
Nemotron 3 Super比較|AIエージェントの最適化戦略
 AIエージェントナビ編集部
AIエージェントナビ編集部
AIエージェントの構築において、GPT-5やClaude Opusといった高性能モデルをただ使い続けることに限界を感じていませんか。モデルの推論コストと応答速度が、開発プロジェクトの足枷になるケースが増えています。
本記事では、次世代の推論基盤として注目される「Nemotron 3 Super」および「Nano」の性能を深掘りし、実務における最適な使い分け戦略を解説します。
この記事に対する編集部の見解
- NVIDIAのオープンウェイトモデルで、自社GPUにデプロイすればクローズ環境で運用可能
- Super=思考コスト高、Nano=軽量・高速、エージェント工程ごとに切り替えるのが基本
- 「全工程エース投入」より「適材適所」がコストと性能を両立する最適解
目次
万能モデルだけでは上手くいかない理由
エージェント開発の現場では、すべての判断を単一の「万能モデル」に委ねることで、予期せぬ停滞が発生しています。
高コストな「思考税」の正体
AIエージェントが複雑な推論を行う際、モデル内部で推論時間を長く取るほど、API利用料金は跳ね上がります。これを我々は「思考税」と呼んでいます。特に長文のコンテキスト(記憶容量)を処理する場合、すべてのトークンに対して高コストな万能モデルを適用すると、予算の大半が推論コストで消滅してしまうのです。
コンテキスト爆発と遅延の影響
エージェントが過去の履歴を長く参照すればするほど、入力トークン数は膨れ上がります。これがコンテキスト爆発を引き起こし、応答の遅延を招きます。顧客対応を行うAIエージェントにおいて、数秒の遅延は体験価値の劇的な低下を意味し、ビジネス上の機会損失に直結します。
関連記事:【2026年版】AIエージェント比較表付き!おすすめツールと選び方を徹底解説
Nemotron 3 Super・Nano比較
モデルの選定においては、タスクの複雑さとコストのバランスを見極める必要があります。
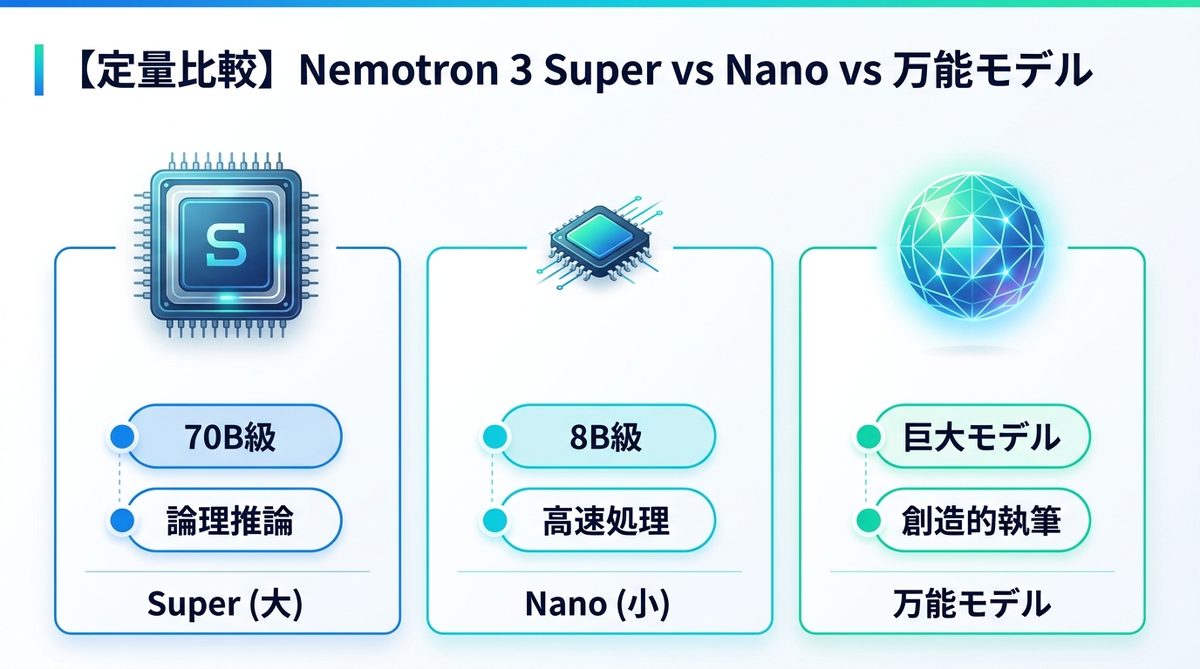
パラメータ・コスト比較表
| モデル区分 | 推定パラメータ数 | コスト効率 | 日本語安定性 | 推奨ユースケース |
|---|---|---|---|---|
| Super (大) | 70B級 | 低~中 | 極めて高い | 複雑な論理推論・計画立案 |
| Nano (小) | 8B級 | 極めて高い | 高い | 要約・抽出・定型処理 |
| 万能モデル | 不明(巨大) | 低い | 最高 | 創造的な執筆・多言語翻訳 |
推論速度と精度の判断軸
- Superの活用: コード生成のデバッグや、複雑な要件定義書の分析など、高い論理性が求められるタスクに適しています。
- Nanoの活用: 大量データのフィルタリングや、チャット履歴の要約など、速度が求められるタスクに最適です。
関連記事:【2026年最新】生成AI比較|企業導入を成功させる6つの選定軸と安全なガバナンス設計
Hybrid Mamba-Transformerの恩恵
Nemotron 3シリーズが注目される理由は、その革新的なアーキテクチャにあります。
コスト削減の技術的根拠
従来のTransformer(深層学習モデルの構造)は、履歴が長くなるほど処理負荷が二乗で増加する性質がありました。一方、Mamba-2(高速なシーケンス処理構造)を融合させることで、メモリ効率を劇的に向上させました。これにより、長いコンテキストを保持しつつも、推論コストを最小限に抑えることが可能です。
NVFP4によるスループット改善
NVIDIAのNVFP4(専用の量子化・圧縮技術)を適用することで、従来のモデルと比較して最大で約5倍の高速化事例が報告されています。これは、サーバーの応答待ち時間を大幅に減らし、ユーザー体験を向上させる決定的な要因となります。
関連記事:【比較検証】Gemma 4とGemma 3の違いを解説|自社専用モデル構築の選定基準と4つのモデルサイズ
API実装とプロバイダー選定
実際にモデルを運用環境へ導入するための具体的な実装手法を紹介します。
OpenRouter/NIMでの実装コード:enable_thinkingの制御方法
以下のコードは、OpenRouter経由でenable_thinking(思考プロセスの制御)を有効にし、推論を制御する例です。
# 推論プロバイダーへのリクエスト例 response = client.chat.completions.create( model="nvidia/nemotron-3-super", messages=[{"role": "user", "content": "次の課題をステップバイステップで解決せよ"}], extra_body={ "enable_thinking": True, "thinking_budget": 1024 # 思考の深さをトークン単位で制限 } )
安定運用できる推論環境の選び方
- DeepInfra: 低遅延かつ安価な推論が可能なため、Nanoモデルの大量リクエストに適しています。
- Together AI: 安定した可用性を誇り、Superモデルを長時間稼働させる際のバックエンドとして信頼性が高いです。
関連記事:【2026年最新】AIエージェントの料金比較|導入費用・隠れコスト・ROIの計算方法まで徹底解説
Super・Nanoのハイブリッド戦略
単一のモデルで完結させず、適材適所でモデルを切り替える構成が、現在のエージェント開発における最適解です。
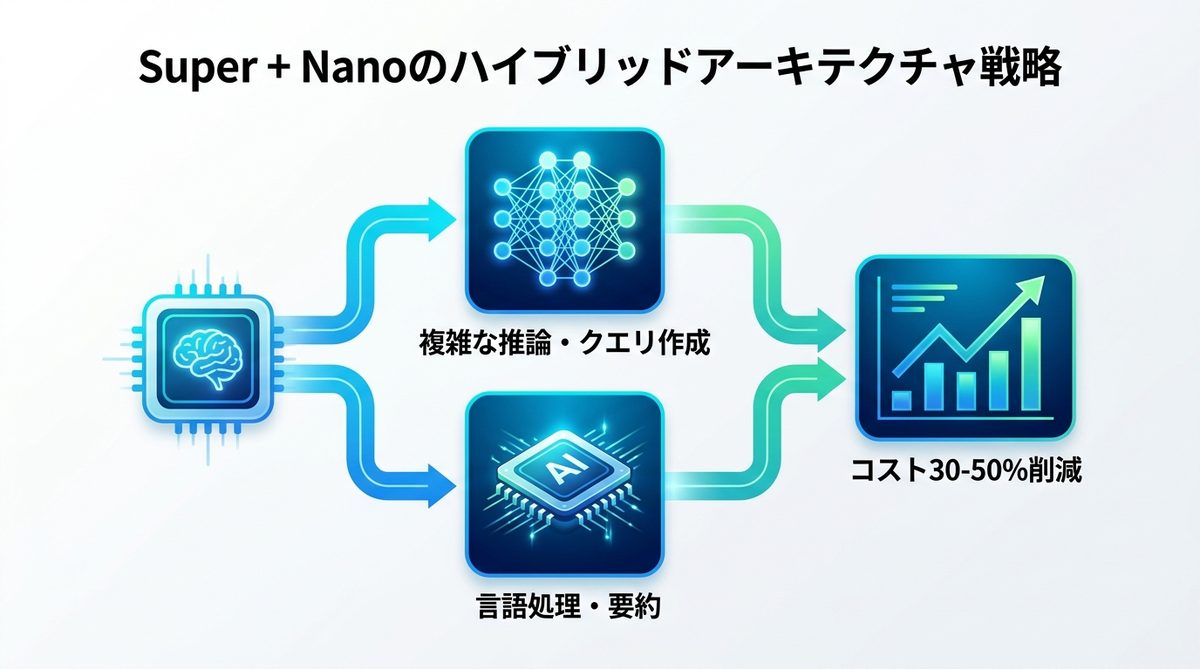
SuperとNanoの使い分け
エージェントの思考プロセスを分割しましょう。例えば、「複雑な検索クエリの作成」にはSuperモデルを使い、「検索結果の要約」にはNanoモデルを配置します。これにより、精度を維持しながら全体コストを削減できます。
モデル切り替えによるROI最大化
このハイブリッド構成により、全処理を高性能モデルで行う場合に比べ、インフラコストを平均的に30〜50%程度最適化できる可能性があります。ビジネスにおいては、この差分を別の機能開発やデータ投資に回すことが可能です。
関連記事:DeepSeek V4 vs Claude Opus 4.7比較|コスト最大1700倍のハイブリッド運用術
まとめ:運用コストの最適化
Nemotron 3シリーズを活用したアーキテクチャの要点は以下の通りです。
- 万能モデルへの依存は「思考税」を増大させるため、避けるべきである
- Superモデル(高精度)とNanoモデル(高速)をタスクに応じて使い分ける
- Hybrid Mamba-Transformerにより、長文処理と低コスト化を両立する
- 実装時は
enable_thinkingを活用し、推論予算を細かく制御する
まずは、現在開発中のエージェントで最もコストがかかっている処理を特定し、その一部分をNanoモデルに置き換える検証から始めてみてください。今すぐ開発環境でモデルの切り替え検証を行い、エージェントの効率性を飛躍的に高めましょう。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
編集部のまとめ
- NVIDIAのオープンウェイトモデルで、自社GPUにデプロイすればクローズ環境で運用可能
- Super=思考コスト高、Nano=軽量・高速、エージェント工程ごとに切り替えるのが基本
- 「全工程エース投入」より「適材適所」がコストと性能を両立する最適解
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


