Perplexityの回答が遅い3つの原因|爆速化する設定手順
 AIエージェントナビ編集部
AIエージェントナビ編集部
「以前よりも回答が返ってくるのが遅くなった」と感じていませんか?
ビジネスの現場でPerplexityを活用している経営者やコンサルタントの間で、近頃そんな声が聞かれます。しかし、これはPerplexityが故障したわけでも、ネットワーク環境が悪化したわけでもありません。答えはシンプルです。AIが「賢くなりすぎた」せいで、回答に至るまでの「思考プロセス」が深化したからなのです。
本記事では、2026年4月時点におけるPerplexityの回答遅延の正体と、業務スピードを落とさないためのモデル設定・運用術を解説します。
Perplexityが遅い3つの原因
Perplexityの回答が待たされる理由は、現在のAIが提供する「推論の深さ」と密接に関わっています。まずは、なぜあなたのPCの前でAIが考え込んでいるのか、その3つの主要因を整理しましょう。
Model Councilの待機時間
2026年現在のPerplexityには「Model Council(モデル評議会)」という強力な機能が搭載されています。これは、ひとつの質問に対して複数のAIモデルを並列で走らせ、それぞれの回答を検証・比較した上で最適な答えを提示する仕組みです。この「複数モデルによる相互検証」が終了するまで回答が表示されないため、その分だけ物理的な待機時間が長くなっています。
Deep Researchの深掘り
「Deep Research(詳細調査)」機能は、一度の検索で終わらず、AIが自分で検索戦略を立て、足りない情報を自律的に追加調査するプロセスを繰り返します。この「AI自身の反復思考」が機能している場合、回答完了まで数分を要することもあります。これはPCの故障ではなく、極めて高度な調査が行われている証拠です。
スレッドのコンテキスト過多
AIツールを長時間同じスレッド(会話履歴)で使い続けていませんか?AIは会話が続くほど、過去の文脈を全て「コンテキスト(記憶容量)」として読み込みます。このトークン(AIが処理するテキストの単位)の蓄積がメモリの大きな負担となり、回答生成のボトルネックを生んでいるのです。
関連記事:【生成AIの頭脳】LLMとは?その仕組みと進化の最前線
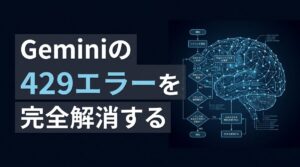
モデル別応答速度の比較
Perplexityには用途に応じて最適な「思考エンジン」が存在します。以下の表を参考に、目的に応じてモデルを切り替えましょう。
| モデル/機能 | 応答速度の目安 | 推奨シーン |
|---|---|---|
| Sonar | 2〜3秒 | ニュース確認、事実の即時検索 |
| GPT-5.2 / Claude 4.6 Opus | 15〜30秒 | 論理的考察、企画案作成、コード記述 |
| Model Council | 30〜60秒 | 複数視点での比較検討、意思決定サポート |
| Deep Research | 3分〜5分 | 市場調査、競合分析、長期レポート作成 |
Sonarの活用
スピードが最優先される日常業務では「Sonar」一択です。最新モデルのSonarは、回答速度が極めて高速でありながら、検索の正確性も担保されています。メールの文面作成や、ちょっとした事実確認であれば、このモデルで十分なパフォーマンスを発揮します。
GPT-5.2/Claude 4.6 Opusの使い所
複雑な論理推論や、構造化された情報が必要な場合は、高推論モデルであるGPT-5.2やClaude 4.6 Opusを選択してください。これらは、AIが「考えを深める時間」を確保することで、単なる検索以上の洞察を提供します。
調査機能の限界と時間
市場調査や専門的なリサーチなど、時間をかけてでも「精度の高い正解」が必要なタスクには、これらを使用します。逆に、即レスが求められるチャットツール内での利用には不向きです。タスクの性質に合わせて、あえて「時間をかけるべき仕事」と「速さを優先すべき仕事」を区別しましょう。
関連記事:【2026年最新】生成AIとは何か?AIエージェント時代に乗り遅れないためのビジネス活用ガイド
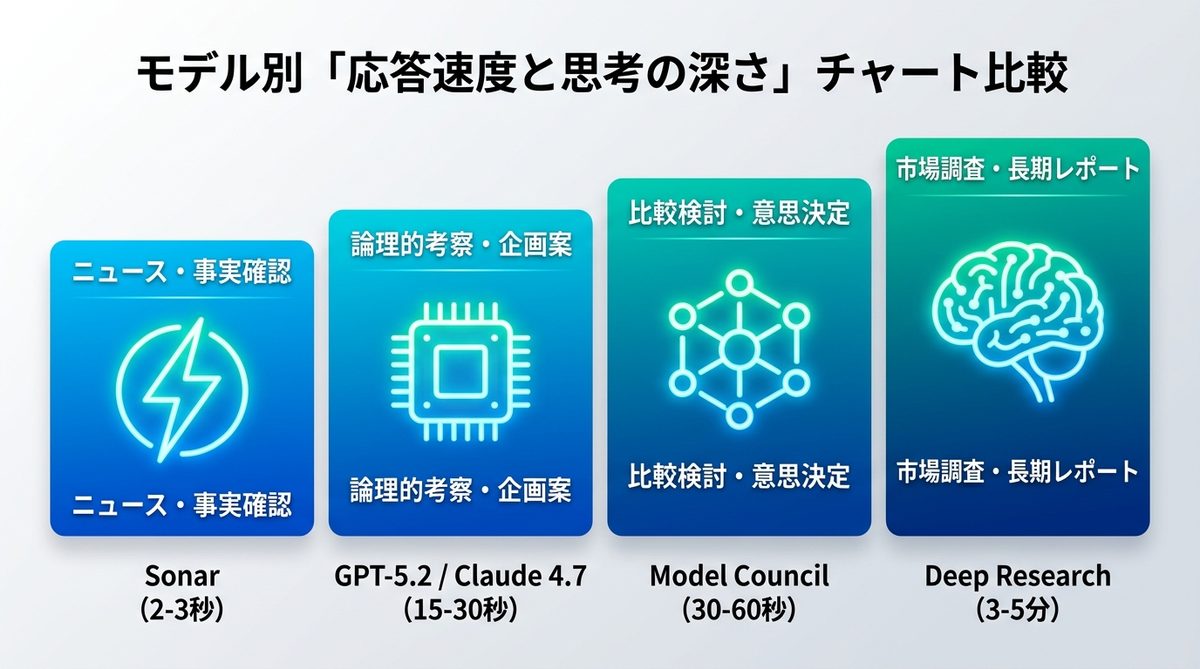
回答を爆速化する設定手順
無駄な待機時間を減らすために、今すぐできる2つのカスタマイズを紹介します。
推論トグルのオフ設定
Perplexityの検索欄にある「Pro Search」を起動した際、AIの推論を強化する「Reasoning(推論)トグル」がオンになっていないか確認してください。これをオフにすることで、AIは深掘りを最小限にし、即時回答へとシフトします。
- 検索入力欄の下にある「Pro Search」設定アイコンをクリック。
- 「Reasoning(推論)」のトグルをオフにする。
- これにより、複雑な推論をスキップして爆速で回答を生成します。
記憶リセットの習慣化
スレッドが長くなりすぎると、AIは過去の会話を全てなぞるため重くなります。「回答が重いな」と感じたら、迷わず「新しいスレッド(New Thread)」を作成しましょう。文脈をリセットすることでメモリ負担が軽くなり、新品のAIのようにキビキビと反応を返すようになります。
関連記事:【図解】Raycastの使い方がわかる!標準ランチャーを超えた「AIコパイロット」の実力
タイパ最大化の運用ルール
AIの遅さは、実は「あなたの仕事の質」を向上させるチャンスでもあります。
シーン別フローチャート
業務効率を最大化するためには、以下のフローチャートを意識してください。
- 30秒以内に結果がほしい → Sonarへ切り替える
- 15分後の会議で結論が必要 → GPT-5.2を選択し、思考させる
- 明日提出のレポートを仕上げる → Deep Researchを活用し、待機中に別のタスクをこなす
速さと質のコスト管理
AIの回答待ち時間を「コスト」と捉えるのは正しいですが、AIが代わりに熟考してくれていると考えれば、それは「思考の外注」という投資になります。すべてに速さを求めるのではなく、「ここはAIの脳力をフルに使わせる」という戦略的な使い分けが、結果としてあなたのタイパ(タイムパフォーマンス)を最大化します。
関連記事:Claude Opus 4.8のベンチマーク解説|xhigh effortで工数はどう変わるのか
まとめ
Perplexityの回答が遅いのは、AIが故障しているのではなく、あなたの指示に対して「より深く、より高精度に」考えようとしている結果です。最後に重要なポイントをまとめました。
- 遅い原因の特定:Model CouncilやDeep Researchによる「深い思考」や「コンテキスト過多」が主な要因です。
- モデルの使い分け:即答なら「Sonar」、深い思考なら「GPT-5.2 / Claude 4.6 Opus」と明確に使い分けましょう。
- 高速化テクニック:Pro Searchの推論トグルをオフにし、長くなったスレッドはこまめにリセットしましょう。
- 経営視点の運用:回答待ち時間は「思考のコスト」と捉え、タスクの緊急度に応じてAIのエンジンを切り替えることがタイパ向上の鍵です。
AIの「遅さ」は、AIが進化している証拠です。ぜひ今すぐ右下のモデル選択を見直し、あなたの業務に最適な「思考速度」にカスタマイズしてみてください。