
OpenClawベストプラクティス:安全な運用とコスト最適化の5項目
 AIエージェントナビ編集部
AIエージェントナビ編集部
OpenClawを導入したものの、「セキュリティ設定に不安がある」「気がつくとAPIコストが膨れ上がっている」といった課題を抱えていませんか?v2026.4.15の刷新により、OpenClawは高度なエージェント連携が可能になった一方で、運用ルールを曖昧にすると予期せぬリスクを招く可能性があります。
本記事では、非エンジニアの経営者やマネージャーでも安心して運用を開始できるよう、セキュリティ診断からコスト制御までを網羅した「OpenClaw運用ベストプラクティス」を解説します。
この記事に対する編集部の見解
- OpenClawはCVSS 8.8の重大脆弱性が発見され13万件超の露出インスタンスが確認されている
- NVIDIAのNemoClawがセキュリティを補強するが本体の根本問題を解決したわけではない
- 安全な利用にはNemoClaw導入+ローカル限定+Human-in-the-Loopの3点セットが最低条件になる
openclaw doctorによる診断
OpenClawを「実験用のおもちゃ」から「信頼できる社内インフラ」へと昇格させるためには、まず現在の設定が安全かを診断する必要があります。
監査の必要性
v2026.4.15以降、OpenClawは外部サービスとの接続性が飛躍的に向上しました。しかし、設定が不適切な状態では、意図せず外部から社内リソースへアクセスされるリスクがあります。公式ツールであるopenclaw doctorを活用した監査は、運用を開始する前の必須プロセスです。
診断手順とチェックリスト
以下のコマンドを実行し、結果を診断します。
openclaw doctor --security
診断結果が出力されたら、以下の5つのチェックリストを照らし合わせてください。
- APIキー露出: 環境変数以外の場所にキーがハードコーディングされていないか
- サンドボックス:
sandboxモードが有効化されているか - ペアリング:
dmPolicy: pairingが適切な権限に制限されているか - ネットワーク: 外部からのアクセス経路が限定されているか
- ログ管理: 不審なクエリが記録されていないか
サンドボックスの強制設定
サンドボックス(隔離された実行環境)を強制することで、万が一エージェントが不正なコードを実行しようとしても、ホストPCや社内ネットワークに影響が及ばないよう防護壁を築けます。
関連記事:【2026年最新】OpenClawとは?AIエージェントの仕組みと、安全に業務導入する「NemoClaw」活用ガイド

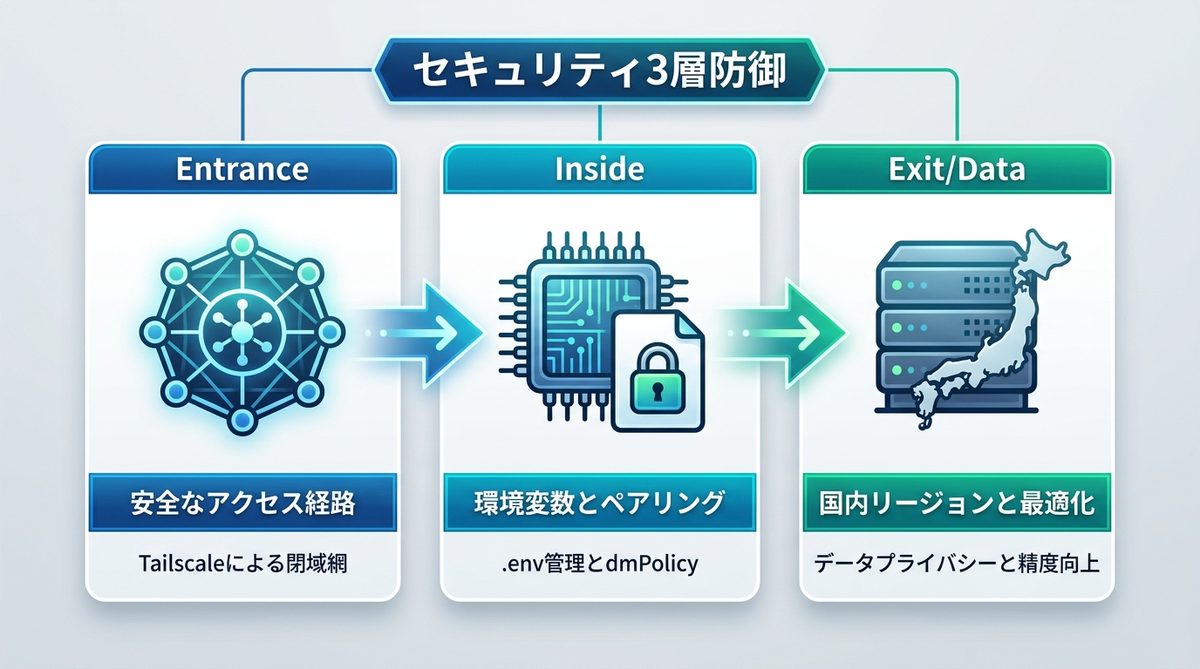
セキュリティ3層防御の設定
OpenClawを社内運用する際は、入口(アクセス経路)と中身(環境変数)、出口(権限管理)の3層で防御を固めます。
APIキーとペアリング実装
APIキーを直接プログラムに書くのは厳禁です。.envファイルを用いた環境変数管理を徹底しましょう。また、dmPolicy: pairing(ペアリングポリシー)を活用し、許可されたデバイス間でのみ対話が成立するように制限をかけます。
Tailscaleによる経路確保
OpenClawをインターネットに公開するのは推奨されません。TailscaleのようなVPN(仮想専用線)技術を活用し、社内ネットワークからのみOpenClawへ接続できる「閉域網」を構築してください。
データリージョンと最適化
日本の法人利用では、データプライバシーが重要です。リージョン設定を日本国内に固定し、プロンプトには日本語特有の文脈を理解させるための「コンテキスト(記憶容量)注入」を行うことで、回答精度と安全性を両立させます。
関連記事:【2026年最新】OpenClaw導入設定マニュアル|初期構築からチャット連携・エラー解決まで完全網羅
MCPによる安全な連携
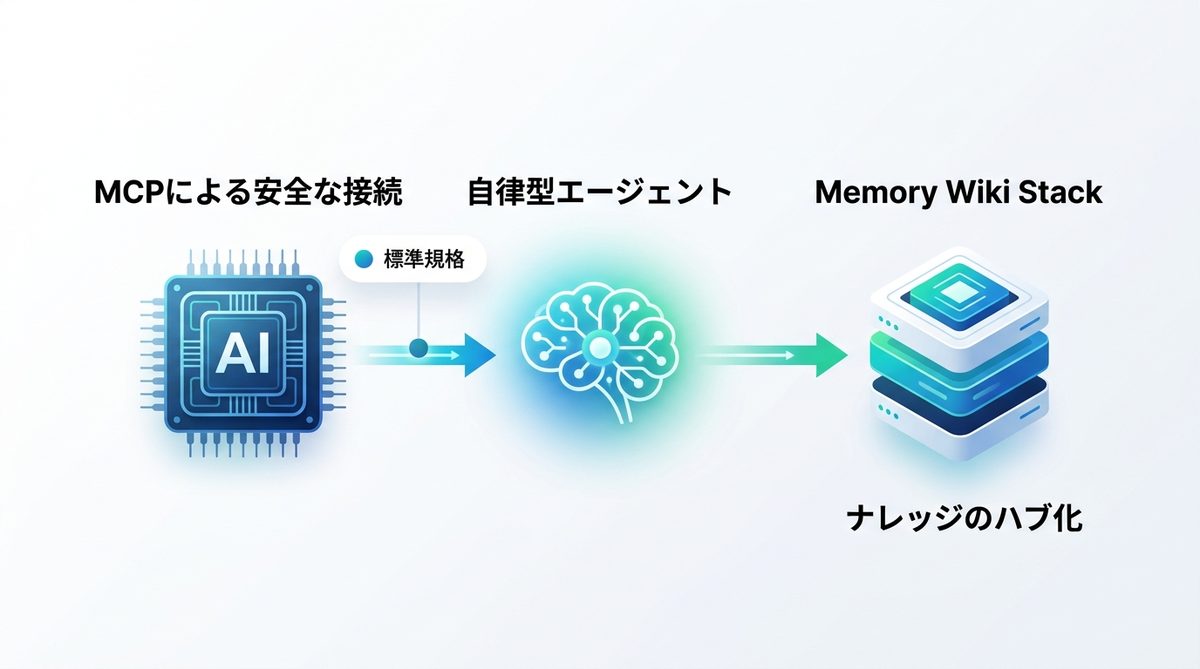
従来のプラグイン方式はセキュリティ上の脆弱性が課題でしたが、標準規格であるMCP(モデルコンテキストプロトコル)の導入により、安全なデータ共有が実現しました。
MCPによるエージェント構成
MCPは、エージェントが外部ツールにアクセスするための「共通言語」です。これを通すことで、エージェントは必要な情報のみにアクセス可能となり、権限が過剰になるのを防ぎます。
Memory Wikiのハブ化
Memory Wiki Stack(ナレッジ管理環境)を導入すると、社内規程や過去のトラブル対応策をエージェントが参照できるようになります。これにより、「属人化」していたノウハウがチームの共有財産へと変わります。
関連記事:【2026年最新】AIエージェントおすすめ10選|MCP対応で実現する業務自動化の実装ロードマップ
モデルルーティングの運用
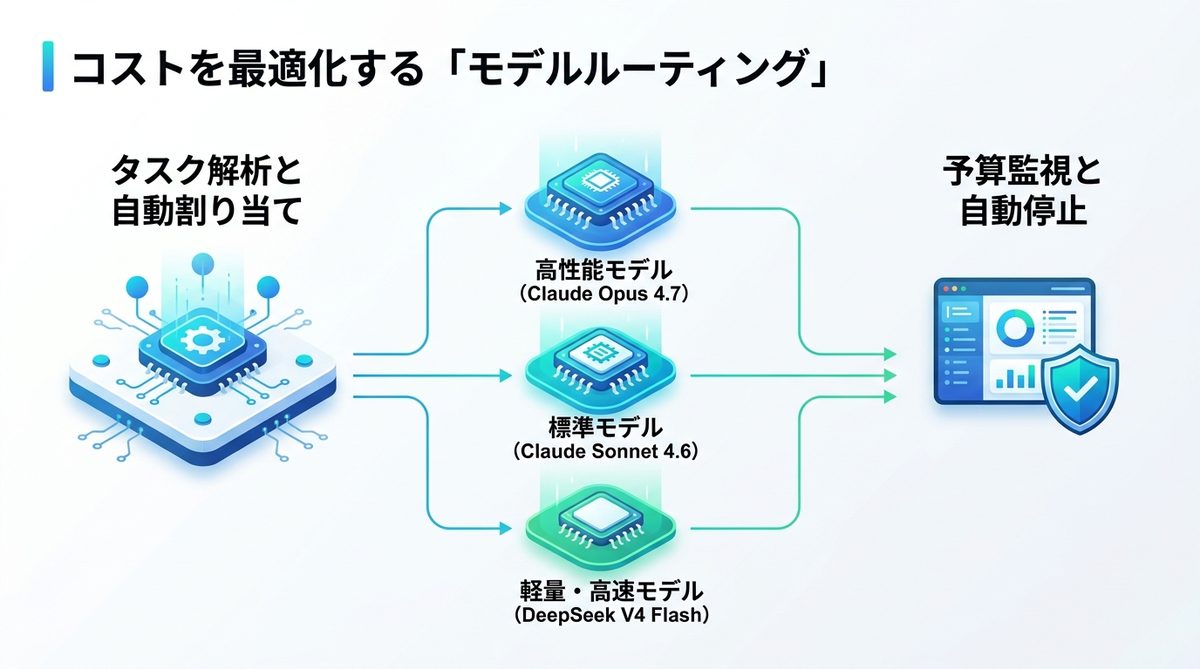
AIエージェントの運用コストは、モデルの使い分けで大きく削減可能です。以下の表を参考に、重要度に応じてモデルを使い分けましょう。
モデルの動的切り替え設定
単純なタスクには安価なモデルを、複雑な論理構築には高性能なモデルを自動で割り当てます。
| モデル区分 | 推奨モデル | 特徴 |
|---|---|---|
| 高性能 | Claude Opus 4.7 | 難解な解析・設計用 |
| 標準 | Claude Sonnet 4.6 | バランス型 |
| 軽量・高速 | DeepSeek V4 Flash | 定型処理・低コスト |
API利用料の監視体制
APIの利用状況を定期的に監視し、予算の上限に達した場合には自動的にエージェントの活動を一時停止させるルールを設定します。これにより、予測不能な高額請求を未然に防ぎます。
関連記事:DeepSeek V4 vs Claude Opus 4.8比較|コスト最大1700倍のハイブリッド運用術
セキュリティ強化用設定雛形
以下は、セキュリティを重視したconfig.yamlのテンプレートです。ご自身の環境に合わせて値を変更して使用してください。
security:
sandbox: enabled
dmPolicy: pairing
restricted_domains: ["internal.company.com"]
max_token_budget: 1000000
logging:
level: "info"
audit: true
- 活用メリット: この雛形をベースにすることで、初期設定ミスを最小限に抑えられます。
- チーム共有の注意点: 設定ファイルにAPIキーそのものを含めないよう、チームメンバー全員に徹底させてください。
関連記事:【徹底比較】Claude Code vs OpenClaw:自律型AIエージェントの選び方
まとめ|社内インフラへ
OpenClawを安全かつ経済的に運用するためのポイントを振り返ります。
- 診断の儀式:
openclaw doctorを使い、セキュリティの現状を可視化する。 - 3層防御: APIキーの環境変数化、VPNによる接続制限、サンドボックスの強制を行う。
- 標準化: MCPを利用し、安全なデータ連携環境を構築する。
- コスト管理: タスクの重要度に応じたモデルルーティングで最適化を図る。
- 雛形の活用: 提供した
config.yamlをベースにセキュリティポリシーを統一する。
OpenClawは正しく設定すれば、強力なビジネスパートナーとなります。まずは今日の業務で、セキュリティ診断から始めてみてください。
AIエージェントナビ編集部の見解
AIエージェントナビでは、各記事のテーマについて編集長が「実際どうなの?」という素朴な疑問を「Nav」と名付けたAIエージェントにぶつけています。エンジニアではなく、経営者・ビジネス視点からの率直な見解をお届けします。
編集長の率直な感想
編集長
Nav
編集長
Nav
編集長
Nav
編集部のまとめ
- OpenClawはCVSS 8.8の重大脆弱性が発見され13万件超の露出インスタンスが確認されている
- NVIDIAのNemoClawがセキュリティを補強するが本体の根本問題を解決したわけではない
- 安全な利用にはNemoClaw導入+ローカル限定+Human-in-the-Loopの3点セットが最低条件になる


