
【エンジニア必見】AIエージェント構築の完全ガイド|RAG・ファインチューニング・最新フレームワークの使い分け
 AIエージェントナビ編集部
AIエージェントナビ編集部
最新のLLM(大規模言語モデル)を実務に組み込みたいものの、RAG(検索拡張生成)やファインチューニング(追加学習)の使い分けや、複雑なワークフローの実装方法に頭を悩ませていませんか。本記事では、AIエージェントの設計思想を5つのレベルに分類し、現場で即戦力となるモダンな技術スタックと評価手法を解説します。
目次
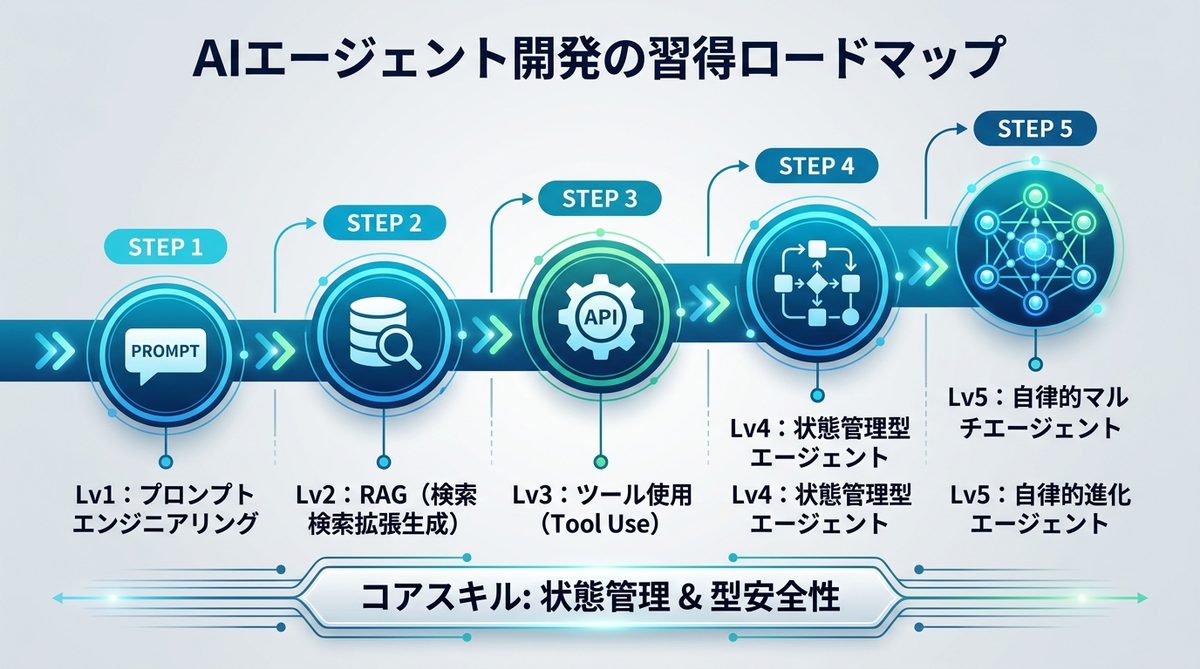
AIエージェント開発の習得ロードマップ:Lv1からLv5への5ステップ
AIエージェントの開発は、単なるプロンプト作成から、自律的に判断を行うシステムまで段階的に進化します。自身の開発プロジェクトがどの位置にあるのか、まずは以下の5つのレベルで現在地を確認しましょう。
開発レベルの定義と現在地の確認
開発の進捗は、エージェントの「自律性」と「タスクの複雑さ」で定義できます。
- Lv1:プロンプトエンジニアリング:システムプロンプトによる指示出しのみ。静的なタスクに適しています。
- Lv2:RAG(検索拡張生成):外部知識を参照するエージェント。事実ベースの回答が必要な業務に必須です。
- Lv3:ツール使用(Tool Use):API呼び出しやDB操作を行うエージェント。外部システムとの連携が可能です。
- Lv4:状態管理型エージェント:複雑なフロー制御が必要な業務(例:ワークフロー承認)を担います。
- Lv5:自律的マルチエージェント:複数の専門エージェントが協調してタスクを完遂する、高度な自動化システムです。
エンジニアが習得すべきコアスキル
上位レベルのエージェントを構築するには、単なるAPI呼び出し以上の技術が求められます。特に「状態管理(State Management)」と「型安全性(Type Safety)」は、システムの堅牢性を担保する要です。今後は、LangGraph等のフレームワークを用いた、人間が介在するループ(Human-in-the-loop)や、エージェント間のデータ受け渡しを型定義する設計力が不可欠となります。
関連記事:【2026年最新】LangGraphとは?エージェント開発を成功させる設計と実装の勘所
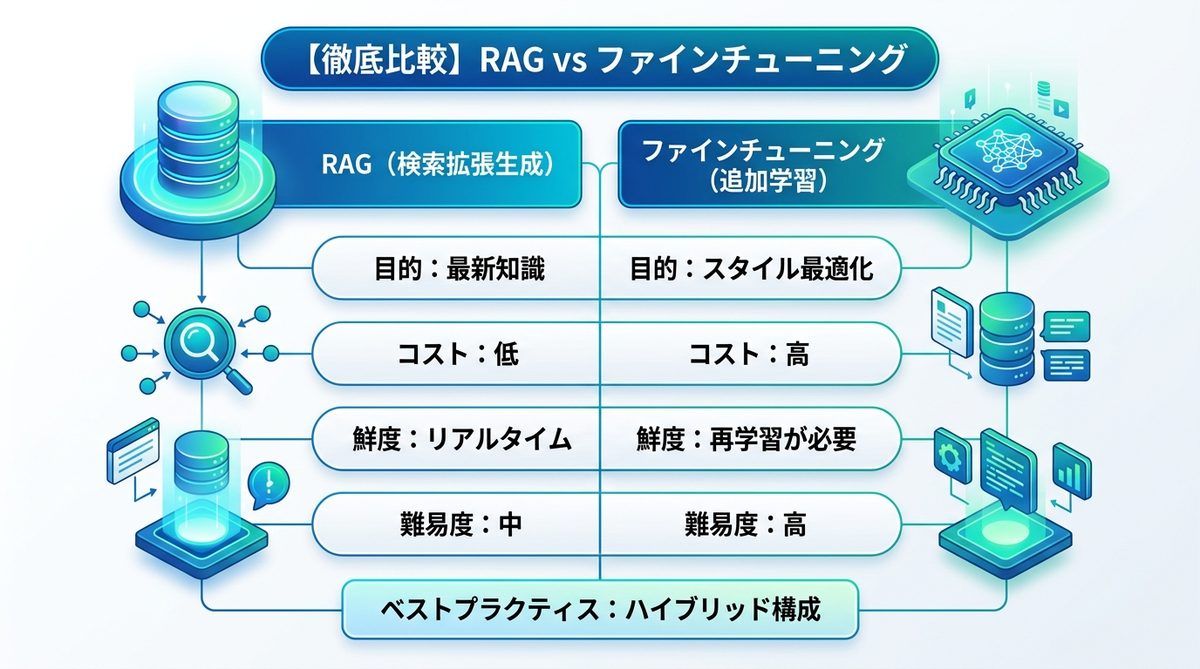
【徹底比較】RAG vs ファインチューニング|AIエージェントの知識補完戦略
AIに専門知識を持たせる際、多くのエンジニアが「ファインチューニングをすべきか」と迷いますが、まずはRAGを検討するのが定石です。
なぜ「学習」よりも「検索」が優先されるのか
RAGは、エージェントが外部DBから最新情報を取得する仕組みです。一方、ファインチューニングはモデルの「振る舞い」や「形式」を教え込むもの。以下の比較表を参考に、目的に応じて使い分けてください。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング(追加学習) |
|---|---|---|
| 主な目的 | 最新知識・事実情報の提供 | 出力スタイルの最適化・タスク特化 |
| コスト | 低(検索のみ) | 高(計算リソース・学習データ作成) |
| 情報の鮮度 | リアルタイムに反映可能 | 再学習が必要(遅い) |
| 実装難易度 | 中(ベクトルDB構築が必要) | 高(データセットの品質が鍵) |
意思決定フレームワーク|技術選定のロジック
知識の補完戦略としては、「RAGで事実を補い、ファインチューニングで口調や構造を整える」というハイブリッド構成が現代のベストプラクティスです。頻繁に情報が更新されるドキュメントを扱う場合は、迷わずRAGを選択してください。
関連記事:【実践ガイド】AIエージェント最適化のためのファインチューニング手法
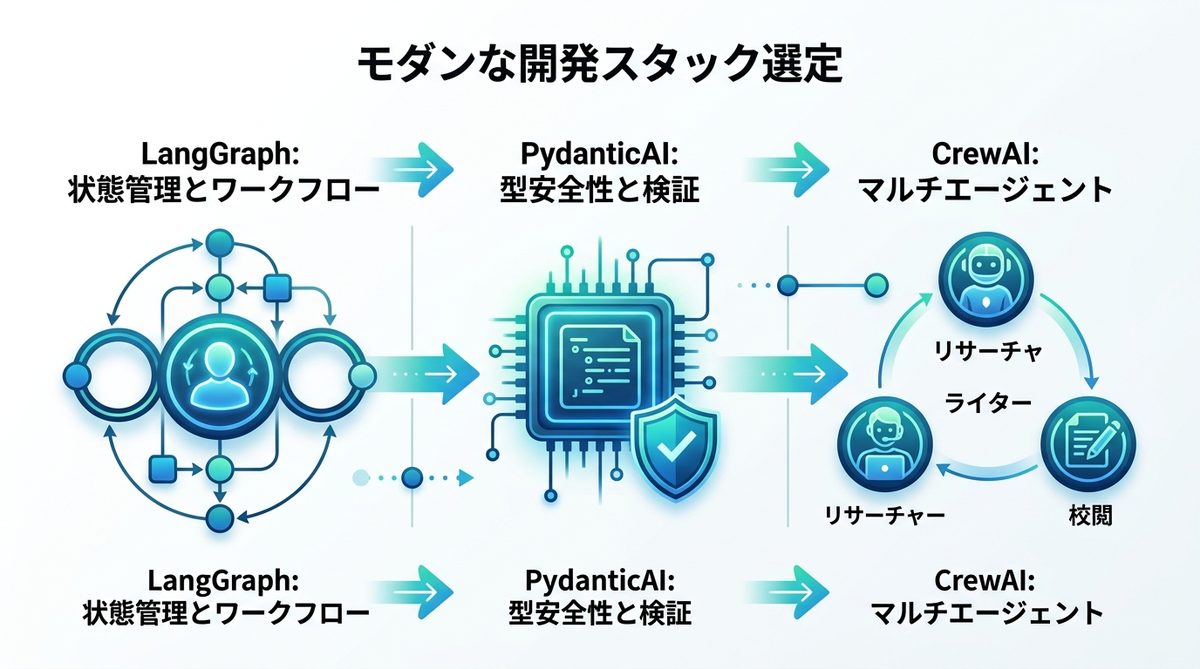
モダンな開発スタック選定|LangGraph・CrewAI・PydanticAIの活用法
複雑なタスクをこなすためには、特定のフレームワークを用いたアーキテクチャ設計が重要です。
状態管理のデファクト「LangGraph」|複雑なワークフローの実装
LangGraphは、LLMの推論プロセスをグラフ状に定義するツールです。例えば「エラーが発生した場合は人間に確認を仰ぎ、成功したら次の工程へ進む」といった条件分岐を、コードベースで厳密に管理できます。循環(ループ)構造を許容するため、試行錯誤が必要なタスクに最適です。
型安全性とマルチエージェント|PydanticAIとCrewAI
システムを堅牢にするためには、LLMからの出力を型定義することが欠かせません。
- PydanticAI:Pythonのデータ検証ライブラリ「Pydantic」を中核に据え、LLMの出力が定義したスキーマと完全に一致することを保証します。
- CrewAI:役割分担を行うエージェントチームの構築に特化しています。「リサーチャー」「ライター」「校閲」のように役割を分け、マルチエージェントで生産性を飛躍的に高めます。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
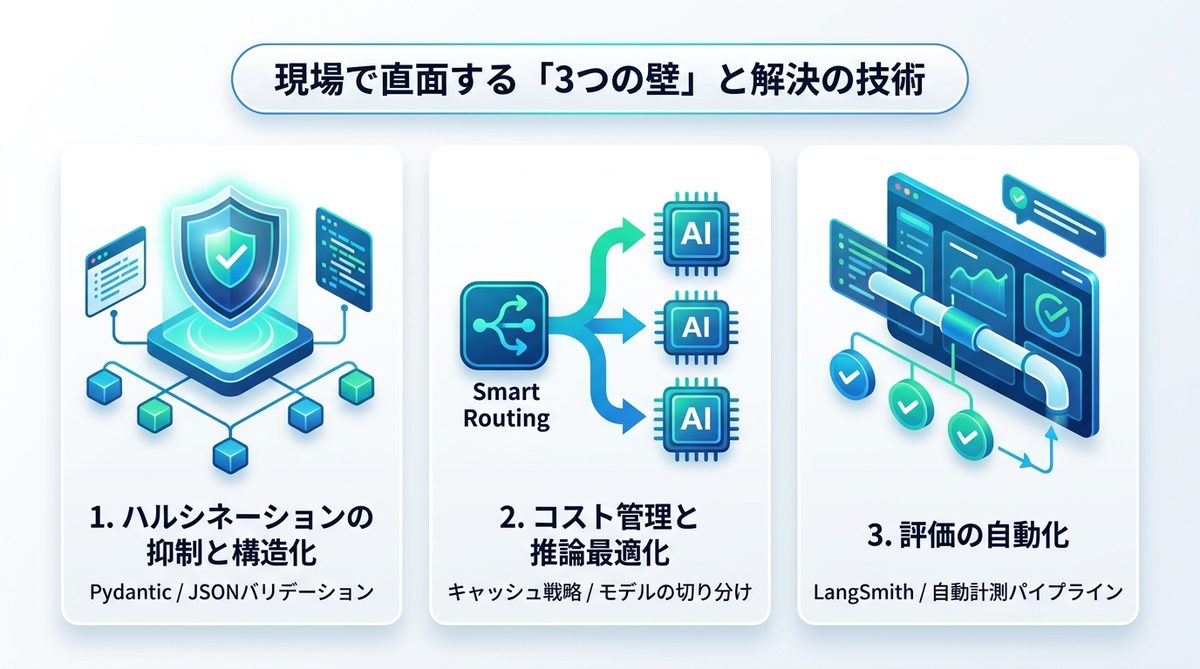
現場で直面する「3つの壁」と解決の技術
エージェント構築の実務において、避けては通れない「3つの課題」があります。
1. ハルシネーション(幻覚)の抑制と出力の構造化
エージェントが自信満々に嘘をつくことを防ぐには、バリデーション(妥当性確認)の層を設けるのが有効です。Pydanticを用いた厳格な型指定と、出力後のJSONバリデーションを必須工程に組み込みましょう。
2. コスト管理と推論最適化
トークン消費量を抑えるための「キャッシュ戦略」と「モデルの切り分け」が重要です。単純な質問には安価なモデルを、複雑な推論には高機能モデルを自動で割り振るルーティング設計を行ってください。
3. 評価(Eval)の自動化
「LLMの出力が正しいか」を人が見て判断するのには限界があります。LangSmith等の評価ツールを活用し、テストデータに対する正解率やトークン効率を自動計測するパイプラインを構築しましょう。
関連記事:【2026年最新】AIエージェント実装の5ステップ|アーキテクチャ設計から本番運用の重要指標まで
AIエージェントの性能を最大化する設計思想のまとめ
学習手法よりも重要な「アーキテクチャ設計」の視点
AIエージェントの本質は、モデルそのものの性能だけでなく、それをどう制御し、どう外部知識とつなぐかというアーキテクチャにあります。自律的な判断を行わせるなら、状態管理を疎かにしてはいけません。
実務で成果を出すための今後の学習とアウトプット戦略
今回紹介したフレームワークやツールは、まさに今、開発現場のデファクトスタンダードになりつつあります。まずは小規模なタスクからLangGraphに触れ、自分のプロジェクトに応用してみてください。今日学んだ知識をベースに、まずは設計書を書き直すことから始めましょう。
まとめ
- レベルを確認する:Lv1からLv5まで、自分のエージェントがどこを目指すか定義しましょう。
- RAGを優先する:知識補完にはコストと鮮度の面からRAGが最適です。
- 型安全性を確保する:PydanticAIを活用し、システムの予測可能性を高めましょう。
- ワークフローを可視化する:LangGraphで複雑な処理を構造化しましょう。
- 評価環境を構築する:LangSmithで自動評価を行い、改善サイクルを回しましょう。
今すぐモダンなフレームワークをインストールし、堅牢なAIエージェント開発を始めましょう。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


