
「unknown model architecture: 'gemma4'」の原因と対処
 AIエージェントナビ編集部
AIエージェントナビ編集部
ローカルLLM(大規模言語モデル)を自身のPC環境で構築・運用する際、新しいモデルを読み込もうとして突如表示されるエラーに頭を抱えてはいませんか。特に、2026年4月にリリースされた最新モデル「gemma4」を読み込もうとした際、以下のようなエラーコードを目にした方は非常に多いはずです。
llama_model_load: error loading model: error loading model architecture: unknown model architecture: 'gemma4'
llama_model_load_from_file_impl: failed to load model
この無機質な文字列が表示されると、一見「ダウンロードしたモデルファイルが壊れているのではないか」「ハードウェアのスペックが足りないのではないか」と不安になるかもしれません。しかし、安心してください。このエラーはモデルの破損でもスペック不足でもなく、実行環境側が「gemma4」という最新の設計図をまだ知らないことが原因で発生する、非常に典型的なトラブルです。
本記事では、AIエージェントの専門メディアとしての視点から、このエラーの根本原因を紐解き、お使いのツール(Ollama、LM Studio、llama.cpp等)ごとの解決手順を詳しく解説します。
gemma4エラーの正体とは?
結論から述べると、このエラーは「モデルが壊れた」のではなく、「実行環境(ランタイム)が内蔵するエンジンが、gemma4の新アーキテクチャに対応していない」というサインです。
ローカルLLMを動かすためのツールの多くは、バックエンドで「llama.cpp」という実行エンジンを採用しています。このエンジンは、モデルファイル(GGUF形式など)の中に記述されている「アーキテクチャ名」を読み取り、それに応じた計算処理(テンソル演算の順序など)を組み立てます。
エラー文にある「unknown model architecture: 'gemma4'」とは、まさに文字通り「『gemma4』という名前の設計図は、私の知っているリスト(辞書)には載っていません」とシステムが報告している状態です。設計図が理解できない以上、無理に動かせば異常な出力やシステムクラッシュを招く恐れがあるため、安全装置としてロードを強制的に中止しているのです。
この問題は、実行環境を最新版にアップデートし、内蔵のllama.cppをgemma4対応のものに更新することで解決します。
関連記事:Gemma 4とは?ビジネス導入ガイド|モデル選定・環境構築の全手順
エラーが発生する原因
なぜ、これまで問題なく動いていたツールが急にエラーを吐くようになるのでしょうか。その理由は、LLMの進化スピードとランタイムの更新ラグにあります。
gemma4は2026年4月にリリースされた、非常に新しいアーキテクチャを採用したモデルです。それまでのモデル(gemma2やllama3など)とは異なる新しいパラメータ構造や、効率的な推論を実現するための特殊なレイヤー構造が導入されています。
- アーキテクチャの進化: gemma4は次世代の処理構造を持っており、従来のエンジンでは解釈できない。
- ランタイムの不整合: お使いのOllamaやLM Studioのバージョンが2026年4月以前、あるいはリリース直後の古いバージョンのままである場合、内部の「辞書」にgemma4の情報が存在しない。
- ロードの中止: 未知のアーキテクチャを強引に処理しようとして計算ミスを起こすよりも、エラーを出すことでデータの整合性とシステムの安定性を守っている。
つまり、このエラーはツールが正常に「自分にはまだ荷が重い(理解できない)」と自己診断した結果であり、ユーザー側で行うべきは「ツールの知能(バージョン)をアップデートしてあげること」に集約されます。
関連記事:Gemma 4 12BをOllamaで動かす|PC完結の会議分析と機密資料の解析術
pull時の412エラーとの違い
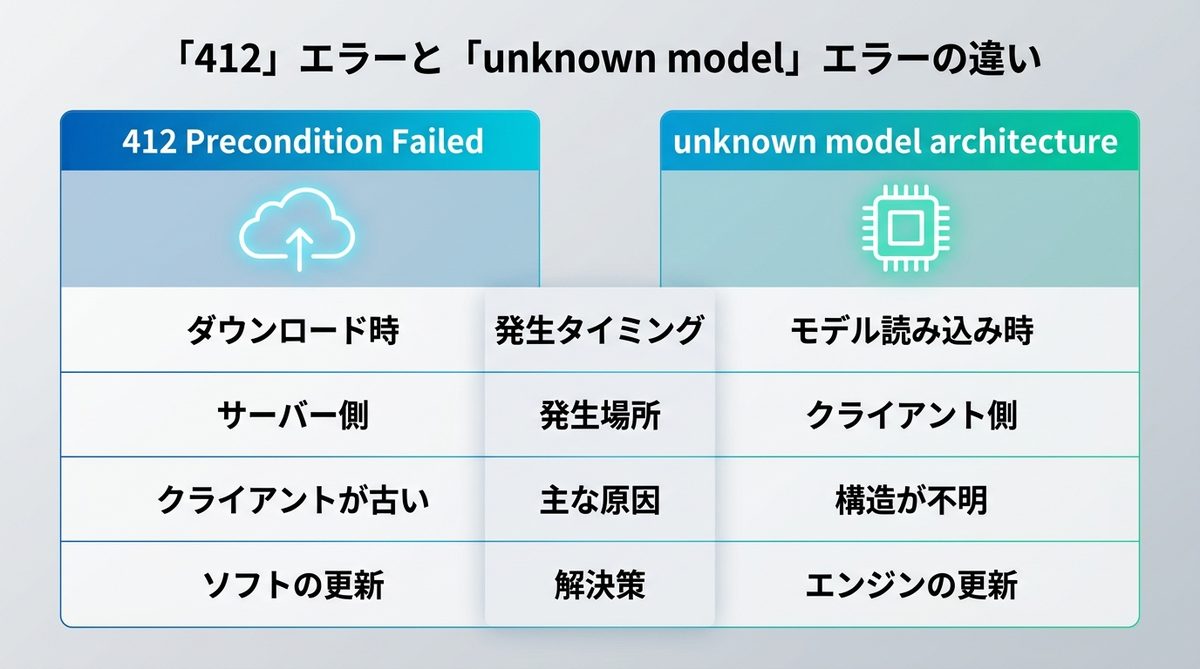
このトラブルと非常によく似たケースとして、モデルをダウンロード(pull)しようとした際に発生する「412 Precondition Failed」エラーがあります。どちらも「最新モデルが動かない」という文脈で語られますが、発生箇所と原因が明確に異なります。
| 比較項目 | 412 Precondition Failed | unknown model architecture |
|---|---|---|
| 発生タイミング | ollama pull などのダウンロード時 |
モデル読み込み(ロード)時 |
| 発生場所 | サーバー側(通信時) | クライアント側(実行環境内) |
| 主な原因 | サーバーが「お使いのクライアントは古すぎるので配信できません」と拒否している | 実行エンジンがモデルの中身を見て「何だこの構造は?」と困惑している |
| 主な解決策 | クライアントソフトの更新 | 内部エンジン(llama.cpp)を含むソフトの更新 |
どちらのエラーも「ツールの更新」が必要であるという結論は同じですが、特にHuggingFaceやunsloth等から「自作・有志作成のGGUFファイル」を直接インポートして使おうとする中級者以上のユーザーは、後者の「unknown architecture」に遭遇する確率が高くなります。
なお、ダウンロード時の412エラーについての詳細は、こちらの関連記事で解説しています。
ツール別の解決手順
お使いの環境に合わせて、以下の手順でランタイムの更新を行ってください。多くの場合、5分程度の作業でエラーは解消されます。
Ollamaの解決策
Ollamaは内部に最適化されたllama.cppを同梱しています。以下の手順で最新版への整合性を確保してください。
- バージョン確認: ターミナル(またはコマンドプロンプト)で
ollama --versionを実行し、現在のバージョンを確認します。 - 公式サイトからの更新: Ollamaの公式サイト(ollama.com)にアクセスし、最新のインストーラーをダウンロードして上書きインストールを実行します。macOSの場合はアプリを再起動するだけで更新通知が出ることもあります。
- 公式モデルの利用: 自作のModelfileや外部から持ってきたGGUFでエラーが出る場合、まずは
ollama run gemma4(またはollama pull gemma4)を実行し、Ollama公式が管理・最適化しているモデルで動作するかを確認してください。これが最も確実な解決策です。
LM Studioの解決策
GUIが洗練されているLM Studioでも、内部の推論エンジンを更新する必要があります。
- 内蔵アップデータの実行: アプリを起動し、設定(Settings)メニューや右下の「Check for Updates」から、本体を最新バージョンへ更新します。
- ランタイムの自動更新: LM Studioをアップデートすると、内蔵されている推論エンジン(llama.cpp runtime)も同時にgemma4対応のものへ置き換わります。
- モデルの再読み込み: 更新後、一度ロードに失敗したモデルを「Eject」して再度読み込み直してください。
llama.cppの解決策
ソースからビルドして利用しているパワーユーザーの場合は、最新のソースコードを取り込んで再ビルドする必要があります。
- ソースの取得: gitリポジトリで
git pull origin masterを実行し、gemma4のアーキテクチャ定義が追加された最新のコードを取得します。 - 再ビルド:
cmake -B buildcmake --build build --config Release
(※環境に応じたビルドオプションを適宜追加してください)
- バイナリの確認: 新しく生成された
./build/bin/llama-cli(または旧main)を使用して、モデルをロードできるか確認します。

直らない時の対処法
ツールを最新にしてもエラーが消えない場合、モデルファイル自体に起因する問題が考えられます。特にHuggingFaceやunslothなどで配布されている「自作GGUF」を使用している場合は、以下の点を確認してください。
公式版の活用
GGUFファイルは、変換ツール(convert_hf_to_gguf.py)のバージョンが古い状態で作成されると、内部のメタデータが正しく書き込まれないことがあります。エラーが解消されない場合は、自分で用意したファイルの使用を一度中断し、OllamaやLM Studioの公式ライブラリから配信されている「公式管理のgemma4」をダウンロードしてください。
特に、GGUFの変換設定や量子化手法が最新のgemma4に最適化されていない場合、実行環境を更新してもエラーが解消されないことがあります。まずはgemma4の正規の使い方を確認し、公式が推奨する手順でセットアップをやり直すのが、問題解決への最短ルートです。
自作GGUFの対応待ち
新しいモデルが発表された直後は、llama.cppの本体コードが対応していても、モデルを変換するためのスクリプト側にバグが残っていることがあります。もし自身でQuantize(量子化)を行っている場合、変換スクリプトを最新のものに更新して一から変換し直すか、対応済みの配布者がアップロードした新しいファイルを待ちましょう。
ソースビルドで先取り
macOSなどで brew install ollama や brew install llama.cpp を利用している場合、公式リポジトリの更新からパッケージマネージャー側への反映までに数日のタイムラグが生じることがあります。「今日出たばかりのモデルを今すぐ動かしたい」という場合は、パッケージ版を一度アンインストールし、前述の「ソースビルド」による導入を試みることで、最速で最新アーキテクチャを先取りできます。
また、本エラーと似た挙動として、DiffusionGemmaの読み込み失敗などのトラブルも報告されていますが、これらも根本原因は「ランタイムとモデルアーキテクチャの不整合」である場合がほとんどです。
まとめ
「unknown model architecture: 'gemma4'」というエラーは、あなたの環境が新しいAIの進化に追いつこうとしている過程で発生する、いわば「成長痛」のようなものです。
今回のポイントを整理します。
- エラーの本質: モデルの破損ではなく、実行エンジン(llama.cpp)がgemma4という新しい設計図を知らないために起きる。
- 412エラーとの違い: 通信時のエラー(412)とは異なり、ローカルでのロード時に発生する。
- 解決の第一歩: OllamaやLM Studioを最新版へアップデートする。
- 確実な方法: 自作や非公式のGGUFで詰まったら、一度公式ライブラリ提供のモデルに立ち返る。
まずは現在お使いのツールのバージョンを確認し、最新版へのアップデートを試みてください。2026年4月の新アーキテクチャであるgemma4は、正しくセットアップすれば非常に強力なパフォーマンスを発揮します。最新の実行環境を整えて、次世代LLMの可能性を最大限に引き出しましょう。
海外の最新AIニュースも、公式発表から日本語に要約してお届け。
「毎日忙しいけど、AIの最先端は知っておきたい」——そんな人のための1通です。


