
DiffusionGemmaがOllamaで動かない原因と代替の実行方法
 AIエージェントナビ編集部
AIエージェントナビ編集部
最新の高性能モデルをローカル環境で試そうとOllamaを導入したものの、エラーに阻まれて先に進めず困っていませんか。特にGoogleが発表した「DiffusionGemma」は、その革新的なアーキテクチャゆえに、従来のLLMと同じ方法では起動できないという課題があります。本記事では、エラーの根本原因を解明し、今すぐこの次世代モデルを体験するための具体的な代替手段と必要スペックを徹底解説します。
DiffusionGemmaの特徴
「拡散型」を採用した実験的モデル
DiffusionGemmaは、Googleが「Google AI」ブランドの下で公開した実験的なオープンモデルです。最大の特徴は、従来の言語モデルで主流だった自己回帰型ではなく、「拡散型(Diffusion-based)」のテキスト生成を採用している点にあります。ベースモデルにはGemma 4が採用されており、モデルサイズは26B(260億パラメーター)ですが、MoE(Mixture of Experts:専門家混合モデル)アーキテクチャによって、推論時にはそのうちの4B(40億パラメーター)のみがアクティブになる効率的な設計となっています。
ライセンスと通常Gemmaとの違い
ライセンスは「Apache 2.0」で提供されており、商用利用を含めた柔軟な活用が期待されています。ただし、このモデルは「通常のGemma」とは内部構造やデータの生成プロセスが根本から異なるため、Ollamaのような標準的なツールで動かすには、特別な手順やランタイムの対応が必須となります。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
エラーが出る原因
Ollamaの未対応
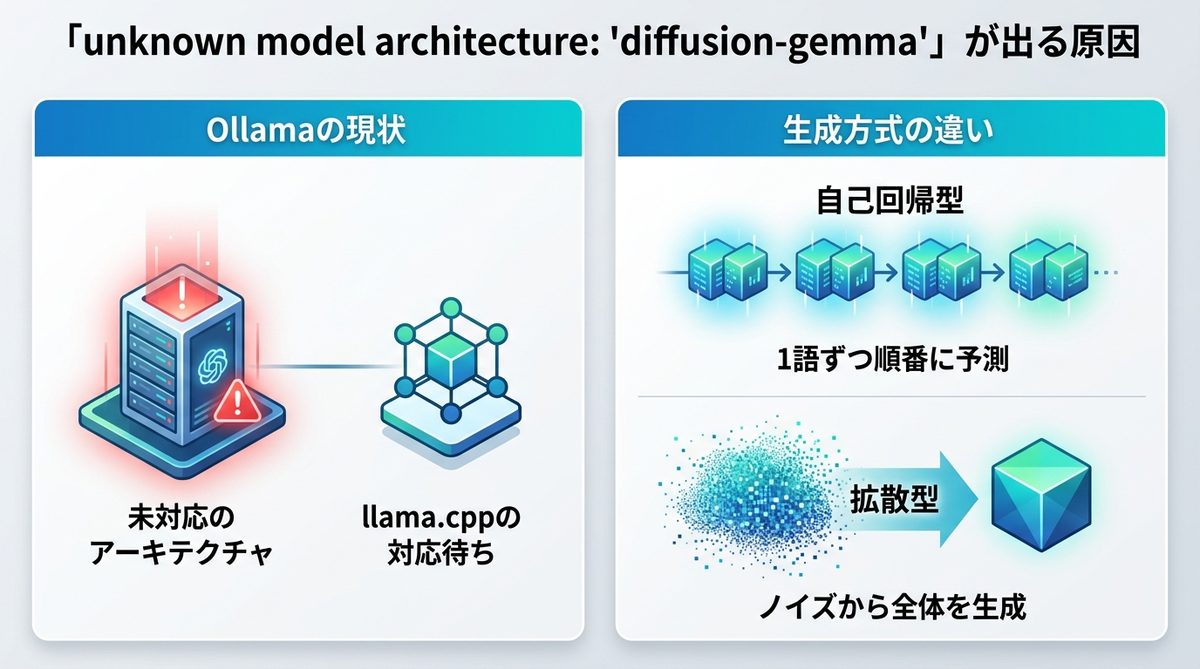
現在、OllamaでDiffusionGemmaを実行しようとすると「unknown model architecture: 'diffusion-gemma'」というエラーが表示されます。このエラーは、ユーザー側の設定ミスやモデルファイルの破損、あるいは環境構築の不備ではありません。単純に、現時点のOllamaが「diffusion-gemma」という新しいアーキテクチャを認識・処理するコードを実装していないことが原因です。
GitHubのOllama公式リポジトリに立てられたIssue(#16664・2026-06-10起票)でも、多くのユーザーがこの問題に直面していることが報告されています。このIssueによれば、Ollamaが内部で使用している推論エンジンであるllama.cpp側での対応が進まない限り、Ollama単体でのアップデートで解決する見込みはありません。そのため、現時点では設定変更や再インストールで解決しようとするのは時間の浪費といえます。
生成方式の違い
なぜ、従来のLLMに対応しているOllamaでDiffusionGemmaが動かないのでしょうか。その理由は、非エンジニアの方にも分かりやすく説明すると、AIが言葉を紡ぎ出す「思考プロセス」が全く異なるからです。
- 自己回帰型(従来のLLM): 「私は」「AI」「エージェント」「です」というように、前の言葉に続く「最も確率の高い次の1語」を順番に予測して文章を構築します。
- 拡散型(DiffusionGemma): 画像生成AIのように、最初はノイズのような未完成の状態から、全体を同時に少しずつ整えて、最終的な文章を作り上げます。
Ollamaの現在のランタイムは、1語ずつ順番に処理する「自己回帰型」に特化しています。一方で、拡散型には「ノイズを除去して整える(サンプリング)」という専用の計算ステップが必要になります。この専用ランタイム(サンプラー)がOllamaに未搭載であることが、エラーの正体です。
関連記事:Gemma 4とは?ビジネス導入ガイド|モデル選定・環境構築の全手順
エラーの切り分け
もし実行時にエラーが出た場合、その内容が「unknown model architecture」であれば、それは今回のアーキテクチャ未対応が原因です。この場合は、Ollamaの使用を諦め、後述する代替手段に切り替える必要があります。
一方で、別のエラー(例えば「out of memory」ならGPUメモリ不足、「file not found」ならモデルパスの指定ミス)が出ている場合は、原因が異なります。まずはエラーログの冒頭に「unknown model architecture」と記載されているかどうかを確認してください。
関連記事:Gemma 4 12BをOllamaで動かす|PC完結の会議分析と機密資料の解析術
ローカルでの代替手段
Ollamaでの公式対応を待てない場合でも、代替のツールを使用すればDiffusionGemmaをローカル環境で動かすことは可能です。Google公式によるモデルの配布元は「Hugging Face」「Kaggle」「Vertex AI」の3カ所ですが、これらを自身の環境やスキルに合わせて選択できる実行環境を以下にまとめました。
| 手段 | 難易度 | 必要なもの | 向いている人 |
|---|---|---|---|
| 1. Unsloth Studio | 低 | GUI環境 | 最短・最速で試したい人 |
| 2. llama.cpp専用ブランチ | 中 | コンパイル・ビルド環境 | CLI操作に慣れたエンジニア |
| 3. vLLM / Transformers | 高 | Python環境・GPUドライバ | 開発・研究用途の専門家 |
Unsloth活用
最も推奨されるのが、Unsloth Studioを使用する方法です。UnslothはDiffusionGemmaのような最先端モデルのサポートが非常に早く、GUIベースで操作できるため、コマンドラインに不慣れな方でも導入のハードルが低いです。複雑な依存関係の解決も自動で行ってくれるため、エラーに悩まされることなく、数クリックでモデルを起動できます。
llama.cppビルド
エンジニアの方であれば、llama.cppのソースコードから、拡散型に対応した専用ブランチをビルドするのが良いでしょう。Unslothが案内している拡散対応のPRブランチなどを利用することで、Ollamaよりも柔軟なパラメーター調整が可能になります。ただし、ビルドには適切なコンパイラ設定が必要となります。
vLLM・Transformers
独自のアプリケーションに組み込みたい、あるいは詳細な推論テストを行いたい場合は、vLLMやHugging FaceのTransformersライブラリを使用します。Googleが公式に公開している推論コードをベースに、Python環境で実行する方法です。最新の最適化技術を適用できる一方で、GPUのメモリ管理やライブラリのバージョン整合性を自身で管理する必要があります。

必要なスペックの目安
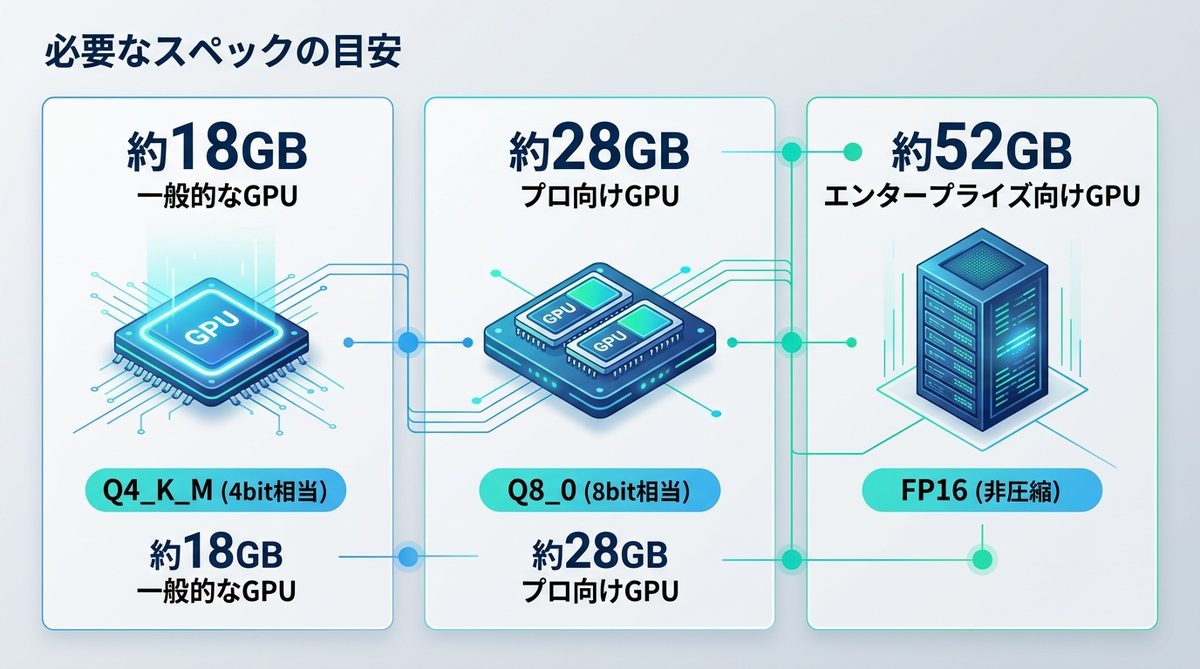
DiffusionGemmaは、MoEを採用しているとはいえ、総パラメーター数は26Bと巨大です。そのため、VRAM(ビデオメモリ)の容量が動作の成否を分けます。以下に、Unslothなどで配布されているGGUF形式(diffusiongemma-26B-A4B-it-GGUF)を使用した場合の量子化別の必要メモリ目安を示します。
| 量子化レベル | 推定VRAM使用量 | 備考 |
|---|---|---|
| Q4_K_M (4bit相当) | 約18GB | 一般的なコンシューマー向けGPU(RTX 3090/4090など)で動作可能 |
| Q8_0 (8bit相当) | 約28GB | プロ向けGPU(A6000など)または複数GPUが必要 |
| FP16 (非圧縮) | 約52GB | エンタープライズ向けGPU(H100/A100)を推奨 |
個人のローカル環境で動かすのであれば、Q4_K_M(4bit量子化)モデルが現実的です。18GB程度のVRAMを確保できれば、快適な推論速度でテキスト生成を体験できます。
関連記事:Gemma 4 12B vs Llama 4|16GB PCで選ぶべきはどっち?
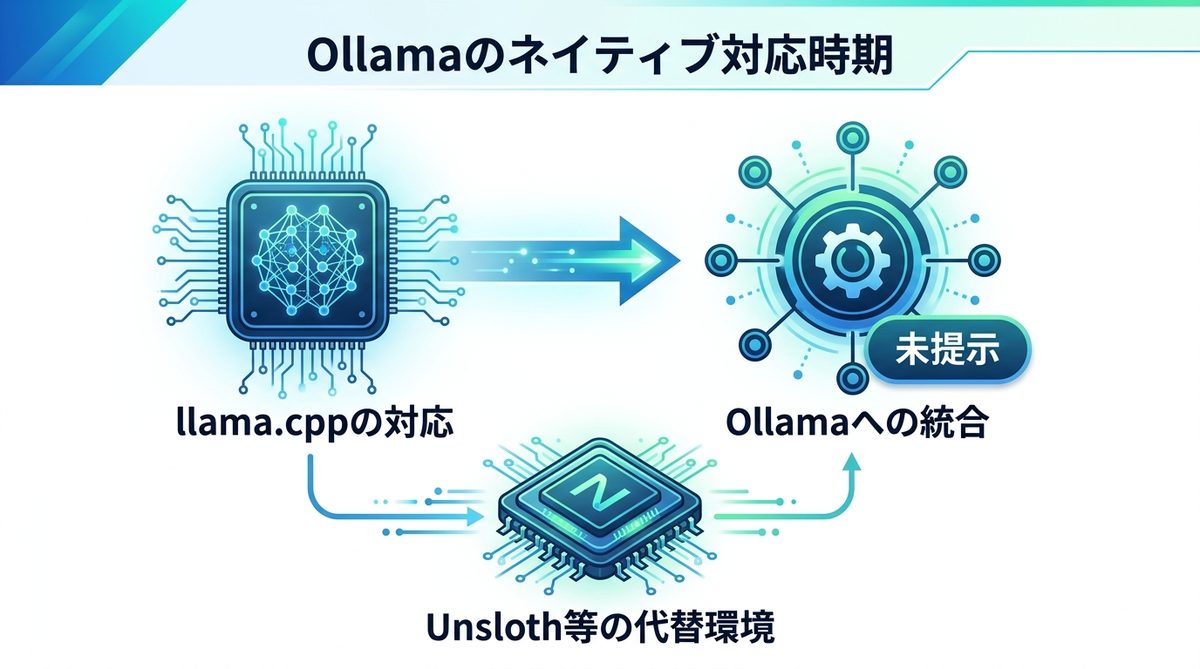
Ollamaの対応時期
現時点では、Ollamaの公式開発チームからDiffusionGemmaへのネイティブ対応時期は「未提示」となっています。Ollamaのロードマップは、基盤となるllama.cppの動向に大きく左右されます。llama.cppの本家リポジトリ(Mainブランチ)に拡散型アーキテクチャのサポートが完全に取り込まれれば、その数週間以内にはOllamaでも利用可能になる可能性が高いでしょう。
しかし、現段階では実験的なモデルという位置づけであるため、公式サポートを待つよりも、前述のUnslothなどの代替環境を構築してしまったほうが効率的です。
まとめ
DiffusionGemmaのOllama実行におけるトラブルシューティングをまとめると、以下の3点に集約されます。
- エラーは設定ミスではない: 「unknown model architecture」は、Ollama側がまだ拡散型アーキテクチャに対応していないために発生するものです。
- 今すぐ動かすなら代替手段を: Unsloth Studioのような、拡散型モデルにいち早く対応しているツールを選択することで、ローカル実行が可能です。
- 対応状況は今後変わりうる: 実験的なモデルであるため、コミュニティの動向(llama.cppのPR状況)次第でOllamaのネイティブ対応が進む可能性があります。最新情報はGitHubのIssue #16664をチェックしてください。
設定の修正に時間を費やすのではなく、適切な代替ツールと必要なVRAMを確保することで、この非常にユニークな「拡散型テキスト生成」の可能性をいち早く探ってみてください。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


