーワードやトークン量に応じてモデルを分岐させる設定を導入します。
- APIエンドポイントの統合: Claude Codeのクライアント設定を、自前のプロキシ経由で接続するように書き換えます。
- モデルルーティングの実装: 「複雑な論理推論が必要な場合はOpusへ転送し、単純なファイル生成やテスト実行はDeepSeekへ送る」という条件分岐をコード化します。
トークンキャッシュ活用戦略
コストを抑えるためには、過去のコンテキストを再利用する「トークンキャッシュ」の活用が鍵です。Opus 4.7で生成した高品質な設計図(プロンプト)をキャッシュし、それを基にDeepSeek V4がコードを量産するという連携を行うことで、全体コストを大幅に抑制できます。
関連記事:【比較検証】Claude Codeの従量課金は高額?予算上限を設定して開発現場のROIを最大化する方法
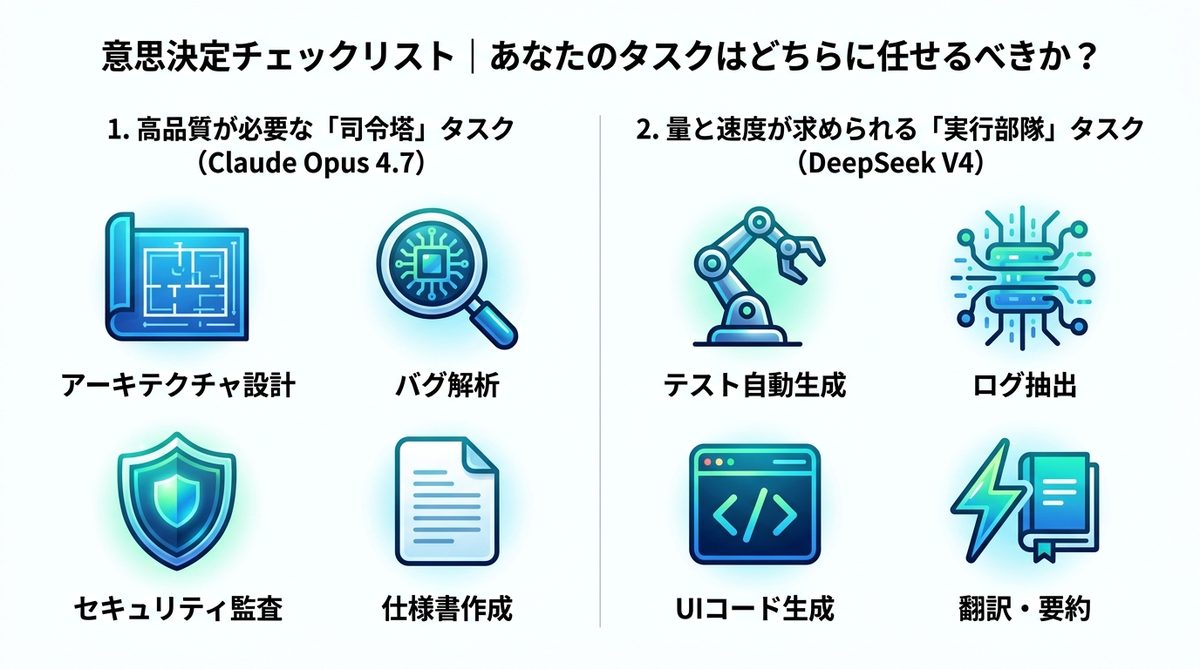
意思決定チェックリスト
タスクの種類によって、最適なモデルは明確に分かれます。
司令塔タスク(Claude Opus)
失敗が許されない「設計」や「意思決定」のフェーズには、精度の高いOpusを充てます。
- 新規アーキテクチャの設計・選定
- 難解なバグの根本原因解析(Root Cause Analysis)
- セキュリティ監査と脆弱性診断
- 重要な外部仕様のドキュメント生成
実行部隊タスク(DeepSeek V4)
繰り返しの多いタスクや、修正が容易なタスクはDeepSeekに任せてコストを最大化します。
- ユニットテスト(単体テスト)の自動生成
- 大規模なログデータからのエラー抽出
- 定型的なUIコンポーネントのコード生成
- ドキュメントの翻訳や要約作業
関連記事:【比較】DeepSeek V4 Pro vs Flash|コスト12倍の差をビジネスで使い分ける検証
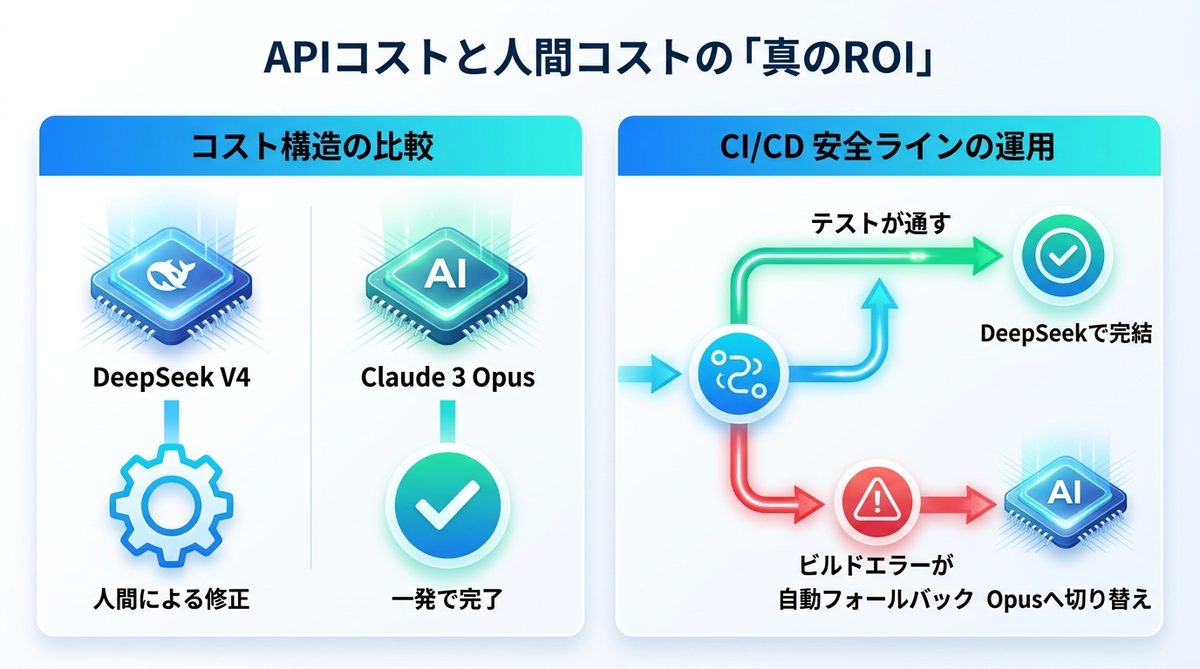
APIコストと人間コストの真のROI
AI運用において最も見落とされがちなのが、「AIが作ったものを修正する人間工数」です。
コード修正・検品の工数見積
DeepSeek V4の安さは魅力ですが、Opusより修正回数が増える可能性があります。例えば、「DeepSeekで生成して人間が修正する時間」と「Opusで一発で通す時間」を比較し、エンジニアの時給と照らし合わせて損益分岐点を算出してください。
品質低下の許容ライン
CI/CD(継続的インテグレーション/継続的デリバリー)環境にAIを組み込む際は、以下の安全ラインを設けて運用します。
- テストコードが自動で通る範囲ならDeepSeekで完結させる
- ビルドエラーが頻発する場合は、即座にOpusへ切り替える自動フォールバック設定を入れる
関連記事:【2026年最新】AIエージェントの料金比較|導入費用・隠れコスト・ROIの計算方法まで徹底解説
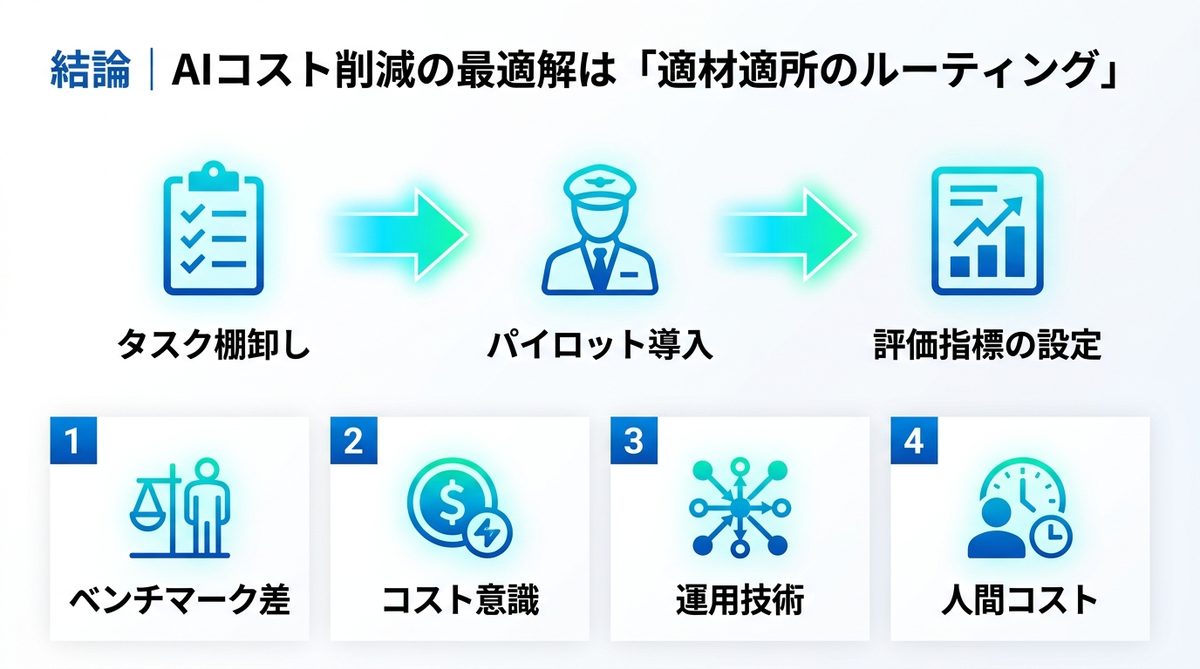
結論|適材適所のルーティング
AI運用における最大のコストは、モデルの料金そのものではなく、AIを使いこなすための組織の「判断コスト」です。
運用フロー改善の3ステップ
- タスク棚卸し: 開発ワークフローを「設計・判断」「コーディング・実行」「テスト・修正」の3つに分解する。
- パイロット導入: まずはテスト作成などの低リスクな業務にDeepSeek V4を導入し、既存のOpus活用フローと併用する。
- 評価指標の設定: 「コスト削減率」だけでなく、「修正にかかった時間」を計測し、モデルの切り替え基準を最適化する。
まとめ
- ベンチマーク差: Opus 4.7(87.6%)とV4(80.6%)の差を認識し、タスクの難易度で使い分ける。
- コスト意識: API単価の圧倒的な差を活かし、実行系タスクを低価格モデルへ寄せることが必須。
- 運用技術: プロキシツールを用いた透過的なルーティングで、開発体験を落とさずにコストを最適化する。
- 人間コスト: 修正工数を見据えた「モデルの切り替えライン」を現場ごとに定義する。
まずは、現在お使いのClaude Codeに、DeepSeek V4をバックエンドとして組み込むところから始めてみてください。今すぐAIコストの最適化を始めましょう。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集部のまとめ
- DeepSeek V4はコーディング性能でOpusに迫りつつ、API料金は約90分の1という異常なコスパ
- SWE-benchは一指標に過ぎず、長文推論・要件定義・安全判断ではOpusが明確に上
- 「ミスの被害が大きいタスク」はOpus、「量をこなす実行タスク」はDeepSeekの仕分けが鍵
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


