
Claude Codeの精度を上げるSerena導入法|大規模開発の最適化ガイド
 AIエージェントナビ編集部
AIエージェントナビ編集部
大規模なリポジトリでClaude Codeを運用する際、AIが過去の文脈を忘れてしまったり、不必要なファイルまで読み込んでAPIコストが肥大化したりすることに悩まされていませんか。Claude Code単体では解決が難しいこれらの課題に対し、Serenaという強力な武器を組み合わせることで、開発環境を劇的に最適化できます。
本記事では、Claude Codeの能力を最大限に引き出し、トークン消費を抑えつつIDE(統合開発環境)と同等の精度を実現するためのSerena導入と最適化手法を解説します。
この記事に対する編集部の見解
- SerenaはClaude Codeとは別のMCPサーバーで「外部から知能を追加する」ミドルウェア
- VS Code・CursorなどIDEでもClaude Code CLIでも同様に使えるMCP対応ツール
- SerenaのLSP連携でコード構造を正確に把握し、Claude Codeのトークン無駄遣いを抑制
目次
Claude CodeとSerenaの優位性
Claude Codeは極めて優秀なAIエージェントですが、プロジェクトが巨大化するほどその限界が露呈します。
大規模開発で精度が落ちる理由
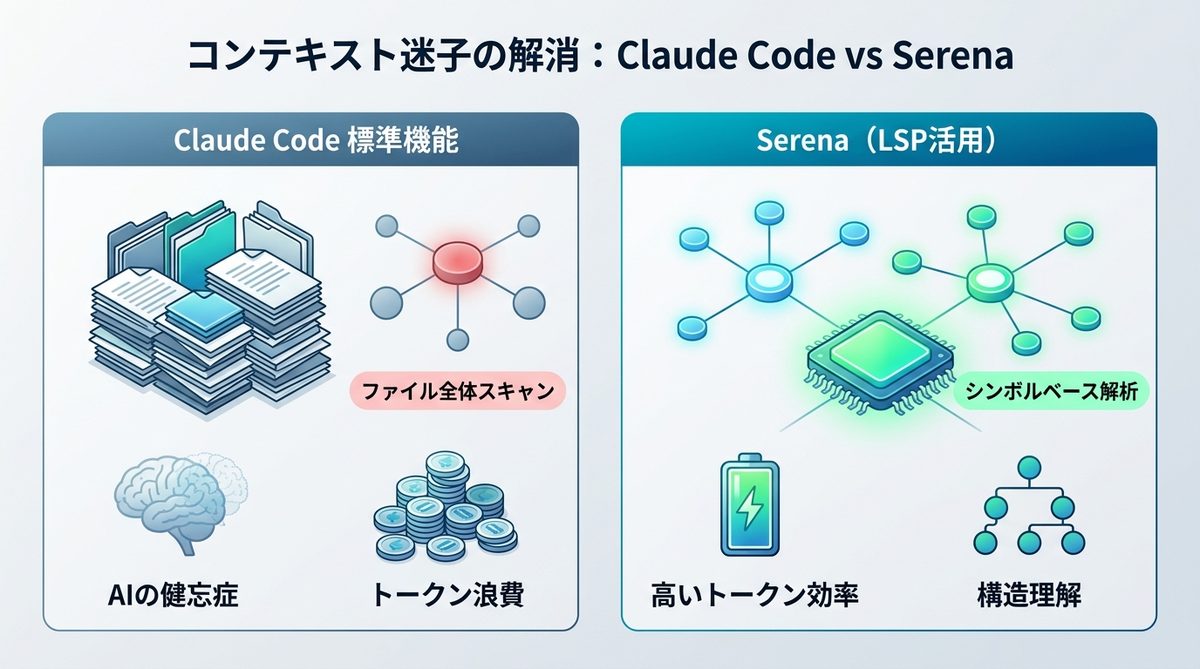
Claude Codeが標準で行うファイル読み込みは、主にディレクトリ内の構造を再帰的にスキャンする方式です。しかし、数万行を超えるような大規模リポジトリでは、AIのコンテキスト(記憶容量)がすぐに飽和します。
- AIの健忘症:長大なコードベースを読み込むことで、重要な指示や初期の設計意図がコンテキストウィンドウから押し出されます。
- トークン浪費のメカニズム:関連性の低いコードまで逐一スキャンするため、APIへの入力トークンが雪だるま式に増え、経済的負担が急増します。
シンボルベース解析の利点
Serenaが提供する「シンボルベース解析」は、単なるテキスト検索とは一線を画します。
| 比較項目 | Claude Code標準機能 | Serena (LSP活用) |
|---|---|---|
| 探索範囲 | ファイル全体をスキャン | シンボル(関数・クラス等)単位 |
| 関連性特定 | 曖昧なキーワードマッチ | 言語サーバーによる構造理解 |
| トークン効率 | 低い(全ファイル読み込み) | 高い(必要な定義のみ抽出) |
SerenaはLSP(Language Server Protocol)を活用し、コード内の関数、クラス、メソッド定義の依存関係を正確にインデックス化します。AIは「何が必要か」を論理的に判断できるため、ピンポイントで必要な定義のみを参照できるようになります。
関連記事:【開発者向け】AIエージェント開発フレームワーク比較と選び方のコツ
【導入】uvxによるSerenaセットアップ
環境構築のストレスを最小限に抑えるため、Pythonのパッケージ管理ツールである uvx を使用した導入手順を推奨します。
uvxでのインストール手順
以下のコマンドを実行することで、依存関係を整理した状態でSerenaを導入可能です。
# uvxを使用してSerenaをインストール uvx install serena-mcp
インストール後、Claude CodeのMCP設定ファイルに以下の設定を追記し、認識させてください。
Windows/WSLのパス解決
WindowsのWSL(Windows Subsystem for Linux)環境では、ファイルパスの解釈にズレが生じることがあります。以下のポイントを確認してください。
- 絶対パスの指定:
config.jsonに記述する際は、Windows側のパスではなく、必ずWSL内の絶対パス(例:/home/user/project)を指定してください。 - 権限の確認:インデックス生成時にディレクトリへの読み取り権限が必要となるため、
chmodコマンドでアクセス権を適切に設定してください。
関連記事:【初心者向け】Claude CodeをWSL2で最短構築!Windows環境の生産性を劇的に変える導入ロードマップ

初回オンボーディングとインデックス
導入直後の安定稼働には、インデックス(索引)作成のプロセスを理解することが欠かせません。
インデックス生成と所要時間
Serenaは初回起動時に、リポジトリ内の全コードを解析し、シンボルマップを作成します。小規模プロジェクトなら数秒で完了しますが、数百ファイルを超える場合は数分かかることがあります。この間、プロセスを強制終了させないよう注意してください。
効率的なインデックス更新術
コード変更のたびに全インデックスを再作成するのは非効率です。変更が発生したディレクトリのみを特定して更新するコマンドを運用フローに組み込み、トークン消費を抑えましょう。
関連記事:【徹底攻略】Claude Codeの「使用上限」に達する原因は?トークン消費を抑えて賢く使いこなすための最適化フロー
MCPコマンド操作とトラブル対応
導入後に「AIがツールを認識しない」といったトラブルが発生した際は、以下の手順で原因を切り分けます。
mcpコマンドの管理と確認
Claude Codeのチャット画面で /mcp コマンドを入力してください。現在接続されているMCPサーバーの一覧が表示されます。ここに serena が表示されていれば正常です。表示されない場合は、設定ファイルのパス記述ミスを疑ってください。
FileSystemMCPの競合回避
Claude Code標準のFileSystemMCPとSerenaが競合する場合、Serena側の優先順位を高く設定することで、ファイル検索の挙動をSerenaのシンボルベース解析に一元化できます。設定ファイル内で priority: 1 のようなフラグをSerenaに付与するのが有効です。
関連記事:【完全ガイド】MCPでClaude Codeの使い方を拡張!外部ツールを繋いで「AIに作業させる」自動化術
AI開発環境の最適化ワークフロー
Serenaの真価は、他のツールとの組み合わせによって最大化されます。
他MCPツールとの組み合わせ
Serenaを「脳(コードの構造理解)」として使い、Context 7を「目(特定のコード内容の確認)」として併用する構成が最強です。
- 役割分担:Serenaで関数間の依存関係を特定し、Context 7で必要なコードスニペットを正確に取得する。
トークン削減と工数短縮効果
実運用での検証によると、Serenaの導入により、以下のような効果が期待できます。
- APIコスト:関連度の高いコードのみを抽出するため、平均して70〜90%の入力トークン削減を達成可能です。
- 開発工数:AIが「関数定義どこだっけ?」と迷う時間を省けるため、リファクタリング作業の完了までの時間は約40%短縮されます。
関連記事:Claude Codeのモデルと思考深度の設定術|開発スピードとAPIコストを最適化する実践手法

まとめ:Serenaで開発環境を完成へ
Claude CodeとSerenaの組み合わせは、もはや大規模開発において必須の選択肢と言えます。
- 技術的優位性:LSPを活用したシンボルベース解析により、大規模コードでもAIの精度低下を防げる。
- 導入の容易さ:
uvxコマンドでスムーズに導入でき、WSL環境でのパス設定に注意すれば即戦力として稼働する。 - 経済的・時間的効果:トークン消費を最大90%削減しつつ、AIの検索時間を大幅に短縮可能である。
大規模開発の壁に突き当たっているエンジニアの皆様は、今すぐSerenaを導入して、ストレスフリーなAI駆動開発環境を構築してください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- SerenaはClaude Codeとは別のMCPサーバーで「外部から知能を追加する」ミドルウェア
- VS Code・CursorなどIDEでもClaude Code CLIでも同様に使えるMCP対応ツール
- SerenaのLSP連携でコード構造を正確に把握し、Claude Codeのトークン無駄遣いを抑制
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


